


NOTÍCIAS / TECNOLOGIA AI
25 de novembro de 2020
Os consultores de call centers estão começando a ver o surgimento da NLU em seu dia a dia, ajudando-os a atender às solicitações dos clientes com mais facilidade. Para que uma ferramenta possa fazer isso, ela deve ser capaz de reconhecer ao mesmo tempo a solicitação do cliente e suas características, em outras palavras, uma intenção e entidades nomeadas.
“OK Google, toque os Rolling Stones no Spotify.”, “Alexa, como está o tempo em Paris hoje?”, “Siri, quem é o presidente francês?”.”
Se o senhor já usou assistentes vocais, indiretamente usou alguns processos de compreensão de linguagem natural (NLU). A mesma lógica se aplica aos assistentes de chatbot ou ao encaminhamento automatizado de tíquetes no atendimento ao cliente. Há algum tempo, a NLU faz parte da nossa vida cotidiana e provavelmente não vai parar por aí.
Automatizando a extração da intenção do cliente, por exemplo, a NLU pode nos ajudar a responder às solicitações de nossos clientes com mais rapidez e precisão. É por isso que toda grande empresa embarcou no desenvolvimento de sua própria solução. No entanto, com todas as bibliotecas e modelos existentes no campo da NLU, todos alegando resultados de última geração ou fáceis de obter, às vezes é complicado encontrar o caminho. Depois de experimentar várias bibliotecas em nossos projetos de NLU no Artefact, gostaríamos de compartilhar nossos resultados e ajudar os senhores a entender melhor as ferramentas atuais de NLU.
O que é NLU?
A compreensão de linguagem natural (NLU) é definida por Gartner como “a compreensão por computadores da estrutura e do significado da linguagem humana (Por exemplo., A NLU é um subdomínio do artificial intelligence que permite a interpretação de texto, analisando-o, convertendo-o em linguagem de computador e produzindo uma saída de forma compreensível para os seres humanos. Em outras palavras, a NLU é um subdomínio da artificial intelligence que permite a interpretação do texto, analisando-o, convertendo-o em linguagem de computador e produzindo uma saída em uma forma compreensível para os seres humanos.
Se o senhor observar atentamente como os chatbots e os assistentes virtuais funcionam, desde a sua solicitação até a resposta, a NLU é uma camada que extrai sua intenção principal e qualquer informação importante para a máquina, para que ela possa responder melhor à sua solicitação. Digamos que o senhor ligue para o atendimento ao cliente de sua marca favorita para saber se a bolsa dos seus sonhos está finalmente disponível em sua cidade: A NLU dirá ao assistente que o senhor tem uma solicitação de disponibilidade de produto e procurará o item específico no produto database para descobrir se ele está disponível no local desejado. Graças à NLU, extraímos uma intenção, um nome de produto e um local.

(Acima: ilustração da intenção de um cliente e várias entidades que são extraídas da conversa)
A linguagem natural está presente no data da maioria das empresas e, com os recentes avanços nesse campo, considerando a democratização dos algoritmos de NLU, o acesso a mais capacidade de computação e mais data, muitos projetos de NLU foram lançados. Vamos dar uma olhada em um deles.
Apresentação do projeto
Um projeto típico que usa NLU é, como mencionado anteriormente, ajudar os consultores de call center a responder às solicitações dos clientes com mais facilidade à medida que a conversa avança. Isso exigiria que realizássemos duas tarefas diferentes:
- Entender a intenção do cliente durante a chamada (ou seja, classificação de texto)
- Capture os elementos importantes que possibilitariam atender à solicitação do cliente (ou seja, reconhecimento de entidade nomeada), por exemplo, números de contrato, tipo de produto, cor do produto etc.
Quando examinamos pela primeira vez as soluções simples e prontas para uso lançadas para essas duas tarefas, encontramos mais de uma dúzia de estruturas, algumas desenvolvidas pelo GAFAM, outras por colaboradores de plataformas de código aberto. É impossível saber qual delas escolher para o nosso caso de uso, como cada uma delas se comporta em um projeto concreto e real data, aqui conversas de áudio de call center transcritas em texto. Por isso, decidimos compartilhar nosso benchmark de desempenho com algumas dicas, além de prós e contras de cada solução que testamos.
É importante observar que esse benchmark foi feito com o inglês data e texto de fala transcrito e, portanto, não pode ser usado como referência para outros idiomas ou aplicativos que usam diretamente texto escrito, Por exemplo. casos de uso de chatbot.
Referência
Detecção de intenção
O objetivo aqui é poder detectar o que o cliente deseja, sua intenção. Dada uma frase, o modelo deve ser capaz de classificá-la na classe certa, sendo que cada classe corresponde a uma intenção predefinida. Quando há várias classes, isso é chamado de tarefa de classificação multiclasse. Por exemplo, uma intenção pode ser “wantsToPurchaseProduct” ou “isLookingForInformation”. No nosso caso, definimos 5 intenções diferentes e as seis soluções seguintes foram usadas para o benchmark:
- FastText: biblioteca para aprendizado eficiente de representações de palavras e classificação de frases criada pelo laboratório de pesquisa de IA do Facebook.
- Ludwig: uma caixa de ferramentas que permite treinar e testar modelos de aprendizagem profunda sem a necessidade de escrever código, usando a linha de comando ou a API programática. O usuário só precisa fornecer um arquivo CSV (ou um pandas DataFrame com a API programática) contendo seu data, uma lista de colunas a serem usadas como entradas e uma lista de colunas a serem usadas como saídas, e o Ludwig fará o resto.
- Regressão logística com pré-processamento do spaCy: regressão logística clássica usando a biblioteca scikit-learn com pré-processamento personalizado usando a biblioteca spaCy (tokenização, lematização, remoção de stopwords).
- BERT com pipeline de spaCy: pipelines de modelo spaCy que envolvem o pacote de transformadores do Hugging Face para acessar facilmente arquiteturas de transformadores de última geração, como o BERT.
- LUIS: Serviço de API baseado no Microsoft cloud que aplica inteligência de aprendizado de máquina personalizada ao texto de linguagem natural e de conversação de um usuário para prever intenções e entidades.
- Flair: uma estrutura para NLP de última geração para várias tarefas, como reconhecimento de entidades nomeadas (NER), marcação de parte da fala (PoS), desambiguação de sentido e classificação.
Todos os modelos a seguir foram treinados e testados nos mesmos conjuntos data: 1.600 enunciados para treinamento e 400 para teste. Os modelos não foram ajustados, portanto, alguns deles poderiam ter desempenhos melhores do que os apresentados a seguir.
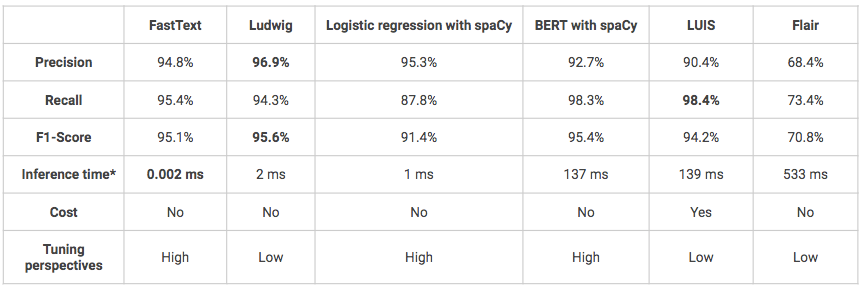
*Tempo de inferência no Macbook Air local (Intel Core i5-8 dual-core de 1,6 GHz Go 1600 MHz DDR3 RAM).
- Em geral, em termos de desempenho, todas as soluções alcançam resultados bons ou até muito bons (F1-score > 70%).
- Um dos inconvenientes do Ludwig e do LUIS é que eles são modelos muito “caixa preta”, o que os torna mais difíceis de entender e ajustar.
- O LUIS é a única solução testada que não é de código aberto e, portanto, é muito mais cara. Além disso, o uso de sua API Python pode ser complexo, pois ela foi inicialmente projetada para ser usada por meio de uma interface de botão de clique. No entanto, pode ser uma solução a ser preferida se o senhor estiver no contexto de um projeto que pretende entrar em produção e cuja infraestrutura é construída no Azure, por exemplo, pois a integração do modelo será mais fácil.
Extração de entidades
O objetivo é conseguir localizar palavras específicas e classificá-las corretamente em categorias predefinidas. Na verdade, depois de detectar o que o cliente gostaria de fazer, o senhor pode precisar encontrar mais informações na solicitação dele. Por exemplo, se um cliente quiser comprar algo, o senhor pode querer saber qual é o produto, em que cor, ou se um cliente quiser devolver um produto, o senhor pode querer saber em que data ou em que loja a compra foi feita. Em nosso caso, definimos 16 entidades personalizadasO senhor pode usar o seguinte: 9 entidades relacionadas ao produto (nome, cor, tipo, material, tamanho, etc.) e entidades adicionais relacionadas à geografia e ao tempo. Quanto à detecção de intenção, várias soluções foram usadas para fazer um benchmark:
- spaCy: uma biblioteca de código aberto para processamento avançado de linguagem natural em Python que oferece diferentes recursos, incluindo reconhecimento de entidades nomeadas.
- LUIS: veja acima
- Ludwig: veja acima
- Flair: veja acima
Todos os modelos a seguir foram treinados e testados nos mesmos conjuntos data: 1.600 enunciados para treinamento e 400 para teste. Os modelos não foram ajustados, portanto, alguns deles poderiam ter desempenhos melhores do que os apresentados a seguir.
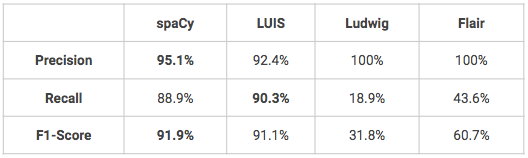
- Dois modelos têm um desempenho muito bom no reconhecimento de entidades nomeadas personalizadas, o spaCy e o LUIS. O Ludwig e o Flair precisariam de um ajuste fino para obter melhores resultados, especialmente em termos de recuperação.
- Uma vantagem do LUIS é que o usuário pode aproveitar alguns recursos avançados para o reconhecimento de entidades, como descritores que fornece dicas de que determinadas palavras e frases fazem parte de um vocabulário de domínio de entidade (por exemplo, vocabulário de cores = preto, branco, vermelho, azul, azul-marinho, verde).
Conclusão
Entre as soluções testadas em nosso call center dataset, seja para detecção de intenção ou reconhecimento de entidades, nenhuma se destaca em termos de desempenho. De acordo com nossa experiência, a escolha de uma solução em detrimento de outra deve, portanto, basear-se em sua praticidade e de acordo com seu caso de uso específico (o senhor já usa o Azure, prefere ter mais liberdade para ajustar seus modelos...). Como lembrete, usamos as bibliotecas como elas são para produzir esse benchmark, sem ajustar os modelos, portanto, os resultados exibidos devem ser considerados com uma leve retrospectiva e podem variar em um caso de uso diferente ou com mais treinamento data.

