

Auteur


Dit artikel is het derde deel van een serie waarin we het proces doorlopen van het loggen van modellen met behulp van Mlflow, het serveren ervan op Kubernetes engine en uiteindelijk het opschalen ervan volgens de behoeften van onze applicatie. Hoewel dit artikel onafhankelijk gebruikt kan worden om elke API-respons te testen, raden wij aan om onze twee vorige artikelen (deel1 en deel2) te lezen over hoe u een volginstantie kunt implementeren en een model als API kunt serveren met Mlflow. In het volgende zullen we geïnteresseerd zijn in het schaalbaarheidsprobleem en dit aanpakken met enkele experimenten om het gedrag van het k8s cluster te begrijpen en aanbevelingen te geven over hoe om te gaan met hoge belastingen.
Deel 3 - Hoe hoge belastingen verwerken en onze applicatie schaalbaar maken?
Inleiding
In een klassiek scenario waarbij een machine-learningmodel wordt ingezet achter een applicatie of een product, kunnen meerdere gebruikers er tegelijkertijd mee interageren om voorspellingen te genereren. Daarom is het essentieel om de mogelijkheden van onze infrastructuur te analyseren en deze dienovereenkomstig te dimensioneren. Dit wordt met name interessant voor Kubernetes, omdat het van invloed kan zijn op beslissingen over het al dan niet gebruiken van autoscaling, het maximale aantal knooppunten waarmee rekening moet worden gehouden...
In deze context maken laadtesten het mogelijk om meerdere gelijktijdige of oplopende aantallen aanvragen te simuleren en het gedrag van de infrastructuur (responstijd, CPU-gebruik, geheugengebruik...) te bewaken om bronnen correct te dimensioneren en knelpunten te vermijden. Die tests zullen hier worden uitgevoerd met een tool genaamd Locust.
Milieuvoorbereiding
De vereisten voor deze hands-on zijn gedetailleerd in het eerste artikel van deze serie, maar als samenvatting zijn hier de belangrijkste elementen die we specifiek voor dit deel nodig hebben, ervan uitgaande dat ons model al als API op een Kubernetes-cluster (mlflow-k8s) is geïmplementeerd.
Voor dit deel van de hands-on hebben we nodig:
Inzet
1. Bouw Locust docker image en push de Locust image naar GCR
cd mlflow-serving-voorbeelddocker build --tag $/locust-tasks:v1 bestand dockerfile_locust .docker push $/locust-tasks:v1
2. De testtaak voorbereiden
Taken zijn pythonfuncties die Locust zal uitvoeren op zijn werkers als onderdeel van de belastingtest, in de voorbeeldcode onder locust-tasks/tasks.py hoeven we alleen maar een POST-verzoek naar de API te sturen met een data rij om voorspellingen te krijgen.

In dit codefragment :
We kunnen zoveel functies maken als testen die we willen uitvoeren. We kunnen er bijvoorbeeld één toevoegen om data batches te verzenden. We kunnen ook de @taak() decorator om prioriteit te geven aan de verschillende taken.
3. Uitrollen naar Kubernetes
Nu is het tijd om het image uit te rollen en Locust op zijn eigen cluster te draaien. Zorg er eerst voor dat de context is ingesteld op de belasting_testen cluster door
kubectl config get-contexten
kubectl config gebruik-context NAAM

Vervolgens kunnen we ons deployment-bestand bijwerken deployments/locust_load_test.yaml door te specificeren het afbeeldingspad op GCRen wijzend op de DOEL_HOST naar het API-adres.
apiVersie: v1
metadata:
naam: sprinkhaan-meester
labels:
naam: sprinkhaan
rol: meester
spec:
replica's: 1
selector:
naam: sprinkhaan
rol: meester
sjabloon:
metadata:
labels:
naam: sprinkhaan
rol: meester
spec:
containers:
- naam: sprinkhaan
Afbeelding: GCR_REPO/locust-tasks:v1 # Hier wijzigen
nl:
- naam: LOCUST_MODE
waarde: master
- naam: TARGET_HOST
waarde: ‘http://SERVING_IP:SERVING_PORT’ # Hier wijzigen
havens:
- naam: loc-master-web
containerPort: 8089
protocol: TCP
- naam: loc-master-p1
containerPort: 5557
protocol: TCP
- naam: loc-master-p2
containerPort: 5558
protocol: TCP
-
soort: ReplicationController
apiVersie: v1
metadata:
naam: sprinkhaanwerker
labels:
naam: sprinkhaan
rol: arbeider
spec:
replica's: 30
selector:
naam: sprinkhaan
rol: arbeider
sjabloon:
metadata:
labels:
naam: sprinkhaan
rol: arbeider
spec:
containers:
- naam: sprinkhaan
Afbeelding: GCR_REPO/locust-tasks:v1 # Hier wijzigen
nl:
- naam: LOCUST_MODE
waarde: arbeider
- naam: LOCUST_MASTER
waarde: sprinkhaan-meester
- naam: TARGET_HOST
waarde: ‘http://SERVING_IP:SERVING_PORT’ # Hier wijzigen
-
Soort: Service
apiVersie: v1
metadata:
naam: sprinkhaan-meester
labels:
naam: sprinkhaan
rol: meester
spec:
havens:
- poort: 8089
doelpoort: loc-master-web
protocol: TCP
naam: loc-master-web
- poort: 5557
doelpoort: loc-master-p1
protocol: TCP
naam: loc-master-p1
- poort: 5558
doelpoort: loc-master-p2
protocol: TCP
naam: loc-master-p2
selector:
naam: sprinkhaan
rol: meester
type: LoadBalancer
Laten we het tenslotte implementeren met het volgende commando.
kubectl create -f deployments/locust_load_test.yamlDe Locust-instantie zou nu aan moeten staan en er zou een nieuwe loadbalancer moeten zijn aangemaakt. We kunnen het IP vinden door te typen kubectl get diensten en krijg toegang tot de interface met LoadbalancerIP:8089
Experiment
Het idee is om Locust te gebruiken om parallelle queries op onze API te simuleren en het gedrag en de responstijd van het cluster te analyseren (mediaan in groen en 95e percentiel oranje). Dit wordt gedaan voor educatieve doeleinden om twee functies die Kubernetes biedt te benadrukken, namelijk horizontaal en verticaal (auto)schalen.
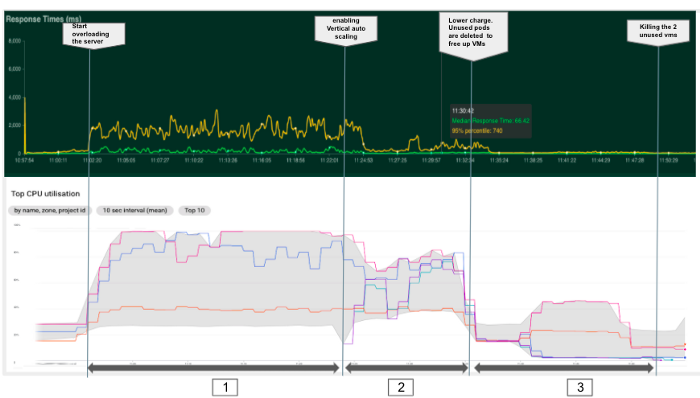
1. Handmatig schalen
In het eerste experiment proberen we het effect van meer peulen hebben onze modellen bedienen. We beginnen met één pod en proberen het aantal aanvragen te verhogen. In de grafiek hieronder kunnen we 4 fasen onderscheiden met verschillende configuraties en kosten.
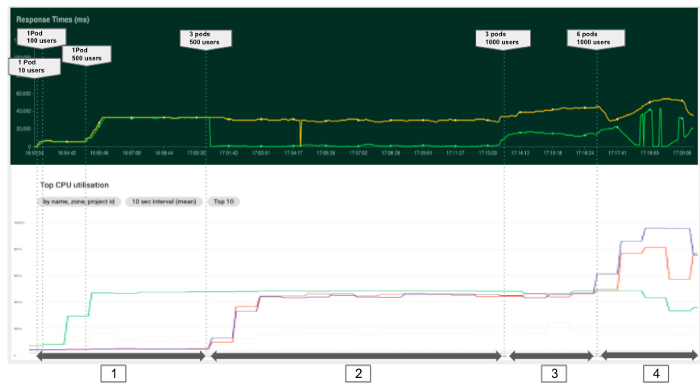
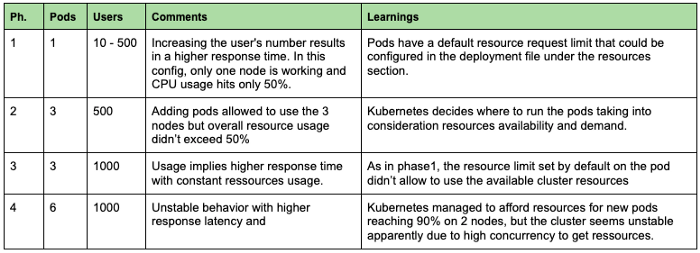
In het algemeen kunnen we zien dat het belangrijk is om altijd de metriek van de resources (CPU, RAM...) te controleren om knelpunten en configuratieproblemen op te sporen. In ons geval konden we met slechts één pod niet profiteren van de beschikbare rekenkracht. Bij het implementeren van een applicatie is het dus essentieel om een geschikt aantal pods in te stellen en voldoende bronnen per pod in te stellen om het machinegebruik te maximaliseren, rekening houdend met de systeemservices die in de backend draaien. Wij raden dus aan om het CPU-gebruik van de nodes niet hoger te zetten dan 80-90%.
2. Horizontaal automatisch schalen
Gelukkig heeft Kubernetes een functie voor automatisch horizontaal schalen om automatisch het CPU-gebruik te controleren en nieuwe pods aan te maken als dat nodig is om de lading te verdelen. Dit kan eenvoudig met de volgende opdracht worden geactiveerd.
kubectl autoscale deployment mlflow-serving --cpu-percent=80 --min=1 --max=12Vervolgens kunnen we het aantal en de status van de pods controleren met kubectl get hpa mlflow-serving, Analyseer de reactietijd van het cluster en het verbruik van bronnen.
Het doel van het volgende experiment is om te observeren hoe Kubernetes automatisch pods kan toevoegen om het gebruik van bronnen te optimaliseren en een betere responstijd te hebben. We kunnen dit experiment in drie fasen opsplitsen, zoals te zien is in de onderstaande grafiek.
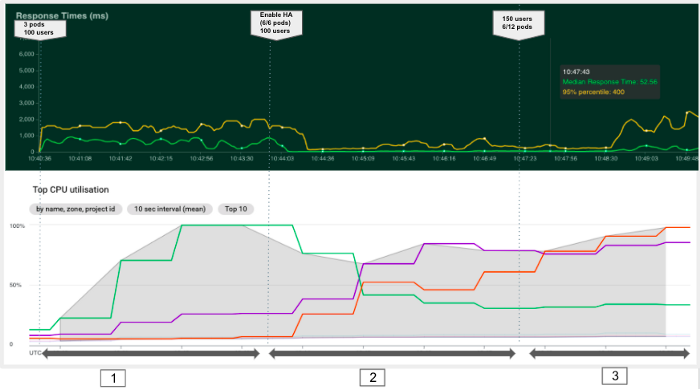
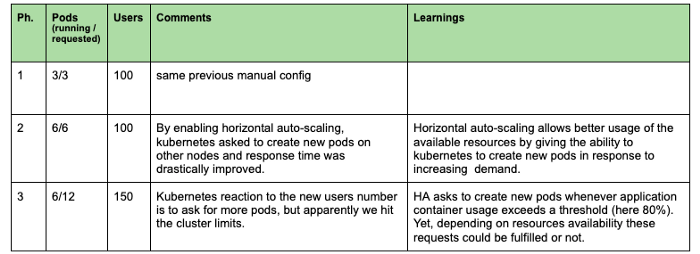
In dit tweede experiment zagen we dat horizontale auto-scaling ons in staat stelde om de responstijd te verlagen door nieuwe pods aan te maken en meer clustermiddelen toe te wijzen. Bij het bereiken van de clustercapaciteit (fase 3) blijven nieuwe pods echter in afwachting en neemt onze responstijd weer toe.
3. Verticaal automatisch schalen
In zo'n situatie kunnen we een andere Kubernetes-functie verkennen die bekend staat als verticaal automatisch schalen die bestaat uit het toewijzen van meer nodes wanneer dat nodig is. Deze functie kan worden geactiveerd met het volgende commando dat het aantal minimale en maximale knooppunten specificeert dat Kubernetes kan toewijzen.
gcloud container clusters update mlflow-k8s
--enable-autoscaling --min-nodes 3 --max-nodes 5 --node-pool POOL_NAMETot slot, in dit laatste experiment, samengevat in de grafiek hieronder, kon Kubernetes door de verticale auto-scaling functie in te schakelen automatisch twee nieuwe nodes toevoegen en nieuwe pods aanmaken om de belasting te verdelen en een lagere responstijd te garanderen. Kubernetes had ongeveer 1 minuut nodig om de behoefte te detecteren en de bronnen aan te maken (fase 2). Met een lagere belasting (fase 3) slaagde Kubernetes er bovendien in om de twee nieuwe nodes vrij te maken door pods te doden en het cluster in ongeveer 15 minuten terug te schalen naar een minimum van drie nodes.
4. Schatting van de clustergrootte
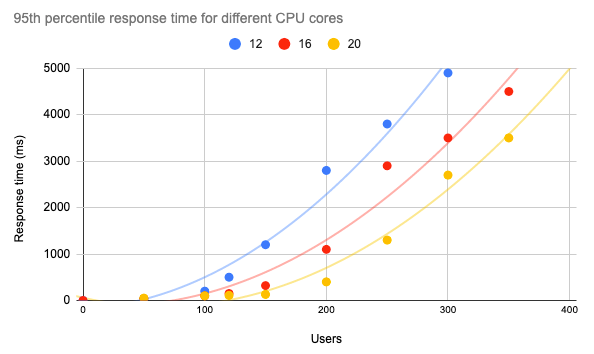
Nu we hebben begrepen hoe Kubernetes zich gedraagt als reactie op verschillende laadniveaus met behulp van verticale en horizontale functies voor automatisch schalen, is de laatste stap het uitvoeren van prestatietests met verschillende bronnen, rekening houdend met de vereisten van onze applicatie en de schatting van het aantal gebruikers. Laten we ons voorstellen dat, om aan onze SLA-eisen te voldoen, onze 95e percentiel responstijd lager dan 1 sec. moet zijn. In dit geval kunnen we de onderstaande grafiek met de API responstijd voor verschillende cores uitzetten en een idee krijgen van de prestaties van onze applicatie onder verschillende omstandigheden.
Voor ons ML-model dat met Mlflow wordt geserveerd, kunnen we ongeveer 120 gelijktijdige gebruikers hebben op een Kubernetes-cluster met 12 cores en een responstijd van minder dan 1 sec. garanderen.
Conclusie
In een reeks artikelen hebben we het hele proces doorlopen om Mlflow tracking instance te implementeren en een model als API op Kubernetes te serveren, waarbij we gebruik hebben gemaakt van de mogelijkheid om eenvoudig op te schalen en hoge belastingen aan te kunnen. We hebben ook geëxperimenteerd met twee interessante functies die Kubernetes biedt, namelijk horizontaal en verticaal automatisch schalen, en we hebben laten zien dat het altijd interessant is om onze bronnen te monitoren om er zeker van te zijn dat we ze efficiënt gebruiken. Tot slot lieten we zien hoe we onze applicatie konden testen en beslissingen konden nemen over de infrastructuur op basis van de respons op verschillende testscenario's.
