


NOTICIAS / TECNOLOGÍA AI
25 de noviembre de 2020
Los asesores de los centros de atención telefónica están empezando a ver cómo el NLU aparece en su día a día, ayudándoles a responder más fácilmente a las solicitudes de los clientes. Para ello, una herramienta debe ser capaz de reconocer al mismo tiempo la solicitud del cliente y sus características, es decir, una intención y unas entidades con nombre.
“OK Google, pon los Rolling Stones en Spotify”, “Alexa, ¿qué tiempo hace hoy en París?”, “Siri, ¿quién es el presidente francés?”.”
Si alguna vez ha utilizado asistentes vocales, indirectamente habrá utilizado algunos procesos de comprensión del lenguaje natural (NLU). La misma lógica se aplica a los asistentes de chatbot o al enrutamiento automatizado de tickets en los servicios de atención al cliente. Desde hace algún tiempo, el NLU forma parte de nuestra vida cotidiana y probablemente no vaya a dejar de hacerlo.
Automatizando la extracción de la intención del cliente, por ejemplo, NLU puede ayudarnos a responder a las solicitudes de nuestros clientes con mayor rapidez y precisión. Por eso todas las grandes empresas se han embarcado en el desarrollo de su propia solución. Sin embargo, con todas las bibliotecas y modelos que existen en el campo del NLU, todos ellos reivindicando resultados punteros o fáciles de obtener, a veces resulta complicado orientarse. Tras haber experimentado con varias bibliotecas en nuestros proyectos de NLU en Artefact, queríamos compartir nuestros resultados y ayudarle a conocer mejor las herramientas actuales en NLU.
¿Qué es NLU ?
La comprensión del lenguaje natural (NLU) se define por Gartner como “la comprensión por parte de los ordenadores de la estructura y el significado del lenguaje humano (Por ejemplo., inglés, español, japonés), que permite a los usuarios interactuar con el ordenador utilizando frases naturales”. En otras palabras, NLU es un subdominio de artificial intelligence que permite interpretar textos analizándolos, convirtiéndolos en lenguaje informático y produciendo una salida de forma comprensible para los humanos.
Si observa detenidamente cómo funcionan los chatbots y los asistentes virtuales, desde su solicitud hasta su respuesta, NLU es una capa que extrae su intención principal y cualquier información importante para la máquina, de forma que pueda responder mejor a su solicitud. Pongamos que llama al servicio de atención al cliente de su marca favorita para saber si el bolso de sus sueños está por fin disponible en su ciudad: NLU le dirá al asistente que tiene una solicitud de disponibilidad de producto y buscará el artículo concreto en la base de datos database de productos para averiguar si está disponible en el lugar que desea. Gracias a NLU, hemos extraído una intención, un nombre de producto y una ubicación.

(Arriba: llustración de la intención de un cliente y varias entidades que se extraen de la conversación)
El lenguaje natural está inculcado en el data de la mayoría de las empresas y, con los recientes avances en este campo, teniendo en cuenta la democratización de los algoritmos NLU, el acceso a más potencia informática y más data, se han puesto en marcha numerosos proyectos NLU. Veamos uno de ellos.
Presentación del proyecto
Un proyecto típico en el que se utiliza NLU es, como ya se ha mencionado, ayudar a los asesores de los centros de llamadas a responder a las peticiones de los clientes con mayor facilidad a medida que avanza la conversación. Para ello tendríamos que realizar dos tareas diferentes:
- Comprender la intención del cliente durante la llamada (es decir, clasificación de textos)
- Capte los elementos importantes que permitan responder a la solicitud del cliente (es decir, el reconocimiento de entidades con nombre), por ejemplo, números de contrato, tipo de producto, color del producto, etc.
Cuando examinamos por primera vez las soluciones sencillas y disponibles en el mercado para estas dos tareas, pudimos encontrar más de una docena de marcos de trabajo, algunos desarrollados por GAFAM y otros por colaboradores de plataformas de código abierto. Imposible saber cuál elegir para nuestro caso de uso, cómo se comporta cada uno de ellos en un proyecto concreto y real data, aquí conversaciones de audio de centros de llamadas transcritas a texto. Por eso hemos decidido compartir nuestra comparativa de rendimiento con algunos consejos, así como los pros y los contras de cada una de las soluciones que hemos probado.
Es importante señalar que este punto de referencia se ha realizado con el inglés data y texto hablado transcrito, por lo que no puede utilizarse tanto como referencia para otros idiomas o aplicaciones que utilicen directamente texto escrito, Por ejemplo. casos de uso de chatbot.
Punto de referencia
Detección de intenciones
El objetivo aquí es poder detectar lo que quiere el cliente, su intención. Dada una frase, el modelo tiene que ser capaz de clasificarla en la clase adecuada, correspondiendo cada clase a una intención predefinida. Cuando hay varias clases, se denomina tarea de clasificación multiclase. Por ejemplo, una intención puede ser “quiereComprarProducto” o “estáBuscandoInformación”. En nuestro caso, habíamos definido 5 intenciones diferentes y se utilizaron las seis soluciones siguientes para la evaluación comparativa:
- FastText: biblioteca para el aprendizaje eficaz de representaciones de palabras y clasificación de frases creada por el laboratorio de Investigación de IA de Facebook.
- Ludwig: una caja de herramientas que permite entrenar y probar modelos de aprendizaje profundo sin necesidad de escribir código, utilizando la línea de comandos o la API programática. El usuario sólo tiene que proporcionar un archivo CSV (o un pandas DataFrame con la API programática) que contenga su data, una lista de columnas para utilizar como entradas, y una lista de columnas para utilizar como salidas, Ludwig hará el resto.
- Regresión logística con preprocesamiento del spaCio: regresión logística clásica mediante la biblioteca scikit-learn con preprocesamiento personalizado mediante la biblioteca spaCy (tokenización, lematización, eliminación de stopwords).
- BERT con tubería spaCy: Canalizaciones de modelos spaCy que envuelven el paquete de transformadores Hugging Face para acceder fácilmente a arquitecturas de transformadores de última generación como BERT.
- LUIS: Servicio API basado en Microsoft cloud que aplica inteligencia de aprendizaje automático personalizada al texto conversacional en lenguaje natural de un usuario para predecir la intención y las entidades.
- Flair: un marco de PNL de última generación para varias tareas como el reconocimiento de entidades con nombre (NER), el etiquetado de partes del habla (PoS), la desambiguación de sentidos y la clasificación.
Todos los modelos siguientes se han entrenado y probado con los mismos conjuntos data: 1600 enunciados para el entrenamiento y 400 para las pruebas. Los modelos no se han afinado, por lo que algunos de ellos podrían tener mejores resultados que los que se presentan a continuación.
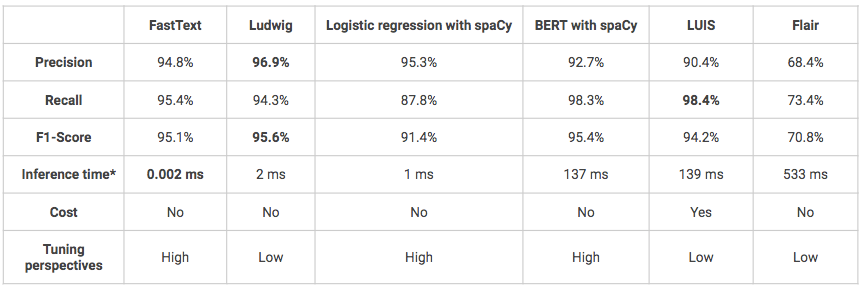
*Tiempo de inferencia en el Macbook Air local (Intel Core i5-8 de doble núcleo a 1,6 GHz Go 1600 MHz de RAM DDR3).
- En general, en términos de rendimiento, todas las soluciones obtienen resultados buenos o incluso muy buenos (puntuación F1 > 70%).
- Uno de los inconvenientes de Ludwig y LUIS es que son modelos muy de “caja negra”, lo que dificulta su comprensión y puesta a punto.
- LUIS es la única solución probada que no es de código abierto, por lo que es mucho más cara. Además, el uso de su API Python puede resultar complejo, ya que ha sido diseñado inicialmente para ser utilizado a través de una interfaz de botones. Sin embargo, puede ser una solución a preferir si se encuentra en el contexto de un proyecto que pretende entrar en producción y cuya infraestructura está construida sobre Azure por ejemplo, la integración del modelo será entonces más fácil.
Extracción de entidades
El objetivo es poder localizar palabras concretas y clasificarlas correctamente en categorías predefinidas. De hecho, una vez que haya detectado lo que su cliente desea hacer, puede que necesite encontrar más información en su solicitud. Por ejemplo, si un cliente quiere comprar algo puede que usted quiera saber de qué producto se trata, en qué color o si un cliente quiere devolver un producto, puede que usted quiera saber en qué fecha o en qué tienda se realizó la compra. En nuestro caso, habíamos definido 16 entidades personalizadas: 9 entidades relacionadas con el producto (nombre, color, tipo, material, tamaño, ...) y entidades adicionales relacionadas con la geografía y el tiempo. En cuanto a la detección de intenciones, se han utilizado varias soluciones para realizar un análisis comparativo:
- spaCia: una biblioteca de código abierto para el Procesamiento Avanzado del Lenguaje Natural en Python que proporciona diferentes funciones, entre ellas el Reconocimiento de Entidades Nombradas.
- LUIS: véase más arriba
- Ludwig: véase más arriba
- Flair: véase más arriba
Todos los modelos siguientes se han entrenado y probado con los mismos conjuntos data: 1600 enunciados para el entrenamiento y 400 para las pruebas. Los modelos no se han afinado, por lo que algunos de ellos podrían tener mejores resultados que los que se presentan a continuación.
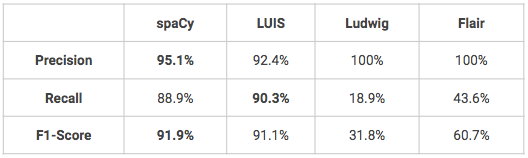
- Dos modelos obtienen muy buenos resultados en el reconocimiento personalizado de entidades con nombre, spaCy y LUIS. Ludwig y Flair requerirían algunos ajustes para obtener mejores resultados, especialmente en términos de recuerdo.
- Una ventaja de LUIS es que el usuario puede aprovechar algunas características avanzadas para el reconocimiento de entidades, tales como descriptores que proporciona indicios de que ciertas palabras y frases forman parte de un vocabulario del dominio de la entidad (por ejemplo: vocabulario del color = negro, blanco, rojo, azul, azul marino, verde).
Conclusión
Entre las soluciones probadas en nuestro centro de llamadas dataset, ya sea para la detección de intenciones o para el reconocimiento de entidades, ninguna destaca en términos de rendimiento. Según nuestra experiencia, la elección de una solución sobre otra debe basarse, por tanto, en su practicidad y en función de su caso de uso específico (si ya utiliza Azure, si prefiere tener más libertad para afinar sus modelos...). Como recordatorio, nos limitamos a tomar las bibliotecas tal cual para producir este benchmark, sin afinar los modelos, por lo que los resultados mostrados deben tomarse con una ligera retrospectiva y podrían variar en un caso de uso diferente o con más entrenamiento data.

