

作者


本文是系列文章的第三部分,在这一部分中,我们将介绍使用 Mlflow 记录模型、在 Kubernetes 引擎上提供模型并最终根据应用需求对其进行扩展的过程。虽然本文可独立用于测试任何 API 响应,但我们建议您阅读我们之前的两篇文章(第一部分和第二部分),了解如何使用 Mlflow 部署跟踪实例并将模型作为 API 提供。在下文中,我们将关注可扩展性问题,并通过一些实验来了解 k8s 集群的行为,并就如何处理高负载提出建议。.
第 3 部分 - 如何处理高负载并使我们的应用程序具有可扩展性?
导言
在典型的应用场景中,机器学习模型被部署在应用程序或产品的背后,多个用户可以同时与之交互以生成预测。因此,分析我们的基础架构能力并对其进行相应的调整至关重要。就 Kubernetes 而言,这一点变得尤为有趣,因为它可能会影响到是否使用自动扩展、考虑的最大节点数......
在这种情况下,收费测试可以模拟多个同时或递增的请求数量,并监控基础设施的行为(响应时间、CPU 使用率、内存使用率......),以便正确调配资源,避免出现瓶颈。这些测试将使用名为 Locust 的工具进行。.
环境准备
本系列第一篇文章中详细介绍了本次 "实践 "的要求,但作为总结,假设我们的模型已经作为 API 部署在 Kubernetes 集群 (mlflow-k8s) 上,以下是本部分具体需要的主要元素。.
在这部分实践中,我们需要
部署
1.构建 Locust docker 镜像并将 Locust 镜像推送到 GCR
cd mlflow-serving-exampledocker build --tag $/locust-tasks:v1 文件 dockerfile_locust .docker push $/locust-tasks:v1
2.准备测试任务
任务(Tasks)是Locust在负载测试中执行的python函数。 locust-tasks/tasks.py 我们只需向 API 发送 POST 请求,输入 data 行即可获得预测结果。.

在此代码片段中 :
我们可以创建尽可能多的功能来执行我们想要的测试。例如,我们可以添加一个发送 data 批次的功能。此外,我们还可以使用 @task() 装饰器为不同的任务赋予优先级。.
3.部署到 Kubernetes
现在是部署镜像并在专用集群上运行 Locust 的时候了。首先,确保上下文设置在 加载测试 运行
kubectl config get-contexts
kubectl config use-context NAME

接下来,我们可以更新部署文件 deployments/locust_load_test.yaml 通过指定 GCR 上的图像路径和 指向 目标主机 到 API 地址。.
apiVersion: v1
元 data:
名称:蝗虫大师
标签
名称:蝗虫
角色:主人
规格:
复制品:1
选择器:
名称:蝗虫
角色:主人
模板:
元 data:
标签
名称:蝗虫
角色:主人
规格:
集装箱
- 名称:蝗虫
图像:GCR_REPO/locust-tasks:v1 # 在此处更改
env:
- 名称: LOCUST_MODE
值:主
- 名称: TARGET_HOST
值:‘http://SERVING_IP:SERVING_PORT’ # 在此处更改
端口:
- 名称: loc-master-web
容器端口:8089
协议:TCP
- 名称: loc-master-p1
容器端口:5557
协议:TCP
- 名称: loc-master-p2
容器端口:5558
协议:TCP
-
种类复制控制器
apiVersion: v1
元 data:
名称:蝗虫工人
标签
名称:蝗虫
角色:工人
规格:
复制品:30
选择器:
名称:蝗虫
角色:工人
模板:
元 data:
标签
名称:蝗虫
角色:工人
规格:
集装箱
- 名称:蝗虫
图像:GCR_REPO/locust-tasks:v1 # 在此处更改
env:
- 名称: LOCUST_MODE
值:工人
- 名称: LOCUST_MASTER
值:蝗虫大师
- 名称: TARGET_HOST
值:‘http://SERVING_IP:SERVING_PORT’ # 在此处更改
-
种类:服务
apiVersion: v1
元 data:
名称:蝗虫大师
标签
名称:蝗虫
角色:主人
规格:
端口:
- 港口8089
targetPort: loc-master-web
协议:TCP
名称: loc-master-web
- 港口5557
targetPort: loc-master-p1
协议:TCP
名称: loc-master-p1
- 港口5558
targetPort: loc-master-p2
协议:TCP
名称: loc-master-p2
选择器:
名称:蝗虫
角色:主人
类型负载平衡器
最后,让我们使用以下命令进行部署。.
kubectl create -f deployments/locust_load_test.yamlLocust 实例现在应该已经启动,新的负载平衡器应该已经创建。我们可以键入 kubectl get services 并使用负载平衡器 IP:8089 访问接口
实验
我们的想法是使用 Locust 来模拟对服务 API 的并行查询,并分析集群的行为和响应时间(绿色为中位数,橙色为第 95 百分位数)。这样做的目的是为了突出 Kubernetes 提供的两个功能,即水平和垂直(自动)扩展。.
1.手动缩放
在第一个实验中,我们试图了解 多荚 为我们的模型提供服务。我们从一个 pod 开始,并尝试增加请求数量。在下图中,我们可以看到不同配置和费用的 4 个阶段。.
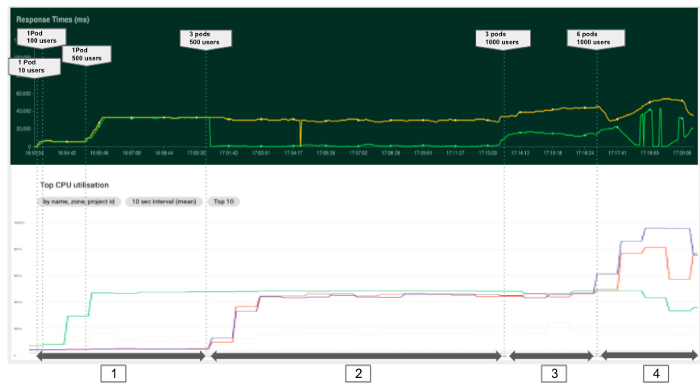
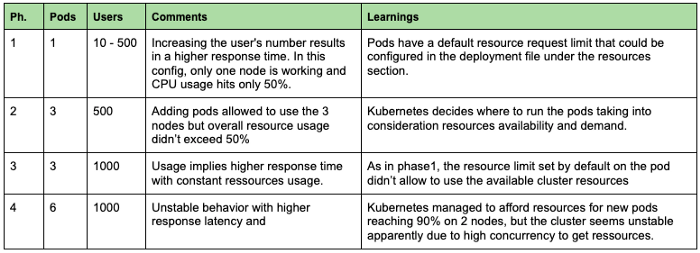
总的来说,我们可以看出,始终监控资源指标(CPU、内存......)以识别瓶颈和配置问题非常重要。在我们的案例中,只有一个 pod 并不能让我们从可用的处理能力中获益。因此,在部署应用程序时,考虑到后台运行的系统服务,必须设置合适的 pod 数量,并为每个 pod 设置足够的资源,以最大限度地提高机器的使用率。因此,我们建议不要将节点的 CPU 使用率提高到 80-90% 以上。.
2.水平自动缩放
幸运的是,Kubernetes 有一个 自动水平缩放功能 来自动监控 CPU 使用情况,并在必要时创建新的 pod 来分配负载。只需执行以下命令即可激活该功能。.
kubectl autoscale deployment mlflow-serving --cpu-percent=80 --min=1 --max=12然后,我们可以使用 kubectl get hpa mlflow-serving, 分析集群响应时间和资源消耗。.
以下实验的目的是观察 Kubernetes 如何自动添加 pod 以优化资源使用并获得更好的响应时间。如下图所示,我们可以将该实验分为三个阶段。.
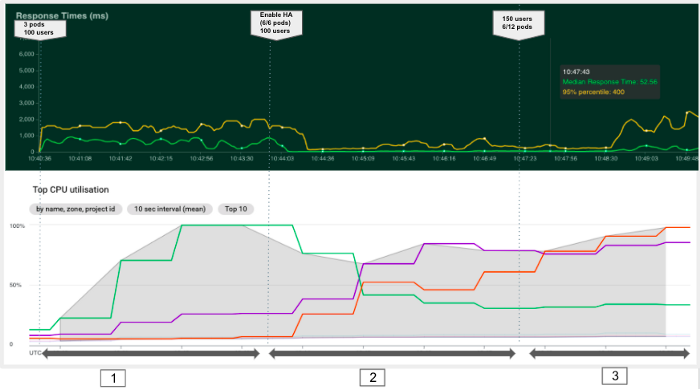
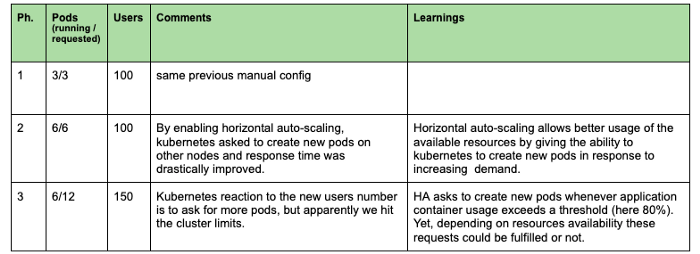
在第二个实验中,我们注意到水平自动扩展使我们能够通过创建新 pod 和分配更多集群资源来缩短响应时间。但是,当达到集群容量时(第三阶段),新的 pod 仍处于待处理状态,我们的响应时间再次增加。.
3.垂直自动缩放
在这种情况下,我们可以探索 Kubernetes 的另一个功能,即 垂直自动缩放 该功能包括在需要时分配更多节点。可使用以下命令激活该功能,指定 Kubernetes 可分配的最小和最大节点数。.
gcloud 容器群集更新 mlflow-k8s
--启用自动扩展 --min-nodes 3 --max-nodes 5 --node-pool POOL_NAME最后,在下图总结的最后一个实验中,启用垂直自动缩放功能后,Kubernetes 可以自动添加两个新节点并创建新 pod 来调度负载,确保更短的响应时间。实际上,Kubernetes 检测到需求并创建资源(第 2 阶段)大约需要 1 分钟。此外,在负载较低的情况下(第 3 阶段),Kubernetes 通过杀死 pod 成功释放了两个新节点,并在大约 15 分钟内将集群缩减到最少 3 个节点。.
4.集群规模估算
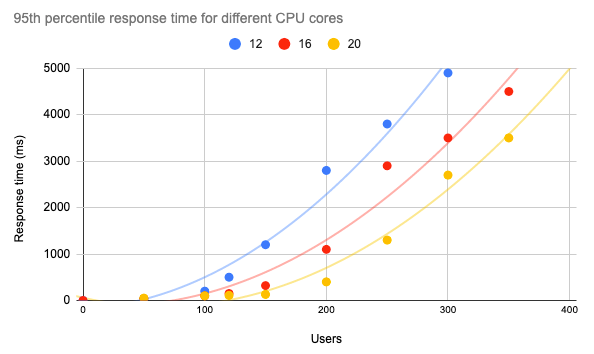
既然我们已经了解了 Kubernetes 在使用纵向和横向自动缩放功能响应不同收费水平时的表现,那么最终的步骤就是使用不同的资源执行性能测试,同时考虑到我们应用程序的要求及其用户数量的估计。假设要满足 SLA 要求,第 95 百分位数响应时间应低于 1 秒。在这种情况下,我们可以绘制下图,显示不同内核数下的 API 响应时间,从而了解应用程序在不同条件下的性能。.
特别是,对于使用 Mlflow 服务的 ML 模型,我们可以在 12 个内核的 Kubernetes 集群上同时容纳约 120 个用户,并保证响应时间低于 1 秒。.
结论
在这一系列文章中,我们经历了在 Kubernetes 引擎上部署 Mlflow 跟踪实例并将模型作为 API 服务的整个过程,从而充分利用了其轻松扩展和处理高负载的能力。我们还尝试了 Kubernetes 提供的两个有趣功能,即水平和垂直自动缩放,并展示了监控资源以确保高效使用资源的重要性。最后,我们展示了如何测试我们的应用程序,并根据其对不同测试场景的响应做出有关基础设施的决策。.

