

Autor


Este artículo es la tercera parte de una serie en la que recorremos el proceso de registrar modelos utilizando Mlflow, servirlos en el motor Kubernetes y finalmente escalarlos según las necesidades de nuestra aplicación. Aunque este artículo podría utilizarse de forma independiente para probar cualquier respuesta de API, recomendamos la lectura de nuestros dos artículos anteriores (parte1 y parte2) sobre cómo desplegar una instancia de seguimiento y servir un modelo como API con Mlflow. A continuación, nos interesaremos por la cuestión de la escalabilidad y la abordaremos con algunos experimentos para comprender el comportamiento del clúster k8s y dar recomendaciones sobre cómo manejar cargas elevadas.
Parte 3 - ¿Cómo manejar cargas elevadas y hacer que nuestra aplicación sea escalable?
Introducción
En un escenario clásico en el que se despliega un modelo de aprendizaje automático detrás de una aplicación o un producto, varios usuarios podrían interactuar con él simultáneamente para generar predicciones. Por lo tanto, es esencial analizar las capacidades de nuestra infraestructura y dimensionarla en consecuencia. Esto resulta especialmente interesante en lo que respecta a Kubernetes, ya que podría influir en las decisiones sobre si utilizar o no el autoescalado, el número máximo de nodos a considerar...
En este contexto, las pruebas de carga permiten simular múltiples números simultáneos o incrementales de peticiones y monitorizar el comportamiento de la infraestructura (tiempo de respuesta, uso de CPU, uso de memoria..) con el fin de dimensionar correctamente los recursos y evitar cuellos de botella. Estas pruebas se realizarán aquí utilizando una herramienta llamada Locust.
Preparación del entorno
Los requisitos para este Hands-on se detallan en el primer artículo de esta serie, pero a modo de resumen, aquí están los principales elementos que necesitamos específicamente para esta parte suponiendo que nuestro modelo ya está desplegado como una API en un clúster Kubernetes (mlflow-k8s).
Para esta parte de la práctica, necesitaremos:
Despliegue
1. Construya la imagen Locust docker y empuje la imagen Locust a GCR
cd mlflow-serving-ejemplodocker build --tag $/locust-tasks:v1 archivo dockerfile_locust .docker push $/locust-tasks:v1
2. Prepare la tarea de prueba
Las tareas son funciones python que Locust ejecutará en sus trabajadores como parte de la prueba de carga, en el código de ejemplo proporcionado en locust-tareas/tareas.py sólo tenemos que enviar una solicitud POST a la API con una fila data para obtener predicciones.

En este fragmento de código :
Podemos crear tantas funciones como pruebas queramos realizar. Por ejemplo, podemos añadir una para enviar lotes de data. Además, podemos utilizar la función @tarea() decorador para dar prioridad a las distintas tareas.
3. Despliegue en Kubernetes
Ahora es el momento de desplegar la imagen y ejecutar Locust en su clúster dedicado. En primer lugar, asegúrese de que el contexto está establecido en el carga_prueba cluster ejecutando
kubectl config get-contexts
kubectl config use-context NOMBRE

A continuación, podemos actualizar nuestro archivo de despliegue deployments/locust_load_test.yaml especificando la ruta de la imagen en GCRy señalando el TARGET_HOST a la dirección API.
apiVersion: v1
metadata:
nombre: locust-master
etiquetas:
nombre: langosta
papel: maestro
espec:
réplicas: 1
selector:
nombre: langosta
papel: maestro
plantilla:
metadata:
etiquetas:
nombre: langosta
papel: maestro
espec:
contenedores:
- nombre: langosta
imagen: GCR_REPO/locust-tasks:v1 # Cambiar aquí
env:
- nombre: LOCUST_MODE
valor: maestro
- nombre: TARGET_HOST
valor: ‘http://SERVING_IP:SERVING_PORT’ # Cambie aquí
puertos:
- nombre: loc-master-web
containerPort: 8089
protocolo: TCP
- nombre: loc-master-p1
containerPort: 5557
protocolo: TCP
- nombre: loc-master-p2
containerPort: 5558
protocolo: TCP
-
tipo: ReplicationController
apiVersion: v1
metadata:
nombre: trabajador de la langosta
etiquetas:
nombre: langosta
papel: trabajador
espec:
réplicas: 30
selector:
nombre: langosta
papel: trabajador
plantilla:
metadata:
etiquetas:
nombre: langosta
papel: trabajador
espec:
contenedores:
- nombre: langosta
imagen: GCR_REPO/locust-tasks:v1 # Cambiar aquí
env:
- nombre: LOCUST_MODE
valor: trabajador
- nombre: LOCUST_MASTER
valor: locust-master
- nombre: TARGET_HOST
valor: ‘http://SERVING_IP:SERVING_PORT’ # Cambie aquí
-
Tipo: Servicio
apiVersion: v1
metadata:
nombre: locust-master
etiquetas:
nombre: langosta
papel: maestro
espec:
puertos:
- puerto: 8089
targetPort: loc-master-web
protocolo: TCP
nombre: loc-master-web
- puerto 5557
targetPort: loc-master-p1
protocolo: TCP
nombre: loc-master-p1
- puerto 5558
targetPort: loc-master-p2
protocolo: TCP
nombre: loc-master-p2
selector:
nombre: langosta
papel: maestro
tipo: LoadBalancer
Por último, vamos a desplegarlo utilizando el siguiente comando.
kubectl create -f deployments/locust_load_test.yamlLa instancia de Langosta debería estar ahora en marcha y se debería haber creado un nuevo equilibrador de carga. Podemos encontrar su IP escribiendo kubectl obtener servicios y acceder a la interfaz utilizando el LoadbalancerIP:8089
Experimentación
La idea es utilizar Locust para simular consultas paralelas en nuestra API de servicio y analizar el comportamiento del clúster y el tiempo de respuesta (mediana en verde y percentil 95 en naranja). Esto se hace con fines educativos para destacar dos características que ofrece Kubernetes que son el (auto)escalado horizontal y vertical.
1. Escalado manual
En el primer experimento, intentamos comprender el efecto de tener más vainas sirviendo nuestros modelos. Empezamos con un pod e intentamos aumentar el número de peticiones. En el gráfico siguiente, podemos diferenciar 4 fases con distintas configuraciones y cargas.
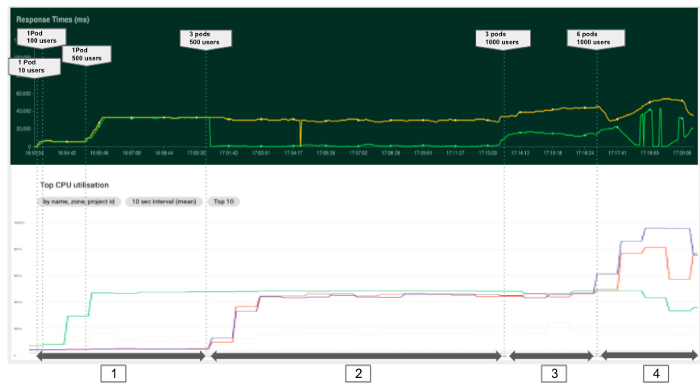
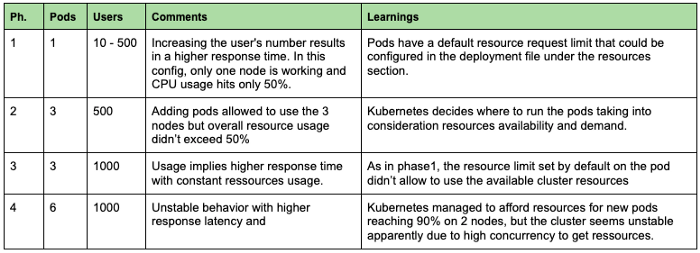
Como conclusión general, podemos ver que es importante monitorizar siempre las métricas de recursos (CPU, RAM..) para identificar cuellos de botella y problemas de configuración. En nuestro caso, disponer de un solo pod no nos permitía aprovechar la potencia de procesamiento disponible. Por lo tanto, al desplegar una aplicación, es esencial establecer un número adecuado de pods y fijar suficientes recursos por pod para maximizar el uso de la máquina teniendo en cuenta los servicios del sistema que se ejecutan en el backend. Así pues, recomendamos no forzar el uso de la CPU de los nodos por encima de 80-90%.
2. Autoescalado horizontal
Bueno, afortunadamente, Kubernetes tiene un función de escala horizontal automática para supervisar automáticamente el uso de la CPU y crear nuevos pods cuando sea necesario para distribuir la carga. Esto podría activarse simplemente con el siguiente comando.
kubectl autoscale deployment mlflow-serving --cpu-percent=80 --min=1 --max=12A continuación, podemos supervisar el número y los estados de los pods utilizando kubectl get hpa mlflow-serving, analizar el tiempo de respuesta del cluster y el consumo de recursos.
El objetivo del siguiente experimento es observar cómo Kubernetes puede añadir pods automáticamente para optimizar el uso de recursos y tener un mejor tiempo de respuesta. Podemos dividir este experimento en tres fases como se muestra en el siguiente gráfico.
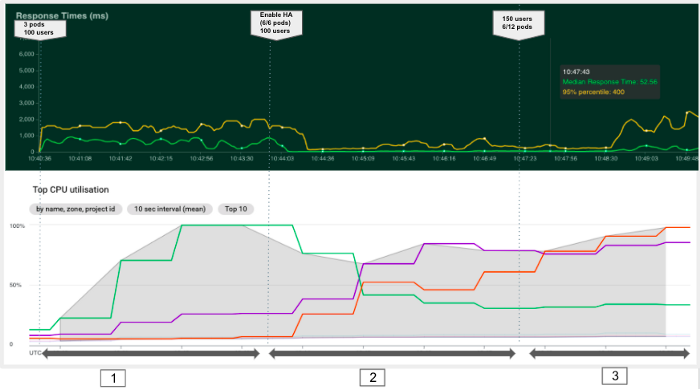
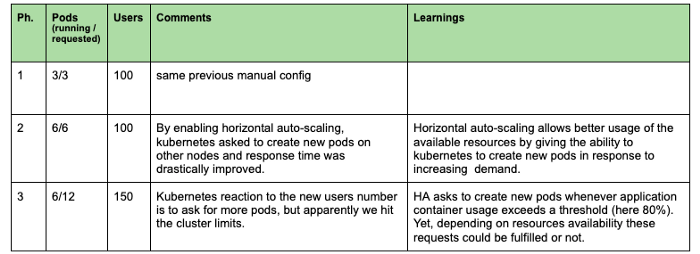
En este segundo experimento, observamos que el autoescalado horizontal nos permitía reducir el tiempo de respuesta mediante la creación de nuevos pods y la asignación de más recursos de clúster. Sin embargo, al alcanzar la capacidad del clúster (fase3) los nuevos pods permanecen en estado pendiente y nuestro tiempo de respuesta vuelve a aumentar.
3. Autoescalado vertical
En tal situación, podemos explorar otra característica de Kubernetes conocida como autoescalado vertical que consiste en asignar más nodos siempre que sea necesario. Esta función puede activarse mediante el siguiente comando que especifica el número mínimo y máximo de nodos que Kubernetes puede asignar.
gcloud container clusters update mlflow-k8s
--enable-autoscaling --min-nodes 3 --max-nodes 5 --node-pool POOL_NAMEFinalmente, en este último experimento resumido en el gráfico siguiente, habilitar la función de autoescalado vertical, permitió a Kubernetes añadir automáticamente dos nuevos nodos y crear nuevos pods para despachar la carga y garantizar un menor tiempo de respuesta. En realidad, Kubernetes tardó alrededor de 1 minuto en detectar la necesidad y crear los recursos (fase 2). Además, con una carga menor (fase 3) Kubernetes consiguió liberar los dos nuevos nodos matando pods y reducir el clúster a un mínimo de tres nodos en unos 15 min.
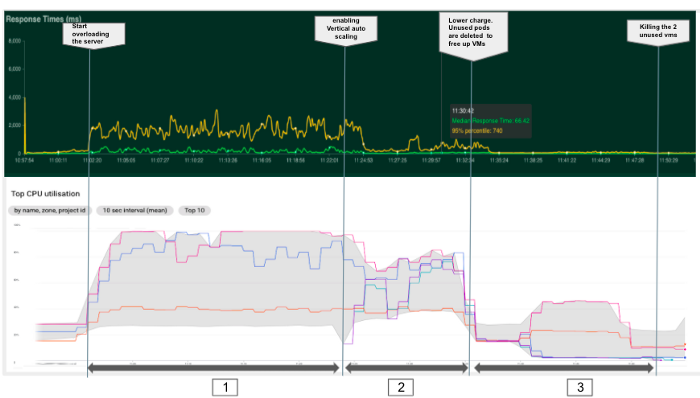
4. Estimación del tamaño de los conglomerados
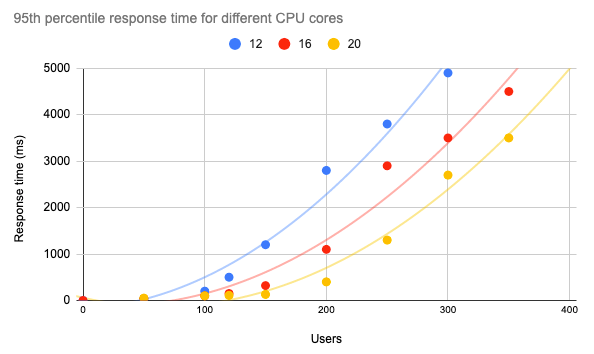
Ahora que hemos comprendido cómo se comporta Kubernetes en respuesta a diferentes niveles de carga utilizando las funciones de autoescalado vertical y horizontal, el último paso es realizar pruebas de rendimiento con diferentes recursos, teniendo en cuenta los requisitos de nuestra aplicación y la estimación de su número de usuarios. Imaginemos que, para cumplir los requisitos de nuestro SLA, nuestro tiempo de respuesta del percentil 95 debe ser inferior a 1 s. En este caso, podemos trazar el gráfico siguiente mostrando el tiempo de respuesta de la API para diferentes números de núcleos y hacernos una idea del rendimiento de nuestra aplicación en diferentes condiciones.
En concreto, para nuestro modelo ML servido con Mlflow, podemos tener unos 120 usuarios simultáneos en un clúster Kubernetes de 12 núcleos y garantizar un tiempo de respuesta inferior a 1 s.
Conclusión
En una serie de artículos, recorrimos todo el proceso para desplegar una instancia de seguimiento de Mlflow y servir un modelo como API en el motor Kubernetes aprovechando su capacidad para escalar fácilmente y manejar cargas elevadas. También experimentamos con dos interesantes características que ofrece Kubernetes que son el autoescalado horizontal y vertical y demostramos que siempre es interesante monitorizar nuestros recursos para asegurarnos de que los estamos utilizando eficientemente. Por último, mostramos cómo podíamos probar nuestra aplicación y tomar decisiones sobre la infraestructura en función de su respuesta a diferentes escenarios de prueba.
