

Auteur

5 tips om beter rekening te houden met promotionele data
TL;DR
In dit volgende artikel van een grote reeks berichten over vraagvoorspelling zullen we ons richten op het modelleren van promoties, een belangrijke factor in verkoopvoorspellingen, waarbij we kijken naar hoe een typische promo dataset eruitziet, hoe kenmerken moeten worden gemaakt, met een stap-voor-stap voorbeeld in Python, en hoe complexe granulariteit van promoties kan worden aangepakt.
Context
Bij het voorspellen van de vraag kunnen wij als detailhandelaren vaak gebruik maken van verschillende nuttige data bronnen, zoals historische verkopen, product- en klantenhiërarchieën, feestdagen, uitverkopen en promoties. Het is belangrijk om vooral aandacht te besteden aan de laatste, omdat in het echte leven promotionele activiteiten vaak veel meer zijn dan alleen maar een dummy vlag die u als functie aan uw model moet toevoegen. Het is een echt complex bedrijfsmechanisme dat uw model extra prestaties kan opleveren als het goed verwerkt wordt.
Tips 1: Promotiereferenties begrijpen
Verkoop dataset bevat vaak geen promo data. U moet een specifieke referentie in uw training data inpluggen. Promotionele data worden vaak geleverd als een set kolommen, in de vorm van een promotieplan met promotiekenmerken zoals:
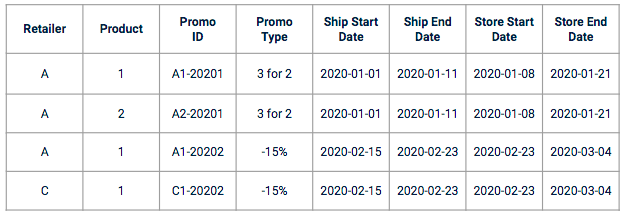
Voorbeeld van promotie data
Voordat u begint met feature engineering en modellering, is het aan te raden om interviews te houden met de bedrijfseigenaren om te begrijpen hoe promotie wordt gemaakt en afgehandeld. Laten we het voorbeeld van datums nemen. In het geval van een verkoopvoorspelling wordt een promotie geassocieerd met verschillende data:
Het is echt belangrijk om te begrijpen welke datums de meeste invloed hebben op de doelvariabele en om bij de bedrijfseigenaars na te vragen of er bijzonderheden zijn waarmee rekening moet worden gehouden (bijv. of sommige winkeliers de promoties voor of na de officiële begin- en einddatum toepassen).
Het uitvoeren van verkennende Data analyse (EDA) kan u helpen om de schommelingen en de impact die promoties kunnen hebben op de doelvariabele te begrijpen. Hieronder kunt u bijvoorbeeld zien dat een bepaald type promotie een grotere impact heeft dan andere.
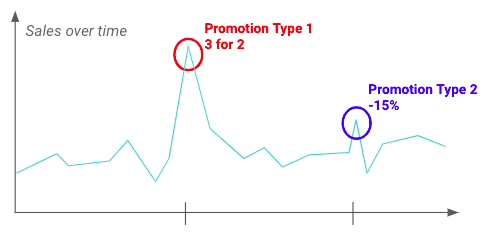
Voorbeeld van het effect van twee verschillende promoties op de verkoop van een bepaald product
EDA kan ook worden uitgevoerd om inzichten te valideren die eerder door bedrijfsteams naar voren zijn gebracht. Hieronder lijkt het erop dat retailers al ruim voor de officiële startdatum met promoties beginnen.
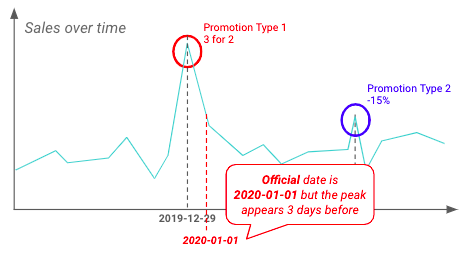
Voorbeeld van verschil tussen officiële en echte begindatum van promoties
Na de verkenning moeten we de onbewerkte promotie data verwerken om deze te kunnen gebruiken. De data moeten eerst uitgebreid en verwerkt worden om een doorlopende tijdlijn te krijgen. Sommige moeten mogelijk verschoven worden op basis van wat er gevonden is tijdens de verkennings- en bedrijfsinterviewfasen.
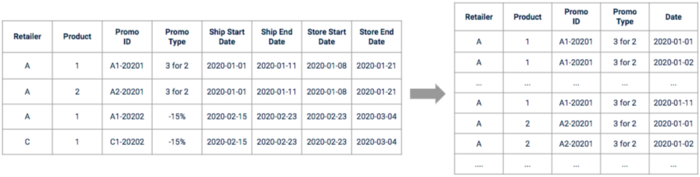
Illustratie van promotie data voor en na voorbewerking
Tips 2: De juiste granulariteit kiezen
Zoals uit uw EDA zal blijken, verschilt de impact van promoties sterk per product, retailer (of winkel als u met uitverkoop data werkt) en promotietype. In het ideale geval wilt u zo nauwkeurig mogelijk zijn en een granulariteit van SKU x detailhandelaar x promotietype aanhouden.
U kunt bijvoorbeeld twee verschillende geografische granulariteiten hebben: detailhandelaar en magazijn (d.w.z. een magazijn bevat meerdere detailhandelaren). Door uw tijdreeksen op elke granulariteit uit te zetten, kunt u erachter komen dat de invloed van promoties echt zichtbaar is op detailhandelsniveau, maar afgevlakt lijkt voor magazijnen. Dit kan worden verklaard door het feit dat niet alle detailhandelaren van een magazijn op dezelfde manier door de promotie worden beïnvloed. Daarom is het in dat voorbeeld beter om op detailhandelsniveau te werken.
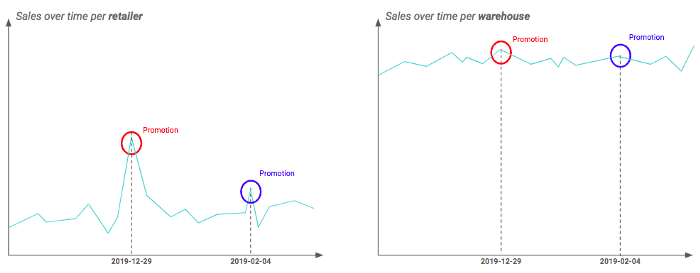
Verschil in de promotie-impact afhankelijk van de granulariteit
Zodra de EDA is uitgevoerd en de promotie data de juiste granulariteit heeft, is het doel om de meest relevante kenmerken te creëren voor toekomstige geplande promoties waarvoor we de bijbehorende verkoop willen voorspellen.
Tips 3: De juiste functies creëren
Mensen denken misschien dat het voldoende is om een dummyvariabele toe te voegen aan uw dataset training. Dit werkt als leidraad voor het model om te begrijpen waarom de vraag of verkoop op een bepaald moment hoger is. Het is echter een heel slechte manier om te modelleren hoe promotie de verkoop beïnvloedt. Gewoonlijk kunnen sommige soorten promoties efficiënter zijn dan andere, de impact van promoties kan ook hoger zijn in de buurt van de startdatum, en lager daarna (omdat er nog maar weinig mensen over zijn die van de korting kunnen profiteren).
Een geavanceerdere functie die wij nuttig vonden bij het gebruik van boostingalgoritmen is het berekenen van voortschrijdende verkoopgemiddelden om uw model inzicht te geven in hoeveel elk promotietype in het verleden succesvol was.
1. Theorie
Het idee achter deze functie is om voor een bepaalde promotie het gemiddelde volume te meten dat recentelijk door “soortgelijke promoties” in het verleden is gegenereerd. We gaan de gemiddelde historische sell-in berekenen op een vergelijkbaar bereik (zelfde promotietype, zelfde SKU, zelfde verkoper) op een voortschrijdend venster met een bepaalde horizon (bijv. op de 7 afgelopen dagen).
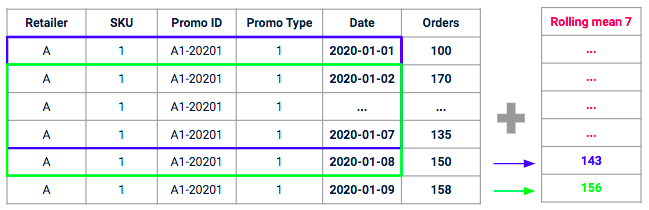
Voorbeeld van een voortschrijdend gemiddelde met een venster van 7 dagen
Voor dit soort functies moet bijzondere aandacht worden besteed aan data lekkage, vooral bij het instellen van de tijdshorizon.
2. Python-implementatie
Laten we eens kijken hoe we stap voor stap een 7-daags voortschrijdend gemiddelde kunnen implementeren in Python. Laten we eerst ons DataFrame definiëren met de volgende informatie:
# Initialiseer ons voorbeeld dataframe met 6 kolommen: sku, verkoper, promotietype,
# promotie-id, datum, verkoopin
df = pd.DataFrame(
)
# Onze horizon initialiseren: 7-daags voortschrijdend gemiddelde
horizon = 7
# Voeg een regel "in de toekomst" toe waarvoor we de verkoop willen voorspellen (onbekend voor
# nu) en waarvoor we dus een waarde willen hebben voor het voortschrijdend gemiddelde kenmerk
df = df.append(
,
ignore_index=waar
)
Eenmaal aangemaakt ziet ons DataFrame er als volgt uit:
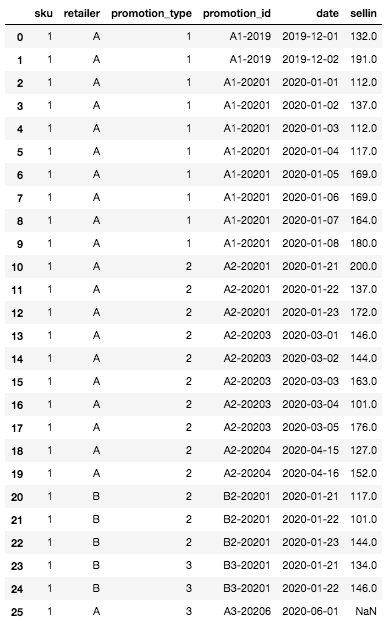
Initieel DataFrame
Vervolgens maken we twee belangrijke kolommen: de begindatum van de promotie en het voortschrijdend gemiddelde (voorlopig leeg).
# We maken twee nieuwe kolommen:
# - de minimale promodatum (begindatum gebaseerd op promotie-ID)
df = df.merge(
df.groupby(["sku", "verkoper", "promotie_id"]).date.min()
.reset_index()
.rename(columns=),
on=["sku", "verkoper", "promotie_id"],
hoe="links"
)
df = df.sort_values("min_promo_date")
# - het voortschrijdend gemiddelde, momenteel gevuld met NaN
df['promo_rolling_mean'] = np.nan
Nu zou het DataFrame er zo uit moeten zien:
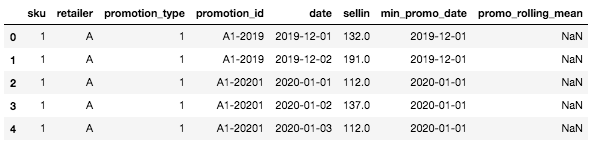
Hoofd van het DataFrame met de twee nieuwe kolommen
Van daaruit kunnen we beginnen met het invullen van de kolom promo_rolling_mean. Onthoud dat het doel is om het gemiddelde van de uitverkoop van eerdere soortgelijke promoties te berekenen, maar het begrip gelijksoortigheid kan lastig zijn. In het beste geval hebben we in onze geschiedenis een promotie met hetzelfde type, voor dezelfde verkoper, voor dezelfde SKU. In het ergste geval is er een nieuwe promotie met een nieuw type waarvoor we geen geschiedenis hebben voor een SKU, een detailhandelaar. Daarom is het idee om verschillende granulariteitsniveaus te definiëren waarvoor we zullen zien of we een geschiedenis hebben en dus een mogelijkheid om een voortschrijdend gemiddelde te berekenen, beginnend vanaf het meest granulaire niveau (bijv. SKU x verkoper x promotietype) tot het minst granulaire niveau (bijv. SKU).
Laten we bijvoorbeeld SKU : 1, verkoper : A, promotietype : 1, datum : 2020-01-01 nemen. We zoeken naar een soortgelijke promotie in het verleden. Gelukkig voor ons is er in 2019 een promotie geweest met hetzelfde promotietype, voor dezelfde SKU, dezelfde verkoper (d.w.z. het meest granulaire niveau) (promotie_id = ‘A1-2019’). We nemen dus het gemiddelde van de verkoop voor de 7 meest recente data waarop dit soort promotie plaatsvond. In andere gevallen vinden we misschien geen overeenkomst voor deze granulariteit, dus zoeken we alleen naar een overeenkomst op SKU en promotietype. Nogmaals, als er geen overeenkomst is, nemen we uiteindelijk alleen het gemiddelde op SKU-niveau.
# Definitie van de granulariteitsniveaus om de voortschrijdende gemiddelden te berekenen, vanaf de meest granulaire
# naar de minder korrelige
AGG_LEVELS =
# We itereren op de granulariteitsniveaus (van meest granulair tot minder granulair) in
# om het voortschrijdend gemiddelde van de meest gelijkende promotie voor elke rij te berekenen
voor agg_level_number, agg_level_columns in AGG_LEVELS.items():
# Zodra het rolgemiddelde is gevuld, verbreken we de lus
als df["promo_rolling_mean"].isna().som() == 0:
break
# (1) We aggregeren ons dataframe tot het huidige granulariteitsniveau.
agg_level_df = df.groupby(["promotie_id"] + agg_level_kolommen)
.agg()
.reset_index()
.rename(kolommen=)
.dropna(subset=["sellin"])
.sort_values("min_promo_date")
# (2) We berekenen het voortschrijdend gemiddelde over de gegeven horizon voor de huidige granulariteit
# niveau
agg_level_df["sellin"] = agg_level_df.groupby(agg_level_columns)
.rolling(horizon, 1)["sellin"]
.mean()
.droplevel(
level=list(
bereik(len(agg_level_columns))
)
)
# (3) We voegen de resultaten samen met het hoofdframe data op de rechterkolommen en min promo
# datum. We gebruiken de merge_asof om alleen voortschrijdende gemiddelden te nemen die berekend zijn voor data vóór elke
# observatiedatum.
df = pd.merge_asof(
df,
agg_level_df,
by=agg_level_columns,
on="min_promo_date",
direction="achteruit",
suffixes=(Geen, f"_"),
allow_exact_matches=False
)
# We vullen de functie met de voortschrijdende gemiddelde waarden voor het huidige granulariteitsniveau
df["promo_rolling_mean"] = df["promo_rolling_mean"].fillna(
df[f"sellin_"])
cols_te_houden = [
"sku", "verkoper", "promotie_type", "promotie_id", "datum",
"sellin", "promo_rolling_mean"."
]
df = df[cols_te_houden].sort_values(
by=['sku', 'verkoper', 'promotie_type', 'promotie_id', 'datum'])
Aan het einde van de for-lus, wanneer u deze nieuwe functie samenvoegt met de treinset, moet u letten op data lekkage en alleen voortschrijdende gemiddelden nemen die zijn berekend voor data vóór elke observatiedatum (de datum waarvoor u voorspellingen wilt doen). Hier hebben we besloten om de methode merge_asof te gebruiken. Hiermee kunnen we twee datasets samenvoegen waarbij exacte overeenkomsten vermeden worden. Het idee erachter is: neem niet de exacte datumovereenkomst (met de parameter allow_exact_matches=False), maar neem de voorgaande (met de parameter direction=”backward”).
Hier ziet onze dataset eruit met de rolling mean-functie gevuld na deze stap:
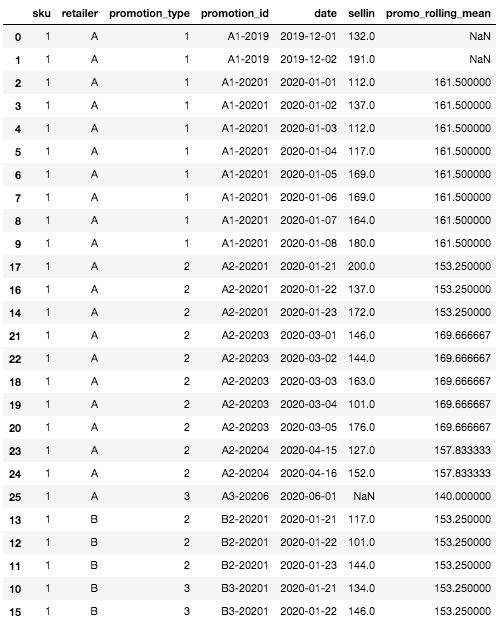
Definitief DataFrame met de functie Rolling Mean
Ten eerste zien we dat er enkele ontbrekende waarden zijn voor het voortschrijdend gemiddelde bovenaan het DataFrame. Dit is normaal en komt doordat we voor de eerste rijen geen geschiedenis hebben voor een SKU, een detailhandelaar, dus geen mogelijkheid om een voortschrijdend gemiddelde te berekenen. Dit is het enige geval waarin het voortschrijdend gemiddelde leeg zal zijn, alle andere gevallen kunnen worden afgehandeld door de definitie van de aggregatieniveaus van de granulariteit.
Bijvoorbeeld, voor de specifieke rij die we aan het begin hebben gedefinieerd (SKU: 1, Verkoper A, Promotietype: 3, Datum: 2020-06-01), waarvan we de sell-in nog niet kennen, is het voortschrijdend gemiddelde het gemiddelde van de sell-in voor de meest vergelijkbare en recente promotie. In ons geval is er geen geschiedenis voor promotietype 3 voor verkoper A, maar wel voor verkoper B. Daarom is het voortschrijdend gemiddelde het gemiddelde van de verkoop voor SKU=1, promotietype=3, verkoper=B, hier: mean([134, 146]) = 140.
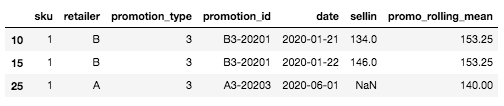
Voorbeeld van een nieuw promotietype voor een paar SKU x detailhandelaar
Deze logica kan worden uitgebreid naar verschillende andere gevallen die in dit soort projecten kunnen voorkomen. Er kan bijvoorbeeld een extra niveau worden gecreëerd dat de productfamilie is en dat kan worden gebruikt als er geen geschiedenis is voor een bepaald product. In dat geval nemen we het gemiddelde op basis van producten die tot dezelfde familie behoren. Het is daarom belangrijk om na te denken over deze granulariteitsniveaus en ze te prioriteren volgens uw eigen definitie van “promotieovereenkomst”, die bijvoorbeeld gebaseerd kan zijn op uw EDA of bedrijfsinzichten.
In plaats van de voortschrijdende middelen kunt u ook de promotionele uplift (d.w.z. het extra volume dat door een bepaalde promotie gegenereerd wordt) voor een bepaald product en een bepaalde klant meten. Het idee is om een verhouding te berekenen tussen de verkoop tijdens een bepaalde promotie en de verkoop zonder promotie.
Tips 4: Omgaan met grote data
Werken op een dergelijk granulariteitsniveau kan de complexiteit en de behoefte aan rekenkracht drastisch verhogen. Als u, zoals wij, te maken hebt met honderden SKU's, detailhandelaren en meerdere jaren aan dagelijkse historische verkoophistoriek, dan is het essentieel om een manier te vinden om berekeningen te parallelliseren. Als u bijvoorbeeld geen informatie van andere SKU's nodig hebt voor uw promotiefuncties, kunt u uw data partitioneren op de sku-kolom en gedistribueerde berekeningen gebruiken. Wij vonden het nuttig om Dask voor deze taak te gebruiken:
van dask importeer vertraagd, berekenen
defute_rolling_mean(df):
...
df teruggeven
skus_list = set(df[‘sku’])
dfs_with_promo = [
vertraagd(compute_rolling_mean)(df.loc[df.sku == sku]) voor sku in skus_list
]
df_final = pd.concat(compute(*dfs_with_promo), axis=0, ignore_index=True)
Tips 5: Rekening houden met vraagoverdracht tussen producten
Vergeet niet dat de verkoop van elk SKU beïnvloed wordt door zijn promoties, maar ook door promoties van substitueerbare producten. Voor een goed presterend model is het verplicht om te anticiperen op de potentiële downlift op sommige producten als gevolg van kannibalisatie.
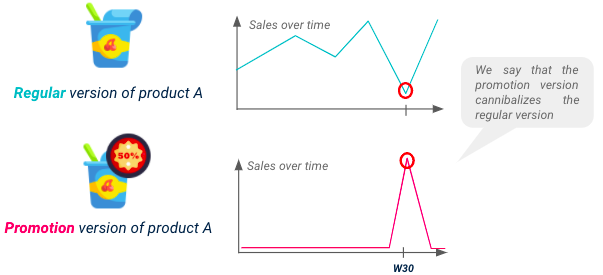
Illustratie van kannibalisatie
Om het fenomeen te kunnen modelleren, moeten we eerst de kannibalisatierelaties tussen producten detecteren. Er kunnen twee hoofdbenaderingen worden onderscheiden:
Automatische detectie diepe duik
Eén mogelijkheid om automatisch kannibalisatierelaties te detecteren is het gebruik van correlatiescores. Het idee is om producten samen te brengen waarvan het echt waarschijnlijk is dat ze elkaar kannibaliseren, niet op basis van hun categorie, maar op basis van correlaties tussen de evolutie van hun historische verkoop. Correlatiescores worden berekend voor elk productpaar en als ze sterk negatief zijn, kunnen we aannemen dat deze producten elkaar kannibaliseren.
Kannibalisatiefuncties diepe duik
Van deze kannibalisatierelaties kunnen we kenmerken maken volgens dezelfde aanpak als voor directe promoties. Bijvoorbeeld:
Resultaten en conclusies
In onze projecten hebben we waargenomen dat in de meeste gevallen de kenmerken van het voortschrijdend gemiddelde beter werkten voor het model dan de kenmerken van de opwaartse en neerwaartse trend. Voor een bepaald land leidden de rolling mean-kenmerken bijvoorbeeld tot een toename van de prognosenauwkeurigheid met 2,8%, terwijl de uplift-kenmerken leidden tot een toename van 2%.
Elk project is echter anders en ons belangrijkste leerpunt is dat de verkenningsfase essentieel is en als basis dient voor het later creëren van features. Het is noodzakelijk om echt te begrijpen hoe promoties werken en wat hun impact is om ze correct te kunnen modelleren. Dit omvat zowel gesprekken met de bedrijfseigenaren als verkennende Data analyse.
