


ACTUALITÉS / TECHNOLOGIE DE L'AI
25 novembre 2020
Les conseillers des centres d'appel commencent à voir l'émergence de la NLU dans leur vie quotidienne, ce qui les aide à répondre plus facilement aux demandes des clients. Pour ce faire, un outil doit être capable de reconnaître en même temps la demande du client et ses caractéristiques, en d'autres termes, une intention et des entités nommées.
“OK Google, jouez les Rolling Stones sur Spotify”, “Alexa, quel temps fait-il à Paris aujourd'hui ?”, “Siri, qui est le président français ?”.”
Si vous avez déjà utilisé des assistants vocaux, vous avez indirectement eu recours à des processus de compréhension du langage naturel (NLU). La même logique s'applique aux assistants de type chatbot ou au routage automatisé des tickets dans les services clients. Depuis un certain temps, la NLU fait partie de notre quotidien et ce n'est probablement pas près de s'arrêter.
En automatisant l'extraction de l'intention du client, par exemple, NLU peut nous aider à répondre plus rapidement et plus précisément aux demandes de nos clients. C'est pourquoi toutes les grandes entreprises se sont lancées dans le développement de leur propre solution. Cependant, avec toutes les bibliothèques et modèles existants dans le domaine du NLU, tous revendiquant des résultats de pointe ou faciles à obtenir, il est parfois compliqué de s'y retrouver. Après avoir expérimenté diverses bibliothèques dans le cadre de nos projets NLU au Artefact, nous avons voulu partager nos résultats et vous aider à mieux comprendre les outils actuels dans le domaine NLU.
Qu'est-ce que NLU ?
La compréhension du langage naturel (NLU) est définie comme suit Gartner comme “la compréhension par des ordinateurs de la structure et de la signification du langage humain (par exemple., (anglais, espagnol, japonais), permettant aux utilisateurs d'interagir avec l'ordinateur à l'aide de phrases naturelles”. En d'autres termes, le NLU est un sous-domaine du artificial intelligence qui permet d'interpréter un texte en l'analysant, en le convertissant en langage informatique et en produisant un résultat sous une forme compréhensible pour l'homme.
Si vous regardez de près le fonctionnement des chatbots et des assistants virtuels, de votre demande à leur réponse, le NLU est une couche qui extrait votre intention principale et toute information importante pour la machine afin qu'elle puisse répondre au mieux à votre demande. Imaginons que vous appeliez le service client de votre marque préférée pour savoir si le sac de vos rêves est enfin disponible dans votre ville : NLU dira à l'assistant que vous avez une demande de disponibilité de produit et cherchera l'article en question dans la base de données database pour savoir s'il est disponible à l'endroit désiré. Grâce à NLU, nous avons extrait une intention, un nom de produit et un lieu.

(Ci-dessus : illustration de l'intention d'un client et de plusieurs entités extraites de la conversation)
Le langage naturel fait partie intégrante de la data de la plupart des entreprises et, avec les récentes avancées dans ce domaine, compte tenu de la démocratisation des algorithmes NLU, de l'accès à une plus grande puissance de calcul et à plus de data, de nombreux projets NLU ont été lancés. Examinons l'un d'entre eux.
Présentation du projet
Un projet typique utilisant le NLU est, comme mentionné précédemment, d'aider les conseillers des centres d'appels à répondre aux demandes des clients plus facilement au fur et à mesure de la conversation. Pour ce faire, nous devrions effectuer deux tâches différentes :
- Comprendre l'intention du client pendant l'appel (c'est-à-dire la classification du texte)
- Saisissez les éléments importants qui permettraient de répondre à la demande du client (c'est-à-dire la reconnaissance des entités nommées), par exemple les numéros de contrat, le type de produit, la couleur du produit, etc.
Lorsque nous avons commencé à examiner les solutions simples et prêtes à l'emploi publiées pour ces deux tâches, nous avons trouvé plus d'une douzaine de cadres, certains développés par les GAFAM, d'autres par des contributeurs de plates-formes open-source. Impossible de savoir lequel choisir pour notre cas d'utilisation, comment chacun d'entre eux se comporte sur un projet concret et réel data, ici les conversations audio d'un centre d'appel transcrites en texte. C'est pourquoi nous avons décidé de partager notre benchmark de performance avec quelques conseils ainsi que les avantages et inconvénients de chaque solution que nous avons testée.
Il est important de noter que ce benchmark a été réalisé avec l'anglais data et du texte vocal transcrit et qu'il peut donc moins servir de référence pour d'autres langues ou applications utilisant directement du texte écrit, par exemple. les cas d'utilisation des chatbots.
Référence
Détection des intentions
L'objectif est ici de pouvoir détecter ce que veut le client, son intention. Étant donné une phrase, le modèle doit être capable de la classer dans la bonne classe, chaque classe correspondant à une intention prédéfinie. Lorsqu'il existe plusieurs classes, on parle de tâche de classification multi-classes. Par exemple, une intention peut être “veut acheter un produit” ou “cherche des informations”. Dans notre cas, nous avons défini 5 intentions différentes et les six solutions suivantes ont été utilisées pour le test de référence :
- FastText: pour l'apprentissage efficace de la représentation des mots et de la classification des phrases, créée par le laboratoire de recherche en IA de Facebook.
- Ludwig: une boîte à outils qui permet d'entraîner et de tester des modèles d'apprentissage profond sans avoir besoin d'écrire du code, en utilisant la ligne de commande ou l'API programmatique. L'utilisateur doit simplement fournir un fichier CSV (ou une pandas DataFrame avec l'API programmatique) contenant son data, une liste de colonnes à utiliser comme entrées, et une liste de colonnes à utiliser comme sorties, Ludwig fera le reste.
- Régression logistique avec prétraitement de l'espaCe: régression logistique classique utilisant la bibliothèque scikit-learn avec un prétraitement personnalisé utilisant la bibliothèque spaCy (tokenisation, lemmatisation, suppression des mots vides).
- BERT avec canalisation de spaCy: Les pipelines de modélisation spaCy qui enveloppent les transformateurs de Hugging Face permettent d'accéder facilement aux architectures de transformateurs de pointe telles que BERT.
- LUIS: Service API basé sur Microsoft cloud qui applique l'intelligence de l'apprentissage automatique personnalisé au texte conversationnel en langage naturel d'un utilisateur pour prédire l'intention et les entités..
- Flair: un cadre pour le NLP de pointe pour plusieurs tâches telles que la reconnaissance des entités nommées (NER), l'étiquetage de la partie du discours (PoS), la désambiguïsation du sens et la classification.
Les modèles suivants ont tous été entraînés et testés sur les mêmes ensembles data : 1600 énoncés pour l'entraînement, 400 pour le test. Les modèles n'ont pas été affinés et certains d'entre eux pourraient donc avoir de meilleures performances que celles présentées ci-dessous.
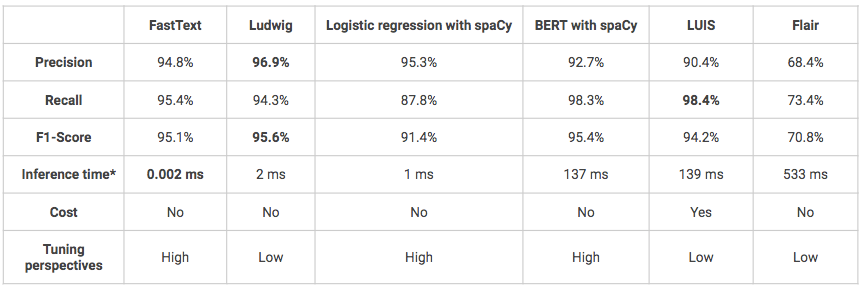
*Temps de référence sur le Macbook Air local (1.6GHz dual-core Intel Core i5-8 Go 1600 MHz DDR3 RAM).
- Globalement, en termes de performances, toutes les solutions obtiennent de bons, voire de très bons résultats (score F1 > 70%).
- L'un des inconvénients de Ludwig et de LUIS est qu'il s'agit de modèles très “boîte noire”, ce qui les rend plus difficiles à comprendre et à affiner.
- LUIS est la seule solution testée qui n'est pas open source et qui est donc beaucoup plus chère. De plus, l'utilisation de son API Python peut s'avérer complexe car elle a été initialement conçue pour être utilisée via une interface clic-bouton. Cependant, elle peut être une solution à privilégier si vous êtes dans le cadre d'un projet qui vise une mise en production et dont l'infrastructure est construite sur Azure par exemple, l'intégration du modèle sera alors plus aisée.
Extraction d'entités
L'objectif est de pouvoir localiser des mots spécifiques et de les classer correctement dans des catégories prédéfinies. En effet, une fois que vous avez détecté ce que votre client souhaite faire, vous pouvez avoir besoin de trouver d'autres informations dans sa demande. Par exemple, si un client veut acheter quelque chose, vous voudrez peut-être savoir de quel produit il s'agit, dans quelle couleur, ou si un client veut retourner un produit, vous voudrez peut-être savoir à quelle date ou dans quel magasin l'achat a été effectué. Dans notre cas, nous avions défini 16 entités personnaliséesIl s'agit de 9 entités liées au produit (nom, couleur, type, matériau, taille, ...) et d'entités supplémentaires liées à la géographie et au temps. En ce qui concerne la détection des intentions, plusieurs solutions ont été utilisées pour établir un benchmark :
- spaCy: une bibliothèque open-source pour le traitement avancé du langage naturel en Python qui offre différentes fonctionnalités, notamment la reconnaissance des entités nommées.
- LUIS : voir ci-dessus
- Ludwig : voir ci-dessus
- Flair : voir ci-dessus
Les modèles suivants ont tous été entraînés et testés sur les mêmes ensembles data : 1600 énoncés pour l'entraînement, 400 pour le test. Les modèles n'ont pas été affinés et certains d'entre eux pourraient donc avoir de meilleures performances que celles présentées ci-dessous.
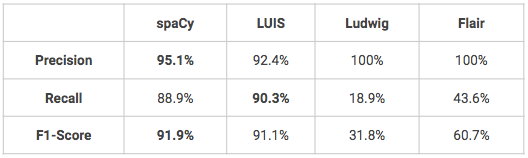
- Deux modèles obtiennent de très bons résultats en matière de reconnaissance d'entités nommées personnalisées : spaCy et LUIS. Ludwig et Flair nécessiteraient quelques ajustements pour obtenir de meilleurs résultats, notamment en termes de rappel.
- L'un des avantages de LUIS est que l'utilisateur peut tirer parti de certaines fonctions avancées pour la reconnaissance d'entités, telles que descripteurs qui indique que certains mots et phrases font partie du vocabulaire d'un domaine d'entité (par exemple : vocabulaire des couleurs = noir, blanc, rouge, bleu, bleu marine, vert).
Pour conclure
Parmi les solutions testées sur notre centre d'appel dataset, que ce soit pour la détection d'intention ou la reconnaissance d'entités, aucune ne se démarque en termes de performance. D'après notre expérience, le choix d'une solution par rapport à une autre doit donc être basé sur leur praticité et en fonction de votre cas d'utilisation spécifique (utilisez-vous déjà Azure, préférez-vous avoir plus de liberté pour affiner vos modèles...). Pour rappel, nous avons pris les bibliothèques telles quelles pour réaliser ce benchmark, sans affiner les modèles, les résultats affichés sont donc à prendre avec un léger recul et pourraient varier sur un cas d'utilisation différent ou avec plus d'entrainement data.

