


NIEUWS / AI TECHNOLOGIE
25 november 2020
Adviseurs van callcenters beginnen NLU in hun dagelijks leven te zien opduiken, zodat ze de verzoeken van klanten gemakkelijker kunnen beantwoorden. Om dat te kunnen doen, moet een hulpmiddel in staat zijn om tegelijkertijd het verzoek van de klant en de kenmerken ervan te herkennen, met andere woorden, een intentie en named-entities.
“OK Google, speel de Rolling Stones af op Spotify.”, “Alexa, wat voor weer is het vandaag in Parijs?”, “Siri, wie is de Franse president?”.”
Als u ooit stemassistenten hebt gebruikt, hebt u indirect enkele Natural Language Understanding (NLU) processen toegepast. Dezelfde logica geldt voor chatbotassistenten of geautomatiseerde routering van tickets in de klantenservice. NLU maakt al enige tijd deel uit van ons dagelijks leven en dat zal waarschijnlijk niet stoppen.
Door bijvoorbeeld de extractie van klantintentie te automatiseren, kan NLU ons helpen om de verzoeken van onze klanten sneller en nauwkeuriger te beantwoorden. Daarom is elk groot bedrijf begonnen met de ontwikkeling van een eigen oplossing. Maar met alle bibliotheken en modellen die er op NLU-gebied bestaan en die allemaal state-of-the-art of gemakkelijk te behalen resultaten claimen, is het soms ingewikkeld om je weg te vinden. Omdat we met verschillende bibliotheken hebben geëxperimenteerd in onze NLU-projecten op Artefact, wilden we onze resultaten delen en u helpen een beter inzicht te krijgen in de huidige NLU-tools.
Wat is NLU?
Natural Language Understanding (NLU) wordt gedefinieerd door Gartner als “het begrijpen door computers van de structuur en betekenis van menselijke taal (bijv., Engels, Spaans, Japans), waardoor gebruikers met de computer kunnen communiceren door middel van natuurlijke zinnen”. Met andere woorden, NLU is een subdomein van artificial intelligence dat de interpretatie van tekst mogelijk maakt door deze te analyseren, om te zetten in computertaal en een uitvoer te produceren in een voor mensen begrijpelijke vorm.
Als u goed kijkt naar hoe chatbots en virtuele assistenten werken, van uw verzoek tot hun antwoord, is NLU één laag die uw hoofdintentie en alle informatie die belangrijk is voor de machine eruit haalt, zodat deze uw verzoek het beste kan beantwoorden. Stel dat u de klantenservice van uw favoriete merk belt om te weten of uw droomtas eindelijk beschikbaar is in uw stad: NLU zal de assistent vertellen dat u een productbeschikbaarheidsverzoek hebt en het specifieke item opzoeken in de product database om uit te zoeken of het beschikbaar is op de door u gewenste locatie. Dankzij NLU hebben we een intentie, een productnaam en een locatie geëxtraheerd.

(Hierboven: illustratie van een klantintentie en verschillende entiteiten die uit conversatie worden gehaald)
Natuurlijke taal zit ingebakken in de data van de meeste bedrijven en met de recente doorbraken op dit gebied, gezien de democratisering van de NLU-algoritmen, de toegang tot meer rekenkracht & meer data, zijn er veel NLU-projecten gestart. Laten we er één bekijken.
Projectpresentatie
Een typisch project waarbij NLU wordt gebruikt is, zoals eerder vermeld, het helpen van callcenteradviseurs bij het beantwoorden van verzoeken van klanten terwijl het gesprek vordert. Hiervoor zouden we twee verschillende taken moeten uitvoeren:
- De bedoeling van de klant begrijpen tijdens het gesprek (d.w.z. tekstclassificatie)
- Vang de belangrijke elementen waarmee het verzoek van de klant beantwoord kan worden (d.w.z. named-entity recognition), bijvoorbeeld contractnummers, producttype, productkleur, enz.
Toen we voor het eerst keken naar de eenvoudige en kant-en-klare oplossingen die voor deze twee taken zijn uitgebracht, vonden we meer dan een dozijn frameworks, sommige ontwikkeld door GAFAM, sommige door open-source platformmedewerkers. Onmogelijk om te weten welke te kiezen voor onze use case, hoe elk van hen presteert op een concreet project en echte data, hier callcenter audiogesprekken omgezet in tekst. Daarom hebben we besloten om onze prestatiebenchmark te delen met enkele tips en voor- en nadelen voor elke oplossing die we hebben getest.
Het is belangrijk om op te merken dat deze benchmark gedaan is met Engelse data en getranscribeerde spraaktekst en daarom minder gebruikt kan worden als referentie voor andere talen of toepassingen die direct geschreven tekst gebruiken, bijv. chatbot-gebruiksgevallen.
Benchmark
Opsporing van intenties
Het doel is hier om te kunnen detecteren wat de klant wil, zijn/haar intentie. Als een zin wordt gegeven, moet het model deze in de juiste klasse kunnen indelen, waarbij elke klasse overeenkomt met een vooraf gedefinieerde bedoeling. Als er meerdere klassen zijn, wordt dit een multiklasse classificatietaak genoemd. Een intentie kan bijvoorbeeld zijn “wilProduct kopen” of “zoektInformatie”. In ons geval hadden we het volgende gedefinieerd 5 verschillende intenties en de zes volgende oplossingen werden gebruikt voor de benchmark:
- FastText: bibliotheek voor het efficiënt leren van woordrepresentaties en zinsclassificatie, gemaakt door Facebooks AI Research lab.
- Ludwig: een toolbox waarmee deep learning-modellen kunnen worden getraind en getest zonder dat er code geschreven hoeft te worden, via de opdrachtregel of de programmatische API. De gebruiker hoeft alleen maar een CSV-bestand aan te leveren (of een pandas DataFrame met de programmatische API) met daarin zijn/haar data, een lijst met kolommen die als invoer gebruikt moeten worden en een lijst met kolommen die als uitvoer gebruikt moeten worden, Ludwig doet de rest.
- Logistische regressie met spaCy preprocessing: klassieke logistische regressie met behulp van de scikit-learn bibliotheek met aangepaste voorbewerking met behulp van de spaCy bibliotheek (tokeniseren, lemmatiseren, stopwoorden verwijderen).
- BERT met spaCy pijplijn: spaCy modelpijplijnen die Hugging Face's transformatorenpakket omsluiten om gemakkelijk toegang te krijgen tot geavanceerde transformatorarchitecturen zoals BERT.
- LUIS: API-service op basis van Microsoft cloud die machine-learning toepast op de conversatietekst in natuurlijke taal van een gebruiker om de intentie en entiteiten te voorspellen..
- Flair: een raamwerk voor geavanceerde NLP voor verschillende taken, zoals named entity recognition (NER), part-of-speech tagging (PoS), zinsontleding en classificatie.
De volgende modellen zijn allemaal getraind en getest op dezelfde datasets: 1600 uitingen voor training, 400 voor testen. De modellen zijn niet verfijnd, dus sommige modellen zouden mogelijk betere prestaties kunnen leveren dan wat hieronder wordt gepresenteerd.
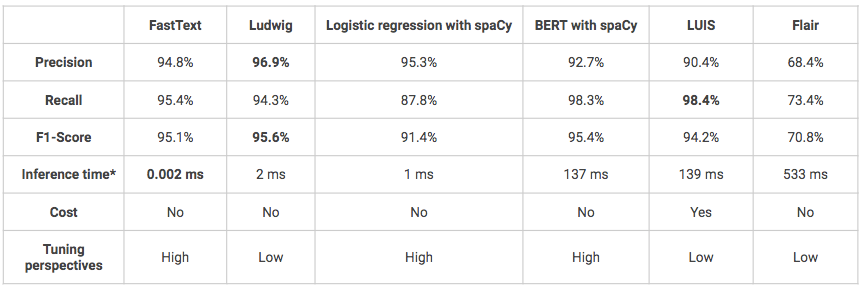
*Inferentietijd op lokale Macbook Air (1,6 GHz dual-core Intel Core i5-8 Go 1600 MHz DDR3 RAM).
- In het algemeen behalen alle oplossingen goede of zelfs zeer goede resultaten (F1-score > 70%).
- Een van de ongemakken van Ludwig en LUIS is dat het erg “black-box” modellen zijn, waardoor ze moeilijker te begrijpen en af te stellen zijn.
- LUIS is de enige geteste oplossing die niet open source is en dus veel duurder. Bovendien kan het gebruik van de Python API complex zijn, omdat het oorspronkelijk ontworpen is voor gebruik via een klik-knop interface. Het kan echter een oplossing zijn die de voorkeur verdient als u zich in de context van een project bevindt dat in productie moet gaan en waarvan de infrastructuur bijvoorbeeld op Azure is gebouwd, de integratie van het model zal dan gemakkelijker zijn.
Entiteiten extractie
Het doel is om specifieke woorden te kunnen vinden en ze correct in te delen in vooraf gedefinieerde categorieën. Nadat u hebt gedetecteerd wat uw klant wil doen, kan het zijn dat u meer informatie in zijn/haar verzoek moet vinden. Als een klant bijvoorbeeld iets wil kopen, wilt u misschien weten welk product het is, in welke kleur, of als een klant een product wil retourneren, wilt u misschien weten op welke datum of in welke winkel de aankoop is gedaan. In ons geval hadden we het volgende gedefinieerd 16 aangepaste entiteiten9 productgerelateerde entiteiten (naam, kleur, type, materiaal, grootte, ...) en extra entiteiten met betrekking tot geografie en tijd. Voor intentiedetectie zijn verschillende oplossingen gebruikt om een benchmark te maken:
- spaCy: een open-source bibliotheek voor geavanceerde verwerking van natuurlijke taal in Python die verschillende functies biedt, waaronder Named Entity Recognition (herkenning van namen).
- LUIS: zie boven
- Ludwig: zie boven
- Flair: zie boven
De volgende modellen zijn allemaal getraind en getest op dezelfde datasets: 1600 uitingen voor training, 400 voor testen. De modellen zijn niet verfijnd, dus sommige modellen zouden mogelijk betere prestaties kunnen leveren dan wat hieronder wordt gepresenteerd.
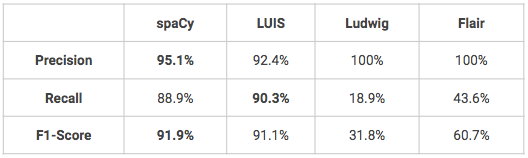
- Twee modellen presteren erg goed op het gebied van herkenning van aangepaste naamentiteiten, spaCy en LUIS. Ludwig en Flair zouden wat verfijning nodig hebben om betere resultaten te behalen, vooral in termen van terughalen.
- Een voordeel van LUIS is dat de gebruiker een aantal geavanceerde functies voor entiteitherkenning kan gebruiken, zoals descriptoren die hints geeft dat bepaalde woorden en zinnen deel uitmaken van een entiteitdomeinwoordenschat (bijv.: kleurenwoordenschat = zwart, wit, rood, blauw, marineblauw, groen).
Conclusie
Van de oplossingen die getest zijn op onze callcenter dataset, of het nu gaat om intentiedetectie of entiteitherkenning, springt er geen enkele uit qua prestaties. Onze ervaring is dat de keuze voor de ene oplossing boven de andere gebaseerd moet zijn op hun praktische bruikbaarheid en op uw specifieke gebruikssituatie (gebruikt u Azure al, hebt u liever meer vrijheid om uw modellen te verfijnen...). Ter herinnering: we hebben de bibliotheken gewoon genomen zoals ze zijn om deze benchmark te produceren, zonder de modellen te verfijnen, dus de weergegeven resultaten moeten met een kleine terugblik worden bekeken en zouden kunnen variëren bij een andere use case of met meer training data.

