


NACHRICHTEN / KI-TECHNOLOGIE
25. November 2020
Die Berater in Call Centern sehen allmählich, wie NLU in ihrem Alltag Einzug hält und ihnen hilft, Kundenanfragen leichter zu beantworten. Damit ein Tool dies leisten kann, muss es in der Lage sein, gleichzeitig die Kundenanfrage und ihre Merkmale zu erkennen, d.h. eine Absicht und benannte Entitäten.
“OK Google, spiel die Rolling Stones auf Spotify”, “Alexa, wie ist das Wetter in Paris heute?”, “Siri, wer ist der französische Präsident?”
Wenn Sie schon einmal Sprachassistenten verwendet haben, haben Sie indirekt einige Prozesse des Natural Language Understanding (NLU) genutzt. Die gleiche Logik gilt für Chatbot-Assistenten oder die automatische Weiterleitung von Tickets im Kundenservice. NLU gehört schon seit einiger Zeit zu unserem Alltag und wird wahrscheinlich auch nicht mehr aufhören.
Durch die Automatisierung der Extraktion von Kundenabsichten zum Beispiel kann NLU uns dabei helfen, die Anfragen unserer Kunden schneller und genauer zu beantworten. Aus diesem Grund hat jedes große Unternehmen mit der Entwicklung einer eigenen Lösung begonnen. Bei all den Bibliotheken und Modellen, die es im Bereich NLU gibt und die alle den Anspruch erheben, auf dem neuesten Stand der Technik zu sein oder leicht zu erhaltende Ergebnisse zu liefern, ist es jedoch manchmal kompliziert, sich zurechtzufinden. Nachdem wir in unseren NLU-Projekten bei Artefact mit verschiedenen Bibliotheken experimentiert haben, wollten wir unsere Ergebnisse mit Ihnen teilen und Ihnen helfen, die aktuellen Tools im Bereich NLU besser zu verstehen.
Was ist NLU?
Natürliches Sprachverstehen (NLU) wird definiert durch Gartner als “das Verstehen der Struktur und Bedeutung der menschlichen Sprache durch Computer (z.B.., Englisch, Spanisch, Japanisch), die es dem Benutzer ermöglichen, mit dem Computer in natürlichen Sätzen zu interagieren”. Mit anderen Worten: NLU ist ein Teilbereich von artificial intelligence, der die Interpretation von Text ermöglicht, indem er ihn analysiert, in Computersprache umwandelt und in einer für Menschen verständlichen Form ausgibt.
Wenn Sie sich genau ansehen, wie Chatbots und virtuelle Assistenten arbeiten, von Ihrer Anfrage bis zu ihrer Antwort, ist NLU eine Schicht, die Ihre Hauptabsicht und alle für die Maschine wichtigen Informationen extrahiert, damit sie Ihre Anfrage am besten beantworten kann. Angenommen, Sie rufen den Kundendienst Ihrer Lieblingsmarke an, um zu erfahren, ob Ihre Traumtasche endlich in Ihrer Stadt erhältlich ist: NLU wird dem Assistenten mitteilen, dass Sie eine Anfrage zur Produktverfügbarkeit haben und in der Produkt database nach dem bestimmten Artikel suchen, um herauszufinden, ob er an Ihrem Wunschort verfügbar ist. Dank NLU haben wir eine Absicht, einen Produktnamen und einen Ort extrahiert.

(Oben: Illustration einer Kundenabsicht und mehrere Entitäten, die aus der Konversation extrahiert werden)
Natürliche Sprache ist im data der meisten Unternehmen verankert. Mit den jüngsten Durchbrüchen auf diesem Gebiet, der Demokratisierung der NLU-Algorithmen, dem Zugang zu mehr Rechenleistung und mehr data wurden viele NLU-Projekte ins Leben gerufen. Werfen wir einen Blick auf eines von ihnen.
Präsentation des Projekts
Ein typisches Projekt, bei dem NLU zum Einsatz kommt, ist, wie bereits erwähnt, die Unterstützung von Callcenter-Beratern bei der Beantwortung von Kundenanfragen im Verlauf des Gesprächs. Dazu müssten wir zwei verschiedene Aufgaben erfüllen:
- Verstehen Sie die Absicht des Kunden während des Anrufs (d.h. Textklassifizierung)
- Fangen Sie die wichtigen Elemente ein die es ermöglichen würden, die Anfrage des Kunden zu beantworten (d.h. Named-Entity-Erkennung), z.B. Vertragsnummern, Produkttyp, Produktfarbe, usw.
Als wir uns die einfachen und standardmäßigen Lösungen für diese beiden Aufgaben ansahen, fanden wir mehr als ein Dutzend Frameworks, einige von der GAFAM entwickelt, andere von Open-Source-Plattformanbietern. Es ist unmöglich zu wissen, welches wir für unseren Anwendungsfall auswählen sollen und wie sich jedes von ihnen bei einem konkreten Projekt und echten data, hier in Text umgewandelte Audiogespräche eines Call Centers, verhält. Deshalb haben wir beschlossen, unseren Leistungsvergleich mit einigen Tipps sowie Vor- und Nachteilen für jede von uns getestete Lösung zu teilen.
Es ist wichtig zu beachten, dass dieser Benchmark mit englischem data und transkribiertem Sprachtext durchgeführt wurde und daher weniger als Referenz für andere Sprachen oder Anwendungen, die direkt geschriebenen Text verwenden, verwendet werden kann, z.B.. Chatbot-Anwendungsfälle.
Benchmark
Erkennung von Absichten
Das Ziel ist es, zu erkennen, was der Kunde will, seine Absicht. Bei einem Satz muss das Modell in der Lage sein, ihn in die richtige Klasse einzuordnen, wobei jede Klasse einer vordefinierten Absicht entspricht. Wenn es mehrere Klassen gibt, spricht man von einer Mehrklassen-Klassifizierungsaufgabe. Eine Absicht kann zum Beispiel “möchte ein Produkt kaufen” oder “sucht nach Informationen” sein. In unserem Fall hatten wir definiert 5 verschiedene Absichten und die sechs folgenden Lösungen wurden für den Benchmark verwendet:
- FastText: Bibliothek für effizientes Lernen von Wortrepräsentationen und Satzklassifizierung, die vom KI-Forschungslabor von Facebook entwickelt wurde.
- Ludwig: eine Toolbox, mit der Sie Deep-Learning-Modelle trainieren und testen können, ohne Code schreiben zu müssen, entweder über die Kommandozeile oder die programmatische API. Der Benutzer muss lediglich eine CSV-Datei (oder einen Pandas DataFrame mit der programmatischen API) bereitstellen, die seine data, eine Liste von Spalten, die als Eingaben verwendet werden sollen, und eine Liste von Spalten, die als Ausgaben verwendet werden sollen, enthält.
- Logistische Regression mit spaCy-vorverarBeitunG: klassische logistische Regression unter Verwendung der Scikit-Learn-Bibliothek mit benutzerdefinierter Vorverarbeitung unter Verwendung der SpaCy-Bibliothek (Tokenisierung, Lemmatisierung, Entfernen von Stoppwörtern).
- BERT mit SpaCy-Pipeline: spaCy-Modellpipelines, die das Transformatorenpaket von Hugging Face umschließen, um auf modernste Transformatorenarchitekturen wie BERT zuzugreifen.
- LUIS: Microsoft cloud-basierter API-Dienst, der benutzerdefinierte maschinelle Lernintelligenz auf den natürlichsprachlichen Konversationstext eines Benutzers anwendet, um Absichten und Entitäten vorherzusagen.
- Flair: ein Framework für modernste NLP für verschiedene Aufgaben wie Named Entity Recognition (NER), Part-of-Speech Tagging (PoS), Sense Disambiguation und Klassifizierung.
Die folgenden Modelle wurden alle mit denselben data-Sätzen trainiert und getestet: 1600 Äußerungen zum Training, 400 zum Testen. Die Modelle wurden nicht feinabgestimmt, so dass einige von ihnen möglicherweise eine bessere Leistung erbringen als die unten dargestellten.
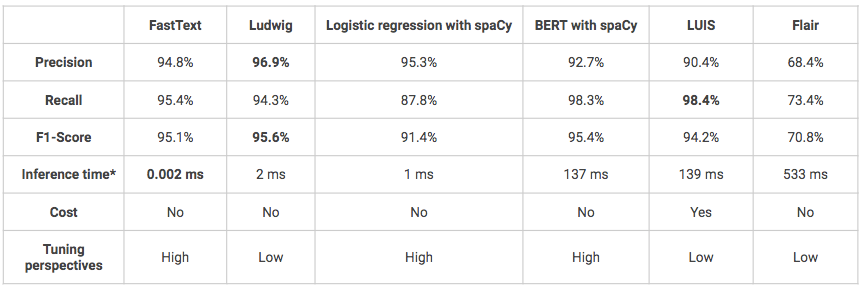
*Inferenzzeit auf dem lokalen Macbook Air (1,6 GHz Dual-Core Intel Core i5-8 Go 1600 MHz DDR3 RAM).
- Insgesamt erzielen alle Lösungen gute oder sogar sehr gute Ergebnisse (F1-Score > 70%).
- Einer der Nachteile von Ludwig und LUIS ist, dass es sich um “Blackbox”-Modelle handelt, die das Verständnis und die Feinabstimmung erschweren.
- LUIS ist die einzige getestete Lösung, die nicht quelloffen ist und daher wesentlich teurer ist. Außerdem kann die Verwendung seiner Python-API komplex sein, da es ursprünglich für die Verwendung über eine Klick-Button-Schnittstelle konzipiert wurde. Es kann jedoch eine Lösung sein, die zu bevorzugen ist, wenn Sie sich im Rahmen eines Projekts befinden, das in die Produktion gehen soll und dessen Infrastruktur beispielsweise auf Azure aufgebaut ist, da die Integration des Modells dann einfacher ist.
Extraktion von Entitäten
Das Ziel ist es, bestimmte Wörter zu finden und sie korrekt in vordefinierte Kategorien einzuordnen. Denn wenn Sie erst einmal herausgefunden haben, was Ihr Kunde tun möchte, müssen Sie möglicherweise weitere Informationen in seiner Anfrage finden. Wenn ein Kunde zum Beispiel etwas kaufen möchte, möchten Sie vielleicht wissen, um welches Produkt es sich handelt, in welcher Farbe oder wenn ein Kunde ein Produkt zurückgeben möchte, möchten Sie vielleicht wissen, zu welchem Datum oder in welchem Geschäft der Kauf getätigt wurde. In unserem Fall hatten wir definiert 16 benutzerdefinierte Entitäten: 9 produktbezogene Entitäten (Name, Farbe, Typ, Material, Größe, ...) und zusätzliche Entitäten in Bezug auf Geografie und Zeit. Was die Erkennung von Absichten betrifft, so wurden mehrere Lösungen verwendet, um einen Benchmark zu erstellen:
- spaCy: eine Open-Source-Bibliothek für fortgeschrittene natürliche Sprachverarbeitung in Python, die verschiedene Funktionen bietet, darunter Named Entity Recognition.
- LUIS: siehe oben
- Ludwig: siehe oben
- Flair: siehe oben
Die folgenden Modelle wurden alle mit denselben data-Sätzen trainiert und getestet: 1600 Äußerungen zum Training, 400 zum Testen. Die Modelle wurden nicht feinabgestimmt, so dass einige von ihnen möglicherweise eine bessere Leistung erbringen als die unten dargestellten.
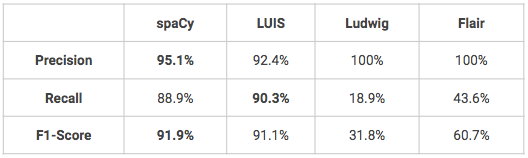
- Zwei Modelle, spaCy und LUIS, schneiden bei der Erkennung benannter Personen sehr gut ab. Ludwig und Flair müssten noch etwas feiner abgestimmt werden, um bessere Ergebnisse zu erzielen, insbesondere in Bezug auf die Wiedererkennung.
- Ein Vorteil von LUIS ist, dass der Benutzer einige fortgeschrittene Funktionen zur Erkennung von Entitäten nutzen kann, wie z.B. Deskriptoren das Hinweise darauf gibt, dass bestimmte Wörter und Ausdrücke Teil eines Entity Domain Vokabulars sind (z.B.: Farbvokabular = schwarz, weiß, rot, blau, marineblau, grün).
Fazit
Unter den Lösungen, die wir mit unserem Callcenter dataset getestet haben, ob für die Absichtserkennung oder die Erkennung von Entitäten, sticht keine in Bezug auf die Leistung hervor. Unserer Erfahrung nach sollte die Entscheidung für eine Lösung daher von der Praktikabilität und Ihrem spezifischen Anwendungsfall abhängen (verwenden Sie bereits Azure, möchten Sie lieber mehr Freiheit bei der Feinabstimmung Ihrer Modelle haben...). Zur Erinnerung: Wir haben die Bibliotheken so genommen, wie sie sind, um diesen Benchmark zu erstellen, ohne eine Feinabstimmung der Modelle vorzunehmen. Die angezeigten Ergebnisse sind also mit etwas Abstand zu betrachten und könnten bei einem anderen Anwendungsfall oder mit mehr Training data abweichen.

