

Autor


Este artigo é a terceira parte de uma série na qual percorremos o processo de registro de modelos usando o Mlflow, servindo-os no mecanismo Kubernetes e, por fim, dimensionando-os de acordo com as necessidades do nosso aplicativo. Embora este artigo possa ser usado de forma independente para testar qualquer resposta de API, recomendamos a leitura de nossos dois artigos anteriores (parte 1 e parte 2) sobre como implantar uma instância de rastreamento e servir um modelo como uma API com o Mlflow. A seguir, estaremos interessados na questão do dimensionamento e a abordaremos com alguns experimentos para entender o comportamento do cluster do k8s e dar recomendações sobre como lidar com altas cargas.
Parte 3 - Como lidar com altas cargas e tornar nosso aplicativo escalonável?
Introdução
Em um cenário clássico em que um modelo de aprendizado de máquina é implementado por trás de um aplicativo ou produto, vários usuários podem interagir com ele simultaneamente para gerar previsões. Portanto, é essencial analisar nossos recursos de infraestrutura e dimensioná-los de acordo. Isso se torna particularmente interessante no que diz respeito ao Kubernetes, pois pode afetar as decisões sobre o uso ou não do dimensionamento automático, o número máximo de nós a ser considerado...
Nesse contexto, os testes de carga permitem simular vários números simultâneos ou incrementais de solicitações e monitorar o comportamento da infraestrutura (tempo de resposta, uso da CPU, uso da memória...) para dimensionar corretamente os recursos e evitar gargalos. Esses testes serão realizados aqui usando uma ferramenta chamada Locust.
Preparação do ambiente
Os requisitos para este Hands-on estão detalhados no primeiro artigo desta série, mas, como resumo, aqui estão os principais elementos de que precisamos especificamente para esta parte, supondo que nosso modelo já esteja implantado como uma API em um cluster do Kubernetes (mlflow-k8s).
Para esta parte da prática, precisaremos do senhor:
Implantação
1. Crie a imagem do docker do Locust e envie a imagem do Locust para o GCR
cd mlflow-serving-exampledocker build --tag $/locust-tasks:v1 arquivo dockerfile_locust .docker push $/locust-tasks:v1
2. Preparar a tarefa de teste
As tarefas são funções python que o Locust executará em seus trabalhadores como parte do teste de carga, no código de exemplo fornecido em locust-tasks/tasks.py Só precisamos enviar uma solicitação POST para a API com uma linha data para obter as previsões.

Neste trecho de código :
Podemos criar tantas funções quantos forem os testes que quisermos realizar. Por exemplo, podemos adicionar uma para enviar lotes de data. Além disso, podemos usar a função @task() para dar prioridade às diferentes tarefas.
3. Implantar no Kubernetes
Agora é hora de implementar a imagem e executar o Locust em seu cluster dedicado. Primeiro, certifique-se de que o contexto esteja definido no teste_de_carga executando
kubectl config get-contexts
kubectl config use-context NAME

Em seguida, podemos atualizar nosso arquivo de implantação deployments/locust_load_test.yaml especificando o caminho da imagem no GCRe apontando o TARGET_HOST para o endereço da API.
apiVersion: v1
metadata:
nome: locust-master
etiquetas:
nome: locust
função: mestre
espec:
réplicas: 1
seletor:
nome: locust
função: mestre
modelo:
metadata:
etiquetas:
nome: locust
função: mestre
espec:
contêineres:
- nome: locust
imagem: GCR_REPO/locust-tasks:v1 # Alterar aqui
env:
- nome: LOCUST_MODE
valor: mestre
- nome: TARGET_HOST
valor: ‘http://SERVING_IP:SERVING_PORT’ # Altere aqui
portos:
- nome: loc-master-web
porta do contêiner: 8089
protocolo: TCP
- nome: loc-master-p1
porta do contêiner: 5557
protocolo: TCP
- nome: loc-master-p2
porta do contêiner: 5558
protocolo: TCP
-
tipo: ReplicationController
apiVersion: v1
metadata:
nome: locust-worker
etiquetas:
nome: locust
função: trabalhador
espec:
réplicas: 30
seletor:
nome: locust
função: trabalhador
modelo:
metadata:
etiquetas:
nome: locust
função: trabalhador
espec:
contêineres:
- nome: locust
imagem: GCR_REPO/locust-tasks:v1 # Alterar aqui
env:
- nome: LOCUST_MODE
valor: trabalhador
- nome: LOCUST_MASTER
valor: locust-master
- nome: TARGET_HOST
valor: ‘http://SERVING_IP:SERVING_PORT’ # Altere aqui
-
Tipo: Serviço
apiVersion: v1
metadata:
nome: locust-master
etiquetas:
nome: locust
função: mestre
espec:
portos:
- porto: 8089
targetPort: loc-master-web
protocolo: TCP
nome: loc-master-web
- porto: 5557
targetPort: loc-master-p1
protocolo: TCP
nome: loc-master-p1
- porto: 5558
targetPort: loc-master-p2
protocolo: TCP
nome: loc-master-p2
seletor:
nome: locust
função: mestre
Tipo: LoadBalancer
Por fim, vamos implementá-lo usando o seguinte comando.
kubectl create -f deployments/locust_load_test.yamlA instância do Locust já deve estar funcionando e um novo balanceador de carga deve ter sido criado. Podemos encontrar seu IP digitando kubectl get services e acessar a interface usando o LoadbalancerIP:8089
Experimentação
A ideia é usar o Locust para simular consultas paralelas em nossa API de serviço e analisar o comportamento do cluster e o tempo de resposta (mediana em verde e 95º percentil em laranja). Isso é feito para fins educacionais para destacar dois recursos que o Kubernetes oferece, que são o dimensionamento (automático) horizontal e vertical.
1. Dimensionamento manual
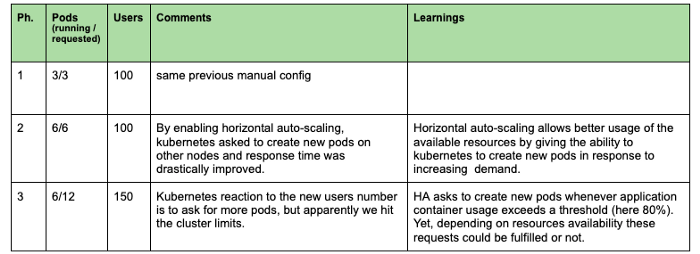
No primeiro experimento, tentamos entender o efeito de ter mais vagens servindo nossos modelos. Começamos com um pod e tentamos aumentar o número de solicitações. No gráfico abaixo, podemos diferenciar 4 fases com diferentes configurações e cobranças.
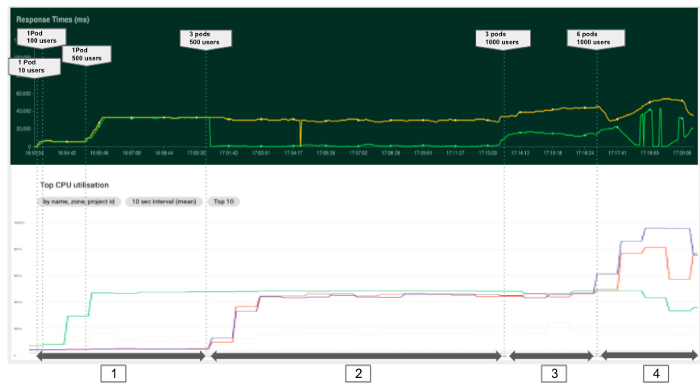
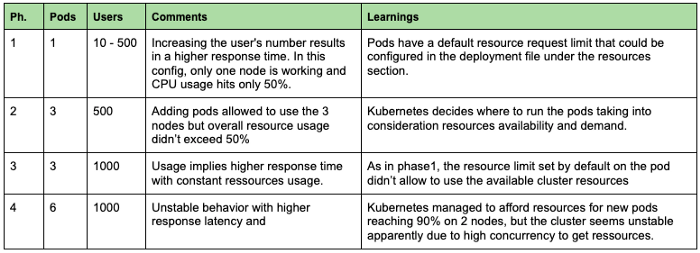
Como conclusão geral, podemos ver que é importante monitorar sempre as métricas de recursos (CPU, RAM...) para identificar gargalos e problemas de configuração. Em nosso caso, ter apenas um pod não nos permitiu aproveitar o poder de processamento disponível. Portanto, ao implantar um aplicativo, é essencial definir um número adequado de pods e definir recursos suficientes por pod para maximizar o uso da máquina, levando em consideração os serviços do sistema em execução no backend. Portanto, recomendamos não aumentar o uso da CPU dos nós para mais de 80-90%.
2. Escala automática horizontal
Bem, felizmente, o Kubernetes tem um recurso de dimensionamento horizontal automático para monitorar automaticamente o uso da CPU e criar novos pods quando necessário para distribuir a carga. Isso pode ser ativado simplesmente com o seguinte comando.
kubectl autoscale deployment mlflow-serving --cpu-percent=80 --min=1 --max=12Em seguida, podemos monitorar o número e os estados dos pods usando kubectl get hpa mlflow-serving, O senhor pode, por exemplo, analisar o tempo de resposta do cluster e o consumo de recursos.
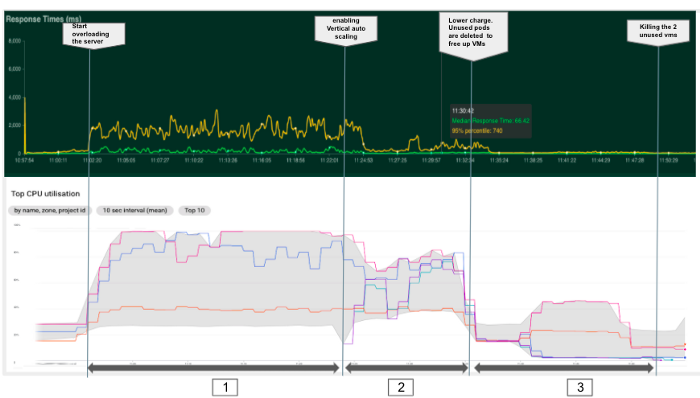
O objetivo do experimento a seguir é observar como o Kubernetes pode adicionar pods automaticamente para otimizar o uso de recursos e ter um tempo de resposta melhor. Podemos dividir esse experimento em três fases, conforme mostrado no gráfico abaixo.
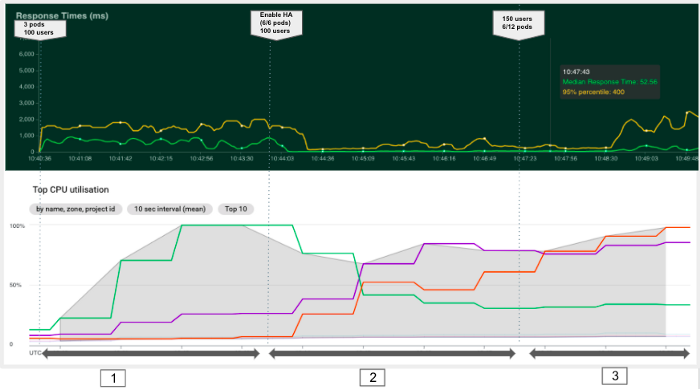
Nesse segundo experimento, notamos que o dimensionamento automático horizontal nos permitiu diminuir o tempo de resposta criando novos pods e alocando mais recursos do cluster. No entanto, ao atingir a capacidade do cluster (fase 3), os novos pods permanecem em um estado pendente e nosso tempo de resposta aumenta novamente.
3. Escala automática vertical
Em tal situação, podemos explorar outro recurso do Kubernetes conhecido como escala automática vertical que consiste em alocar mais nós sempre que for necessário. Esse recurso pode ser ativado usando o seguinte comando que especifica o número mínimo e máximo de nós que o Kubernetes pode alocar.
clusters de contêineres gcloud update mlflow-k8s
--enable-autoscaling --min-nodes 3 --max-nodes 5 --node-pool POOL_NAMEPor fim, nesse último experimento resumido no gráfico abaixo, a ativação do recurso de dimensionamento automático vertical permitiu que o Kubernetes adicionasse automaticamente dois novos nós e criasse novos pods para despachar a carga e garantir um tempo de resposta menor. Na verdade, o Kubernetes levou cerca de 1 minuto para detectar a necessidade e criar os recursos (fase 2). Além disso, com carga menor (fase 3), o Kubernetes conseguiu liberar os dois novos nós eliminando pods e reduzir o cluster para um mínimo de três nós em cerca de 15 minutos.
4. Estimativa do tamanho do cluster
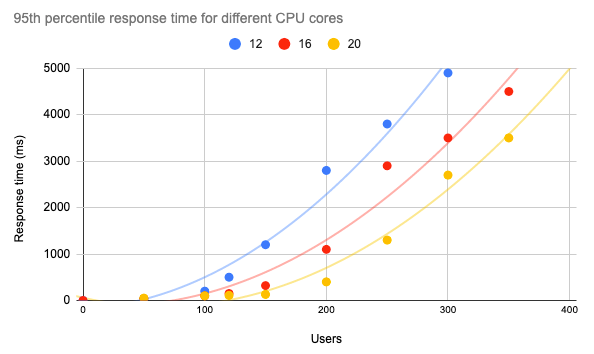
Agora que já entendemos como o Kubernetes se comporta em resposta a diferentes níveis de carga usando os recursos de dimensionamento automático vertical e horizontal, a etapa final é realizar testes de desempenho com diferentes recursos, levando em consideração os requisitos do nosso aplicativo e a estimativa do número de usuários. Vamos imaginar que, para atender aos nossos requisitos de SLA, o tempo de resposta do percentil 95 deve ser inferior a 1 segundo. Nesse caso, podemos traçar o gráfico abaixo mostrando o tempo de resposta da API para diferentes números de núcleos e ter uma ideia do desempenho do nosso aplicativo em diferentes condições.
Em particular, para nosso modelo de ML servido com o Mlflow, podemos ter cerca de 120 usuários simultâneos em um cluster Kubernetes de 12 núcleos e garantir um tempo de resposta abaixo de 1 segundo.
Conclusão
Em uma série de artigos, passamos por todo o processo de implantação da instância de rastreamento do Mlflow e servimos um modelo como uma API no mecanismo do Kubernetes, aproveitando sua capacidade de aumentar a escala facilmente e lidar com altas cargas. Também fizemos experiências com dois recursos interessantes que o Kubernetes oferece, que são o dimensionamento automático horizontal e vertical, e mostramos que é sempre interessante monitorar nossos recursos para garantir que os estamos usando de forma eficiente. Por fim, mostramos como poderíamos testar nosso aplicativo e tomar decisões sobre a infraestrutura com base em sua resposta a diferentes cenários de teste.
