


新闻 / 人工智能技术
2020 年 11 月 25 日
呼叫中心顾问在日常工作中已经开始使用 NLU,以帮助他们更轻松地回答客户的请求。要做到这一点,工具必须能够同时识别客户请求及其特征,换句话说,就是识别意图和命名实体。.
“OK谷歌,在Spotify上播放滚石乐队的歌曲”,“Alexa,今天巴黎的天气如何?”,“Siri,法国总统是谁?”
如果您曾经使用过语音助手,那么您就间接使用过一些自然语言理解(NLU)流程。同样的道理也适用于聊天机器人助手或客户服务中的自动路由单。一段时间以来,NLU 已经成为我们日常生活的一部分,而且可能不会停止。.
例如,通过自动提取客户意图,NLU 可以帮助我们更快、更准确地回答客户的要求。这就是为什么每家大公司都着手开发自己的解决方案。然而,NLU 领域现有的各种库和模型,都声称具有最先进的技术或很容易获得结果,要找到自己的方向有时很复杂。我们在 Artefact 的无损检测项目中试用了各种库,希望与大家分享我们的成果,帮助大家更好地了解无损检测领域的现有工具。.
什么是 NLU?
自然语言理解(NLU)的定义是 Gartner 是指 “计算机对人类语言的结构和意义的理解(......)"。例如., 它允许用户使用自然句子与计算机进行交互”。换句话说,NLU 是 artificial intelligence 的一个子域,通过分析文本、将其转换为计算机语言并以人类可理解的形式输出,实现对文本的解释。.
如果您仔细研究一下聊天机器人和虚拟助手是如何工作的,从您的请求到它们的回答,NLU 是一层提取您的主要意图和对机器重要的任何信息,以便它能最好地回答您的请求。比方说,您致电最喜欢的品牌客服,想知道您梦想中的包包在您所在的城市是否有货:NLU 会告诉客服助理您有一个产品可用性请求,并在产品 database 中查找该特定产品,以了解它是否在您想要的地点有售。多亏了 NLU,我们才提取出了一个意图、一个产品名称和一个地点。.

(上图:客户意图和从对话中提取的多个实体的示意图)
自然语言已融入大多数公司的 data 中,随着这一领域最近取得的突破,考虑到自然语言理解算法的民主化、获得更多计算能力和更多 data 的机会,许多自然语言理解项目已经启动。让我们来看看其中的一个。.
项目介绍
如前所述,使用 NLU 的一个典型项目是帮助呼叫中心顾问在对话过程中更轻松地回答客户的请求。这需要我们执行两项不同的任务:
- 了解客户的意图 通话期间(即文本分类)
- 抓住重要因素 例如合同编号、产品类型、产品颜色等。.
当我们第一次查看针对这两项任务发布的简单现成的解决方案时,我们发现有十几个框架,有些是由 GAFAM 开发的,有些是由开源平台贡献者开发的。我们不可能知道该为我们的用例选择哪一个,也不可能知道它们中的每一个在具体项目和真实的 data(这里是转录为文本的呼叫中心音频对话)上的表现如何。因此,我们决定分享我们的性能基准,其中包括一些提示以及我们测试过的每种解决方案的优点和缺点。.
值得注意的是,该基准测试是使用英语 data 和转录语音文本完成的,因此对于其他语言或直接使用书面文本的应用而言,其参考意义较小、, 例如. 聊天机器人使用案例。.
基准
意图检测
这里的目标是能够检测出客户想要什么,也就是他/她的意图。给定一个句子,模型必须能够将其归入正确的类别,每个类别对应一个预定义的意图。如果有多个类别,则称为多类别分类任务。例如,意图可以是 “wantsToPurchaseProduct ”或 “isLookingForInformation”。在我们的案例中,我们定义了 5 种不同的意图 和以下六个解决方案被用于基准测试:
- 快速文本: 该库由 Facebook 人工智能研究实验室创建,用于高效学习单词表述和句子分类。.
- 路德维希: 是一个无需编写代码就能使用命令行或编程 API 训练和测试深度学习模型的工具箱。用户只需提供一个 CSV 文件(或使用编程 API 的 pandas DataFrame),其中包含他/她的 data、用作输入的列列表以及用作输出的列列表,路德维格就会完成剩下的工作。.
- 逻辑回归 水质预处理: 使用 scikit-learn 库进行经典逻辑回归,并使用 spaCy 库进行自定义预处理(标记化、词法化、删除停止词)。.
- 带水疗管道的 BERT: spaCy 模型管道包含 Hugging Face 的变压器软件包,可轻松访问 BERT 等最先进的变压器架构。.
- 路易斯: 基于 Microsoft cloud 的应用程序接口服务可将定制的机器学习智能应用于用户的会话、自然语言文本,以预测意图和实体.
- 弗莱尔: 是一个用于命名实体识别(NER)、语音部分标记(PoS)、意义消歧和分类等多项任务的先进 NLP 框架。.
以下模型均在相同的 datasets 上进行了训练和测试:1600 个语料用于训练,400 个用于测试。模型尚未经过微调,因此其中一些模型的性能可能会比下面介绍的更好。.
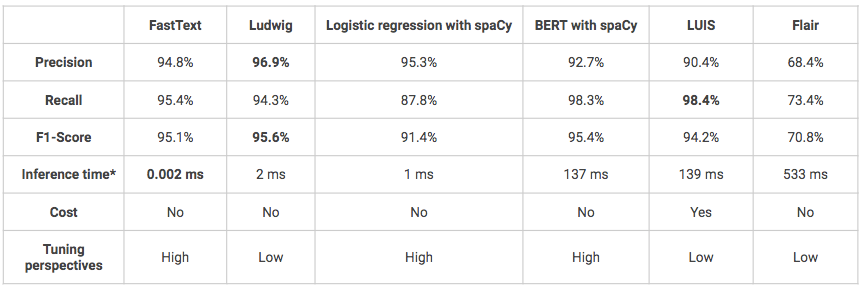
*本地 Macbook Air(1.6GHz 双核英特尔酷睿 i5-8 Go 1600 MHz DDR3 内存)的推理时间。.
- 总体而言,就性能而言,所有解决方案都取得了良好甚至非常好的结果(F1 分数大于 70%)。.
- 路德维格模型和路易斯模型的一个不便之处是,它们是非常 “黑箱 ”的模型,因此更难理解和微调。.
- LUIS 是测试过的唯一一个非开源解决方案,因此价格要贵得多。此外,其 Python API 的使用可能比较复杂,因为它最初是设计为通过点击按钮界面使用的。不过,如果您的项目以投入生产为目标,并且其基础架构建立在 Azure 等平台上,那么它可能是您的首选解决方案,因为这样模型的集成会更容易。.
实体提取
我们的目标是能够找到特定的词语,并将其正确归入预定义的类别。事实上,当您检测到客户想要做什么时,您可能需要在他/她的请求中找到更多信息。例如,如果客户想买东西,您可能想知道是哪种产品、哪种颜色;如果客户想退货,您可能想知道是在哪一天或哪家商店购买的。在我们的案例中,我们定义了 16 个自定义实体包括 9 个与产品相关的实体(名称、颜色、类型、材料、尺寸......)以及与地理和时间相关的附加实体。在意图检测方面,我们使用了几种解决方案作为基准:
- 水疗: 是一个用于 Python 高级自然语言处理的开源库,提供包括命名实体识别在内的各种功能。.
- 路易斯: 见上文
- 路德维希 见上文
- 弗莱尔 见上文
以下模型均在相同的 datasets 上进行了训练和测试:1600 个语料用于训练,400 个用于测试。模型尚未经过微调,因此其中一些模型的性能可能会比下面介绍的更好。.
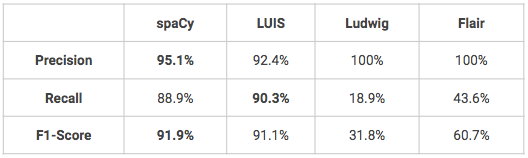
- 有两个模型在自定义命名实体识别方面表现非常出色,它们是 spaCy 和 LUIS。Ludwig 和 Flair 需要进行一些微调才能获得更好的结果,尤其是在召回率方面。.
- LUIS 的一个优势是用户可以利用一些高级功能进行实体识别,例如 描述符 提示某些单词和短语是实体领域词汇的一部分(例如:颜色词汇 = 黑色、白色、红色、蓝色、海军蓝、绿色)。.
结论
在我们的呼叫中心 dataset 上测试的解决方案中,无论是意图检测还是实体识别,没有一个在性能方面表现突出。根据我们的经验,选择一种解决方案还是另一种解决方案,应根据其实用性和您的具体使用情况而定(您是否已经使用 Azure,您是否更喜欢自由微调模型......)。需要提醒的是,我们只是将库原封不动地用于生成此基准,而没有对模型进行微调,因此显示的结果只是事后才看到的,在不同的使用情况下或经过更多的训练 data 后可能会有所不同。.


