

Autor

5 dicas para levar em conta o data promocional
TL;DR
Neste próximo artigo de uma grande série de postagens dedicadas à previsão de demanda, vamos nos concentrar em como modelar promoções, um fator-chave na previsão de vendas, analisando a aparência de um dataset promocional típico, como os recursos devem ser criados, com um exemplo passo a passo em Python, e como a granularidade promocional complexa pode ser tratada.
Contexto
Ao prever a demanda como varejistas, muitas vezes podemos aproveitar várias fontes data úteis, como histórico de vendas, hierarquias de produtos e clientes, feriados, vendas e promoções. É importante prestar atenção especial a essa última, pois, na vida real, a atividade promocional costuma ser muito mais do que apenas um sinalizador fictício que o senhor deve adicionar como um recurso ao seu modelo. Trata-se de um mecanismo comercial realmente complexo que pode gerar desempenho adicional ao seu modelo se for bem processado.
Dica 1: Entendendo os referenciais de promoções
O dataset de vendas geralmente não inclui o data promocional. O senhor precisa inserir um referencial específico em seu data de treinamento. O data promocional geralmente vem como um conjunto de colunas, no formato de um plano de promoção com características de promoção como:
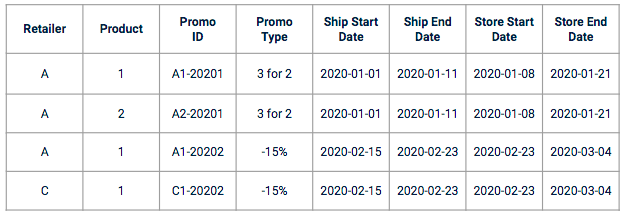
Exemplo de promoção data
Antes de iniciar as partes de engenharia e modelagem de recursos, é recomendável realizar entrevistas com os proprietários de negócios para entender como as promoções são criadas e tratadas. Vejamos o exemplo das datas. No caso de uma previsão de venda, uma promoção será associada a várias datas:
É realmente importante entender quais datas afetam mais a variável-alvo e verificar com os proprietários de negócios se há alguma especificidade a ser considerada (por exemplo, se alguns varejistas podem aplicar as promoções antes ou depois das datas oficiais de início e término).
A realização da Análise Exploratória Data (EDA) pode ajudar o senhor a entender as flutuações e o impacto que as promoções podem ter sobre a variável-alvo. Por exemplo, abaixo é possível ver que um determinado tipo de promoção tem um impacto maior do que outros.
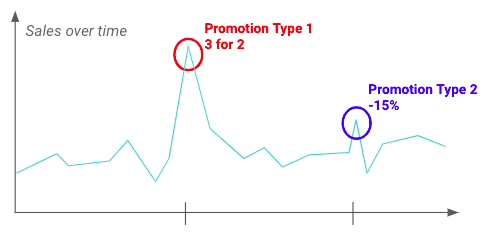
Exemplo do impacto de duas promoções diferentes nas vendas de um determinado produto
A EDA também pode ser realizada para validar insights previamente destacados pelas equipes de negócios. Abaixo, parece que os varejistas estão iniciando as promoções bem antes da data oficial de início.
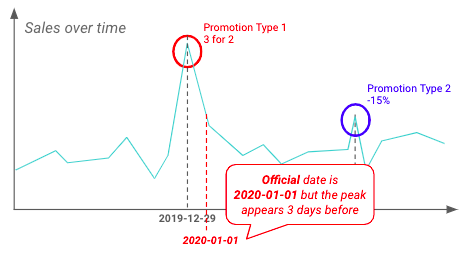
Exemplo de diferença entre a data oficial e a data real de início das promoções
Após a exploração, precisamos processar a promoção bruta data para que ela possa ser usada. As datas precisam primeiro ser expandidas e processadas para que haja uma linha do tempo contínua. Algumas delas podem precisar ser alteradas com base no que foi encontrado durante as fases de exploração e entrevista comercial.
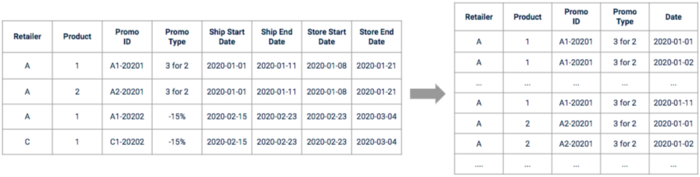
Ilustração da promoção data antes e depois do pré-processamento
Dicas 2: Escolhendo a granularidade correta
Como o seu EDA mostrará, os impactos das promoções diferem muito entre produtos, varejistas (ou lojas, se o senhor estiver trabalhando com data de sell-out) e tipos de promoções. Idealmente, o senhor gostaria de ser o mais preciso possível e manter uma granularidade de SKU x varejista x tipo de promoção.
Por exemplo, o senhor pode ter duas granularidades geográficas diferentes: varejista e depósito (ou seja, um depósito contém vários varejistas). Ao traçar a série temporal em cada granularidade, o senhor pode descobrir que o impacto da promoção é realmente visível no nível do varejista, mas parece suavizado para os depósitos. Isso pode ser explicado pelo fato de que nem todos os varejistas de um depósito são afetados pela promoção da mesma forma. Portanto, nesse exemplo, é preferível trabalhar com a granularidade do varejista.
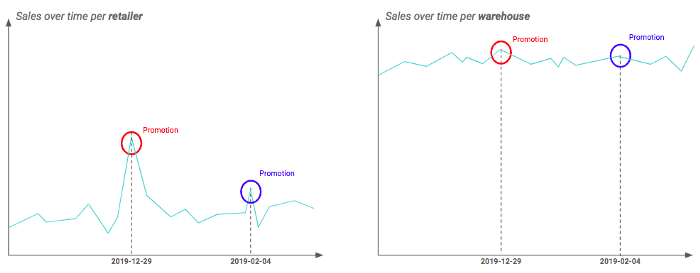
Diferença do impacto da promoção dependendo da granularidade
Depois que a EDA tiver sido feita e a promoção data estiver na granularidade certa, o objetivo é criar os recursos mais relevantes para futuras promoções planejadas para as quais queremos prever as vendas associadas.
Dica 3: Criando os recursos certos
As pessoas podem pensar que basta adicionar uma variável dummy em seu dataset de treinamento. Isso funciona para orientar o modelo na compreensão do motivo pelo qual a demanda ou as vendas são maiores em um determinado momento. No entanto, essa é uma maneira muito ruim de modelar como a promoção pode afetar as vendas. Normalmente, alguns tipos de promoção podem ser mais eficientes do que outros, o impacto das promoções também pode ser maior perto da data de início e menor depois (já que restam poucas pessoas que poderiam se beneficiar da redução).
Um recurso mais sofisticado que consideramos útil ao usar algoritmos de reforço é calcular as médias de rolagem de vendas para dar ao seu modelo insights sobre o sucesso de cada tipo de promoção no passado.
1. Teoria
A ideia por trás desse tipo de recurso é medir, para uma determinada promoção, o volume médio gerado recentemente por “promoções semelhantes” no passado. Vamos calcular o sell-in médio histórico em um escopo semelhante (mesmo tipo de promoção, mesmo SKU, mesmo varejista) em uma janela contínua com um determinado horizonte (por exemplo, nos últimos sete dias).
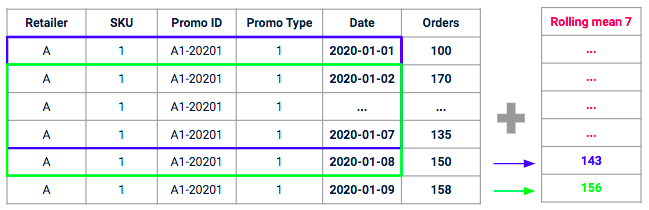
Exemplo de uma média móvel com uma janela de 7 dias
Para esse tipo de recurso, deve-se prestar atenção especial ao vazamento de data, especialmente ao definir o horizonte de tempo.
2. Implementação do Python
Vamos ver como implementar um recurso de média móvel de 7 dias passo a passo em Python. Em primeiro lugar, vamos definir nosso DataFrame com as seguintes informações:
# Inicialize nosso exemplo dataframe com 6 colunas: sku, varejista, tipo de promoção,
# identificação da promoção, data, venda
df = pd.DataFrame(
)
# Inicialize nosso horizonte: média móvel de 7 dias
horizonte = 7
# Adicione uma linha "no futuro" para a qual queremos prever a venda (desconhecida para
# agora) e, portanto, para o qual queremos ter um valor para o recurso de média móvel
df = df.append(
,
ignore_index=True
)
Uma vez criado, nosso DataFrame tem a seguinte aparência:
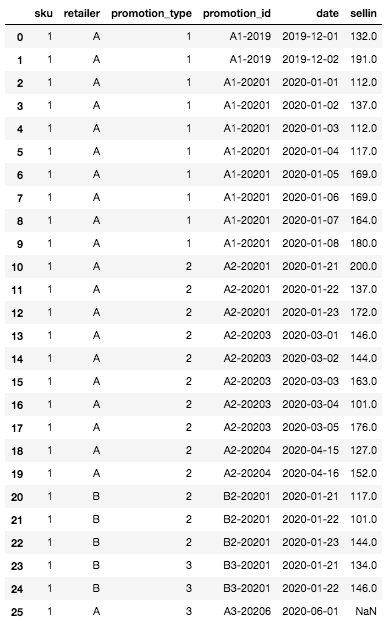
Quadro inicial DataFrame
Em seguida, criaremos duas colunas importantes: a data de início da promoção e a média móvel (vazio por enquanto).
# Criamos duas novas colunas:
# - a data promocional mínima (data de início com base no ID da promoção)
df = df.merge(
df.groupby(["sku", "retailer", "promotion_id"]).date.min()
.reset_index()
.rename(columns=),
on=["sku", "retailer", "promotion_id"],
how="left"
)
df = df.sort_values("min_promo_date")
# - o recurso de média móvel, preenchido com NaN no momento
df['promo_rolling_mean'] = np.nan
Agora, o DataFrame deve ter a seguinte aparência:
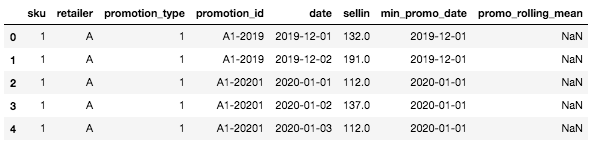
Cabeça do quadro DataFrame com as duas novas colunas
A partir daí, podemos começar a preencher a coluna promo_rolling_mean. Lembre-se de que o objetivo é calcular a média de vendas de promoções semelhantes anteriores, mas a noção de similaridade pode ser complicada. Na melhor das hipóteses, temos em nosso histórico uma promoção com o mesmo tipo, para o mesmo varejista, para a mesma SKU. Na pior das hipóteses, há uma nova promoção com um novo tipo para a qual não temos nenhum histórico para nenhuma SKU, nenhum varejista. Portanto, a ideia é definir vários níveis de granularidade para os quais veremos se temos um histórico e, portanto, a possibilidade de calcular uma média móvel, começando do nível mais granular (por exemplo, SKU x varejista x tipo de promoção) até o nível menos granular (por exemplo, SKU).
Por exemplo, vamos considerar SKU: 1, varejista: A, tipo de promoção: 1, data: 2020-01-01. Procuramos uma promoção semelhante no passado. Para nossa sorte, houve uma promoção com o mesmo tipo de promoção, para a mesma SKU, o mesmo varejista (ou seja, o nível mais granular) em 2019 (promotion_id = ‘A1-2019’). Assim, usaremos a média de vendas para as sete datas mais recentes em que esse tipo de promoção ocorreu. Em outros casos, talvez não encontremos nenhuma correspondência para essa granularidade, portanto, procuraremos uma correspondência apenas por SKU e tipo de promoção. Mais uma vez, se não houver correspondência, finalmente obteremos a média apenas no nível da SKU.
# Definição dos níveis de granularidade para calcular as médias móveis, a partir do nível mais granular
# para o menos granular
AGG_LEVELS =
# Iteramos nos níveis de granularidade (do mais granular para o menos granular) em
# para calcular a média móvel da promoção mais semelhante para cada linha
para agg_level_number, agg_level_columns em AGG_LEVELS.items():
# Quando o recurso de média móvel é preenchido, saímos do loop
Se df["promo_rolling_mean"].isna().sum() == 0:
quebra
# (1) Agregamos nosso quadro data ao nível de granularidade atual
agg_level_df = df.groupby(["promotion_id"] + agg_level_columns)
.agg()
.reset_index()
.rename(columns=)
.dropna(subset=["sellin"])
.sort_values("min_promo_date")
# (2) Calculamos a média móvel no horizonte determinado para a granularidade atual
Nível #
agg_level_df["sellin"] = agg_level_df.groupby(agg_level_columns)
.rolling(horizon, 1)["sellin"]
.mean()
.droplevel(
level=list(
range(len(agg_level_columns))
)
)
# (3) Mesclamos os resultados com o quadro principal data nas colunas da direita e min promo
#. Usamos o merge_asof para obter apenas médias móveis calculadas para datas anteriores a cada
# data de observação.
df = pd.merge_asof(
df,
agg_level_df,
by=agg_level_columns,
on="min_promo_date",
direction="backward",
suffixes=(None, f"_"),
allow_exact_matches=False
)
# Preenchemos o recurso com os valores de média móvel para o nível de granularidade atual
df["promo_rolling_mean"] = df["promo_rolling_mean"].fillna(
df[f "sellin_"])
cols_to_keep = [
"sku", "retailer", "promotion_type", "promotion_id", "date",
"sellin", "promo_rolling_mean"
]
df = df[cols_to_keep].sort_values(
by=['sku', 'retailer', 'promotion_type', 'promotion_id', 'date'])
No final do loop for, ao mesclar esse novo recurso com o conjunto de trens, o usuário deve prestar atenção no vazamento data e usar somente as médias móveis calculadas para datas anteriores a cada data de observação (a data para a qual o usuário deseja fazer previsões). Aqui, decidimos usar o método merge_asof. Isso nos permite mesclar dois conjuntos data evitando correspondências exatas. A ideia por trás disso é: não usar a correspondência de data exata (com o parâmetro allow_exact_matches=False), mas usar as anteriores (com o parâmetro direction=”backward”).
Veja como ficou o nosso dataset com o recurso de média móvel preenchido após essa etapa:
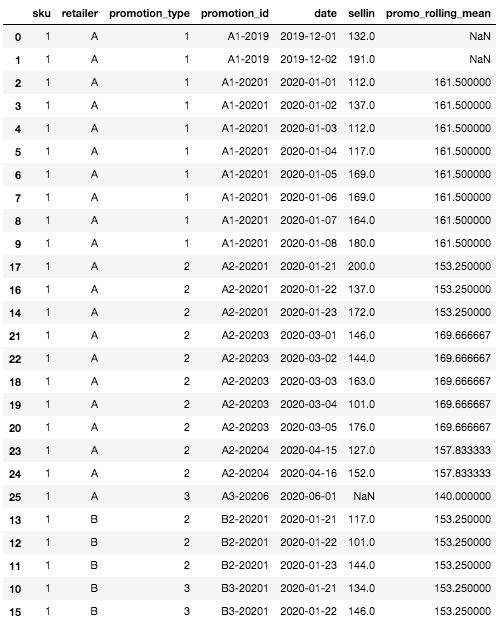
Quadro final DataFrame com o recurso de média móvel
Primeiramente, podemos ver que há alguns valores ausentes para o recurso de média móvel na parte superior do DataFrame. Isso é normal e se deve ao fato de que, nas primeiras linhas, não temos nenhum histórico de nenhuma SKU, nenhum varejista e, portanto, nenhuma possibilidade de calcular uma média móvel. Esse é o único caso em que a média móvel estará vazia; qualquer outro caso pode ser tratado pela definição dos níveis de agregação de granularidade.
Por exemplo, para a linha específica que definimos no início (SKU: 1, Varejista A, Tipo de promoção: 3, Data: 2020-06-01), aquela para a qual ainda não sabemos a venda, o valor da média móvel será a média da venda da promoção mais semelhante e recente. Em nosso caso, não há histórico para o tipo de promoção 3 para o varejista A, mas há para o varejista B. Portanto, o valor da média móvel será a média de sell-in para SKU=1, Tipo de promoção= 3, Varejista=B, aqui: mean([134, 146]) = 140.
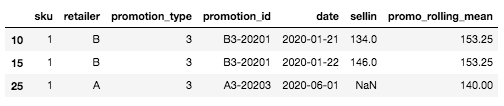
Exemplo de um novo tipo de promoção para um casal SKU x varejista
Essa lógica pode ser estendida a vários outros casos que podem ser encontrados nesse tipo de projeto. Por exemplo, poderia ser criado um nível adicional que seria a família do produto e que poderia ser usado no caso de não haver histórico para um determinado produto. Nesse caso, faremos a média com base nos produtos pertencentes à mesma família. Portanto, é importante pensar sobre esses níveis de granularidade e priorizá-los de acordo com sua própria definição de “similaridade de promoção”, que pode ser baseada em seu EDA ou em insights comerciais, por exemplo.
Em vez das médias móveis, o senhor também pode medir o aumento promocional (ou seja, o volume adicional gerado por uma determinada promoção) para um determinado produto e um determinado cliente. A ideia seria calcular uma proporção entre as vendas durante uma determinada promoção e as vendas sem nenhuma promoção.
Dicas 4: Como lidar com o data grande
Trabalhar com esse nível de granularidade pode aumentar drasticamente a complexidade e a necessidade de poder computacional. Se, como nós, o senhor estiver lidando com centenas de SKUs, varejistas e vários anos de histórico diário de vendas, será essencial encontrar uma maneira de paralelizar os cálculos. Por exemplo, se o senhor não precisar obter informações de outras SKUs para seus recursos de promoção, poderá particionar seu data na coluna sku e usar a computação distribuída. Achamos útil usar o Dask para essa tarefa:
from dask import delayed, compute
def compute_rolling_mean(df):
...
retornar df
skus_list = set(df[‘sku’])
dfs_with_promo = [
delayed(compute_rolling_mean)(df.loc[df.sku == sku]) for sku in skus_list
]
df_final = pd.concat(compute(*dfs_with_promo), axis=0, ignore_index=True)
Dicas 5: Levando em conta as transferências de demanda entre produtos
Não se esqueça de que as vendas de cada SKU serão afetadas por suas promoções, mas também por promoções de produtos substitutos, fenômeno esse conhecido como canibalização. Para que o modelo tenha um bom desempenho, é obrigatório prever o potencial de queda em alguns produtos resultante da canibalização.
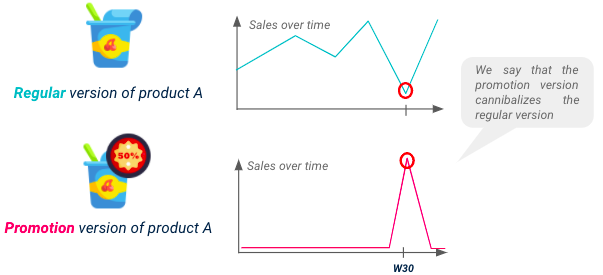
Ilustração de canibalização
Para podermos modelar o fenômeno, primeiro precisamos detectar as relações de canibalização entre os produtos. É possível distinguir duas abordagens principais:
Detecção automática de mergulho profundo
Uma possibilidade de detectar automaticamente as relações de canibalização é usar as pontuações de correlação. A ideia é reunir os produtos que realmente têm probabilidade de canibalizar uns aos outros, não com base em sua categoria, mas com base nas correlações entre a evolução de suas vendas históricas. As pontuações de correlação são calculadas para cada par de produtos e, se forem fortemente negativas, podemos presumir que esses produtos estão se canibalizando mutuamente
Mergulho profundo nos recursos de canibalização
A partir dessas relações de canibalização, podemos criar recursos seguindo a mesma abordagem das promoções diretas. Por exemplo:
Resultados e conclusões
Em nossos projetos, observamos que, na maioria dos casos, os recursos de média móvel tendem a funcionar melhor para o modelo do que os recursos de elevação/redução. Por exemplo, para um determinado país, os recursos de média móvel resultaram em um aumento de 2,8% na precisão da previsão, enquanto os recursos de elevação resultaram em um aumento de 2%.
No entanto, cada projeto é diferente e nosso principal aprendizado é que a fase de exploração é essencial e serve de base para a criação de recursos posteriormente. É necessário entender realmente como as promoções funcionam e seu impacto para poder modelá-las corretamente. Isso envolve discussões com os proprietários da empresa, bem como a Análise Exploratória Data.
