

Auteur


Cet article est la troisième partie d'une série dans laquelle nous passons en revue le processus de journalisation des modèles à l'aide de Mlflow, de les servir sur le moteur Kubernetes et enfin de les mettre à l'échelle en fonction des besoins de notre application. Bien que cet article puisse être utilisé indépendamment pour tester n'importe quelle réponse d'API, nous vous recommandons de lire nos deux articles précédents (partie 1 et partie 2) sur la façon de déployer une instance de suivi et de servir un modèle en tant qu'API avec Mlflow. Dans la suite de cet article, nous nous intéresserons à la question de la scalabilité et nous l'aborderons avec quelques expériences pour comprendre le comportement du cluster k8s et donner des recommandations sur la façon de gérer des charges élevées.
Partie 3 - Comment gérer des charges élevées et rendre notre application évolutive ?
Introduction
Dans un scénario classique où un modèle d'apprentissage automatique est déployé derrière une application ou un produit, plusieurs utilisateurs peuvent interagir avec lui simultanément pour générer des prédictions. Il est donc essentiel d'analyser les capacités de notre infrastructure et de la dimensionner en conséquence. Cela devient particulièrement intéressant en ce qui concerne Kubernetes, car cela pourrait avoir un impact sur les décisions concernant l'utilisation ou non de l'autoscaling, le nombre maximum de nœuds à considérer....
Dans ce contexte, les tests de charge permettent de simuler un nombre multiple de requêtes simultanées ou incrémentales et de surveiller le comportement de l'infrastructure (temps de réponse, utilisation du CPU, utilisation de la mémoire..) afin de dimensionner correctement les ressources et d'éviter les goulets d'étranglement. Ces tests seront réalisés ici à l'aide d'un outil appelé Locust.
Préparation de l'environnement
Les exigences pour ce Hands-on sont détaillées dans le premier article de cette série mais en guise de résumé, voici les principaux éléments dont nous avons besoin spécifiquement pour cette partie en supposant que notre modèle est déjà déployé en tant qu'API sur un cluster Kubernetes (mlflow-k8s).
Pour cette partie de l'exercice pratique, nous aurons besoin de :
Déploiement
1. Construire l'image docker de Locust et pousser l'image de Locust vers GCR
cd mlflow-serving-exampledocker build --tag $/locust-tasks:v1 fichier dockerfile_locust .docker push $/locust-tasks:v1
2. Préparez la tâche de test
Les tâches sont des fonctions python que Locust exécutera sur ses travailleurs dans le cadre du test de charge, dans l'exemple de code fourni sous la rubrique locust-tasks/tasks.py il suffit d'envoyer une requête POST à l'API avec une ligne data pour obtenir des prédictions.

Dans cet extrait de code :
Nous pouvons créer autant de fonctions que de tests que nous voulons effectuer. Par exemple, nous pouvons en ajouter une pour envoyer des lots de data. Nous pouvons également utiliser la fonction @task() pour donner la priorité aux différentes tâches.
3. Déployez vers Kubernetes
Il est maintenant temps de déployer l'image et d'exécuter Locust sur son cluster dédié. Tout d'abord, assurez-vous que le contexte est défini sur le serveur load_testing en exécutant
kubectl config get-contexts
kubectl config use-context NAME

Ensuite, nous pouvons mettre à jour notre fichier de déploiement deployments/locust_load_test.yaml en spécifiant le chemin de l'image sur le GCRet en pointant le TARGET_HOST à l'adresse de l'API.
apiVersion : v1
metadata :
nom : locust-master
les étiquettes :
nom : locuste
rôle : maître
spéc :
répliques : 1
sélecteur :
nom : locuste
rôle : maître
modèle :
metadata :
les étiquettes :
nom : locuste
rôle : maître
spéc :
des conteneurs :
- nom : locuste
image : GCR_REPO/locust-tasks:v1 # Modifier ici
env :
- nom : LOCUST_MODE
valeur : maître
- nom : TARGET_HOST
valeur : ‘http://SERVING_IP:SERVING_PORT’ # Modifier ici
ports :
- nom : loc-master-web
containerPort : 8089
protocole : TCP
- nom : loc-master-p1
containerPort : 5557
protocole : TCP
- nom : loc-master-p2
containerPort : 5558
protocole : TCP
-
type : Contrôleur de réplication
apiVersion : v1
metadata :
nom : ouvrier acridien
les étiquettes :
nom : locuste
rôle : travailleur
spéc :
répliques : 30
sélecteur :
nom : locuste
rôle : travailleur
modèle :
metadata :
les étiquettes :
nom : locuste
rôle : travailleur
spéc :
des conteneurs :
- nom : locuste
image : GCR_REPO/locust-tasks:v1 # Modifier ici
env :
- nom : LOCUST_MODE
valeur : travailleur
- nom : LOCUST_MASTER
valeur : maître des sauterelles
- nom : TARGET_HOST
valeur : ‘http://SERVING_IP:SERVING_PORT’ # Modifier ici
-
genre : Service
apiVersion : v1
metadata :
nom : locust-master
les étiquettes :
nom : locuste
rôle : maître
spéc :
ports :
- port : 8089
targetPort : loc-master-web
protocole : TCP
nom : loc-master-web
- port : 5557
targetPort : loc-master-p1
protocole : TCP
nom : loc-master-p1
- port : 5558
targetPort : loc-master-p2
protocole : TCP
nom : loc-master-p2
sélecteur :
nom : locuste
rôle : maître
type : LoadBalancer
Enfin, déployons-le à l'aide de la commande suivante.
kubectl create -f deployments/locust_load_test.yamlL'instance de Locust devrait maintenant être en place et un nouvel équilibreur de charge devrait avoir été créé. Nous pouvons trouver son IP en tapant kubectl get services et accédez à l'interface à l'aide de LoadbalancerIP:8089
Expérimentation
L'idée est d'utiliser Locust pour simuler des requêtes parallèles sur notre API de service et d'analyser le comportement du cluster et le temps de réponse (médiane en vert et 95ème percentile en orange). Ceci est fait à des fins éducatives pour mettre en évidence deux fonctionnalités offertes par Kubernetes, à savoir la mise à l'échelle horizontale et verticale (auto)-mise à l'échelle.
1. Mise à l'échelle manuelle
Dans la première expérience, nous essayons de comprendre l'effet des avoir plus de gousses pour servir nos modèles. Nous commençons avec un pod et essayons d'augmenter le nombre de requêtes. Dans le graphique ci-dessous, nous pouvons différencier 4 phases avec différentes configurations et charges.
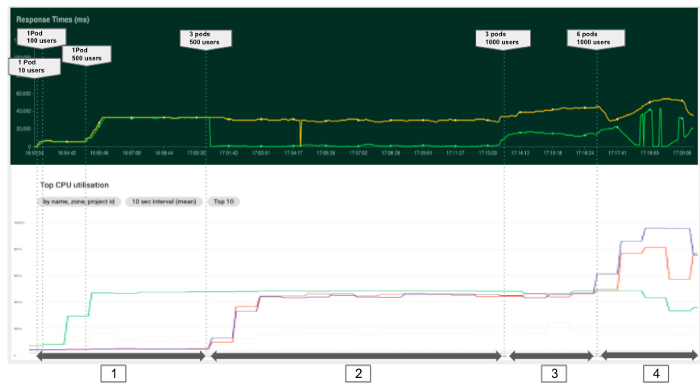
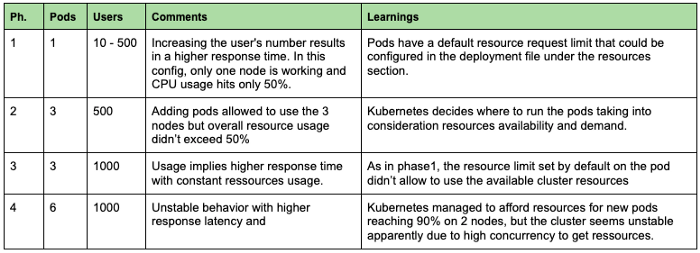
D'une manière générale, nous pouvons constater qu'il est important de toujours surveiller les mesures des ressources (CPU, RAM..) pour identifier les goulots d'étranglement et les problèmes de configuration. Dans notre cas, le fait de n'avoir qu'un seul pod ne nous a pas permis de profiter de la puissance de traitement disponible. Ainsi, lors du déploiement d'une application, il est essentiel de définir un nombre adéquat de pods et de définir suffisamment de ressources par pod pour maximiser l'utilisation de la machine en tenant compte des services système exécutés dans le backend. Nous vous recommandons donc de ne pas dépasser 80-90% pour l'utilisation du CPU des nœuds.
2. Mise à l'échelle automatique horizontale
Heureusement, Kubernetes dispose d'un système de gestion de l'information. fonction de mise à l'échelle horizontale automatique pour surveiller automatiquement l'utilisation du CPU et créer de nouveaux pods si nécessaire pour répartir la charge. Ceci peut être simplement activé par la commande suivante.
kubectl autoscale deployment mlflow-serving --cpu-percent=80 --min=1 --max=12Nous pouvons ensuite surveiller le nombre et l'état des pods en utilisant la fonction kubectl get hpa mlflow-serving, Le système d'information sur la gestion de l'environnement permet d'analyser le temps de réponse de la grappe et la consommation de ressources.
L'objectif de l'expérience suivante est d'observer comment Kubernetes peut ajouter automatiquement des pods afin d'optimiser l'utilisation des ressources et d'obtenir un meilleur temps de réponse. Nous pouvons diviser cette expérience en trois phases, comme le montre le graphique ci-dessous.
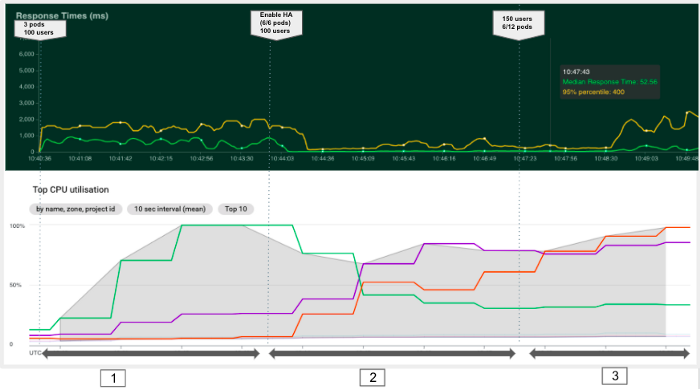
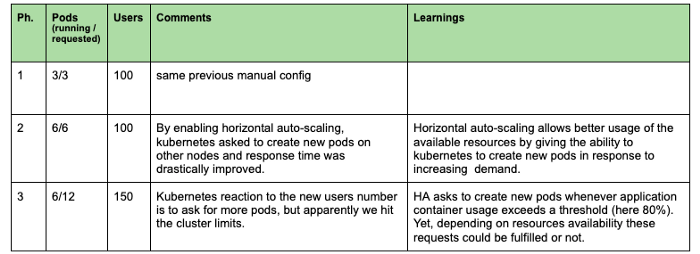
Dans cette deuxième expérience, nous avons remarqué que l'auto-scaling horizontal nous permettait de réduire le temps de réponse en créant de nouveaux pods et en allouant plus de ressources au cluster. Cependant, lorsque la capacité du cluster est atteinte (phase 3), les nouveaux pods restent en attente et notre temps de réponse augmente à nouveau.
3. Mise à l'échelle automatique verticale
Dans une telle situation, nous pouvons explorer une autre fonctionnalité de Kubernetes connue sous le nom de mise à l'échelle automatique verticale qui consiste à allouer plus de nœuds chaque fois que cela est nécessaire. Cette fonctionnalité peut être activée à l'aide de la commande suivante qui spécifie le nombre de nœuds minimum et maximum que Kubernetes peut allouer.
gcloud container clusters update mlflow-k8s
--enable-autoscaling --min-nodes 3 --max-nodes 5 --node-pool POOL_NAMEEnfin, dans cette dernière expérience résumée dans le graphique ci-dessous, l'activation de la fonction d'auto-scaling vertical a permis à Kubernetes d'ajouter automatiquement deux nouveaux nœuds et de créer de nouveaux pods pour répartir la charge et garantir un temps de réponse plus faible. En fait, il a fallu environ 1 minute à Kubernetes pour détecter le besoin et créer les ressources (phase 2). De plus, avec une charge plus faible (phase 3), Kubernetes a réussi à libérer les deux nouveaux nœuds en tuant les pods et à réduire le cluster à un minimum de trois nœuds en 15 minutes environ.
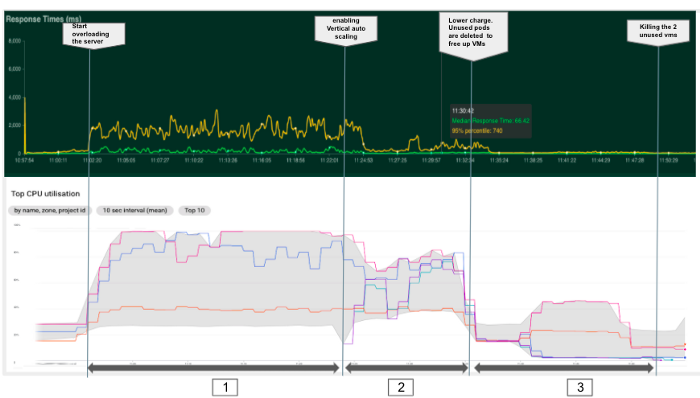
4. Estimation de la taille des grappes
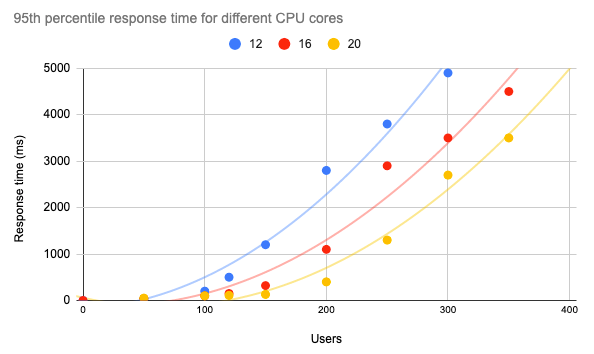
Maintenant que nous avons compris comment Kubernetes se comporte en réponse à différents niveaux de charge en utilisant les fonctionnalités d'auto-scaling vertical et horizontal, l'étape ultime consiste à effectuer des tests de performance avec différentes ressources, en tenant compte des exigences de notre application et de l'estimation du nombre de ses utilisateurs. Imaginons que, pour satisfaire aux exigences de notre accord de niveau de service, notre temps de réponse au 95e percentile doit être inférieur à 1 seconde. Dans ce cas, nous pouvons tracer le graphique ci-dessous montrant le temps de réponse de l'API pour différents nombres de cœurs et nous faire une idée de la performance de notre application dans différentes conditions.
En particulier, pour notre modèle ML servi avec Mlflow, nous pouvons avoir environ 120 utilisateurs simultanés sur un cluster Kubernetes de 12 cœurs et garantir un temps de réponse inférieur à 1 seconde.
Pour conclure
Dans cette série d'articles, nous avons parcouru l'ensemble du processus de déploiement de l'instance de suivi de Mlflow et de service d'un modèle en tant qu'API sur le moteur Kubernetes en tirant parti de sa capacité à s'adapter facilement et à gérer des charges élevées. Nous avons également expérimenté deux fonctionnalités intéressantes offertes par Kubernetes, à savoir l'auto-scaling horizontal et vertical, et nous avons montré qu'il est toujours intéressant de surveiller nos ressources pour s'assurer que nous les utilisons de manière efficace. Enfin, nous avons montré comment nous pouvions tester notre application et prendre des décisions concernant l'infrastructure en fonction de sa réponse à différents scénarios de test.
