

Autor

5 consejos para tener mejor en cuenta la promoción data
TL;DR
En este siguiente artículo de una amplia serie de posts dedicados a la previsión de la demanda, nos centraremos en cómo modelar las promociones, un factor clave en la previsión de ventas, viendo cómo es una promoción típica dataset, cómo deben elaborarse las características, con un ejemplo paso a paso en Python, y cómo puede tratarse la granularidad promocional compleja.
Contexto
A la hora de prever la demanda como minoristas, a menudo podemos aprovechar varias fuentes data útiles, como el histórico de ventas, las jerarquías de productos y clientes, las vacaciones, las ventas agotadas y las promociones. Es importante prestar especial atención a estas últimas ya que, en la vida real, la actividad promocional suele ser mucho más que una simple bandera ficticia que debería añadir como característica a su modelo. Se trata de un mecanismo comercial realmente complejo que puede aportar un rendimiento adicional a su modelo si se procesa bien.
Consejo 1: Comprender los referentes de las promociones
Las ventas dataset a menudo no incluyen la promoción data. Necesita introducir un referencial específico en su data de formación. El data de promoción suele venir como un conjunto de columnas, en el formato de un plan de promoción con características de promoción como:
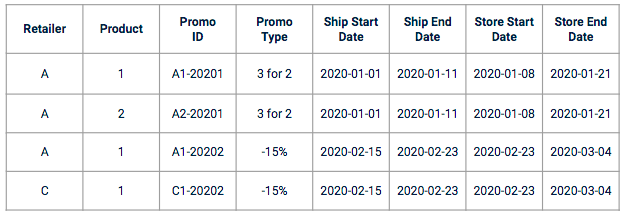
Ejemplo de promoción data
Antes de iniciar las partes de ingeniería de funciones y modelado, se recomienda realizar entrevistas con los propietarios de la empresa para comprender cómo se crean y gestionan los ascensos. Tomemos el ejemplo de las fechas. En el caso de una predicción de venta, una promoción estará asociada a varias fechas:
Es realmente importante entender qué fechas impactan más en la variable objetivo y comprobar con los empresarios si hay especificidades a tener en cuenta (por ejemplo, si algunos minoristas pueden aplicar las promociones antes o después de las fechas oficiales de inicio y fin).
Realizar un Análisis Exploratorio Data (AED) puede ayudarle a comprender las fluctuaciones y el impacto que pueden tener las promociones en la variable objetivo. Por ejemplo, a continuación se puede ver que un tipo concreto de promoción tiene un impacto mayor que otros.
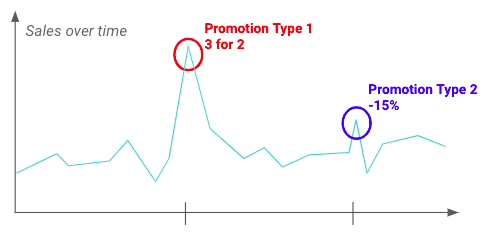
Ejemplo del impacto de dos promociones diferentes en las ventas de un producto determinado
El EDA también puede realizarse para validar las percepciones previamente destacadas por los equipos comerciales. A continuación, parece que los minoristas comienzan las promociones mucho antes de la fecha oficial de inicio.
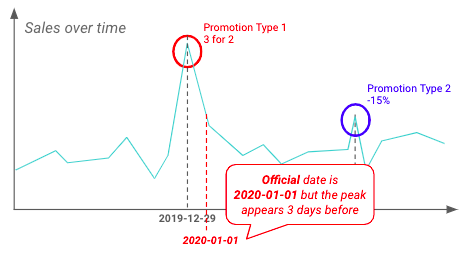
Ejemplo de diferencia entre la fecha oficial y la real de inicio de las promociones
Tras la exploración, tenemos que procesar la promoción bruta data para poder utilizarla. Primero hay que ampliar y procesar las fechas para tener una línea de tiempo continua. Es posible que algunas de ellas deban desplazarse en función de lo que se haya descubierto durante las fases de exploración y entrevista comercial.
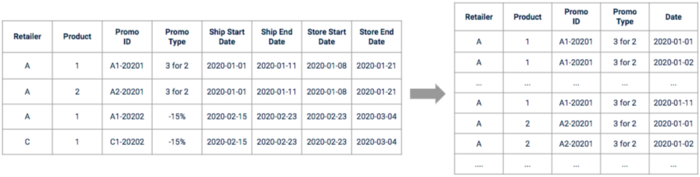
Ilustración de la promoción data antes y después del preprocesamiento
Consejo 2: Elegir la granularidad adecuada
Como mostrará su EDA, los impactos de las promociones difieren mucho entre productos, minoristas (o tiendas si está trabajando con data sell-out), tipos de promociones. Lo ideal sería ser lo más preciso posible y mantener una granularidad SKU x minorista x tipo de promoción.
Por ejemplo, puede tener dos granularidades geográficas diferentes: minorista y almacén (es decir, un almacén contiene varios minoristas). Al trazar sus series temporales en cada granularidad, puede descubrir que el impacto de la promoción es realmente visible a nivel de minorista, pero parece suavizado en el caso de los almacenes. Esto puede explicarse por el hecho de que no todos los minoristas de un almacén se ven afectados por la promoción de la misma manera. Por lo tanto, en ese ejemplo, es preferible trabajar con la granularidad del minorista.
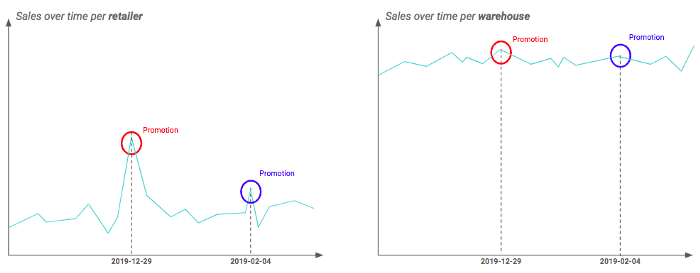
Diferencia del impacto de la promoción en función de la granularidad
Una vez que se ha realizado el EDA y la promoción data tiene la granularidad adecuada, el objetivo es crear las características más relevantes para las futuras promociones planificadas para las que queremos predecir las ventas asociadas.
Consejo 3: Elaborar las características adecuadas
La gente puede pensar que bastará con añadir una variable ficticia en su dataset de formación. Esto funciona para guiar al modelo en la comprensión de por qué la demanda o las ventas son mayores en un momento dado. Sin embargo, es una forma realmente pobre de modelizar cómo puede afectar la promoción a las ventas. Normalmente, algunos tipos de promoción pueden ser más eficientes que otros, el impacto de las promociones también puede ser mayor cerca de la fecha de inicio, menor después (ya que quedan pocas personas que podrían beneficiarse de la reducción).
Una función más sofisticada que encontramos útil cuando se utilizan algoritmos de refuerzo es calcular medias móviles de ventas para dar a su modelo información sobre el éxito que tuvo cada tipo de promoción en el pasado.
1. Teoría
La idea que subyace a este tipo de función es medir, para una promoción determinada, el volumen medio generado recientemente por “promociones similares” en el pasado. Vamos a calcular la venta media histórica en un ámbito similar (mismo tipo de promoción, misma SKU, mismo minorista) en una ventana móvil con un horizonte determinado (por ejemplo, en los 7 últimos días).
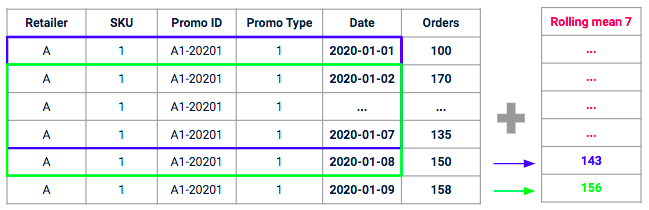
Ejemplo de media móvil con una ventana de 7 días
Para este tipo de características, debe prestarse especial atención a la fuga de data, sobre todo al fijar el horizonte temporal.
2. Implementación de Python
Veamos cómo implementar una función de media móvil de 7 días paso a paso en Python. En primer lugar, definamos nuestro DataFrame con la siguiente información:
# Inicialice nuestro ejemplo dataframe con 6 columnas: sku, minorista, tipo de promoción,
# promoción id, fecha, sellin
df = pd.DataFrame(
)
# Inicializar nuestro horizonte: media móvil de 7 días
horizonte = 7
# Añadir una línea "en el futuro" para la que queremos prever la venta (desconocida para
# ahora) y por lo tanto para el que queremos tener un valor para la característica media rodante
df = df.append(
,
ignore_index=True
)
Una vez creado, nuestro DataFrame tiene el siguiente aspecto:
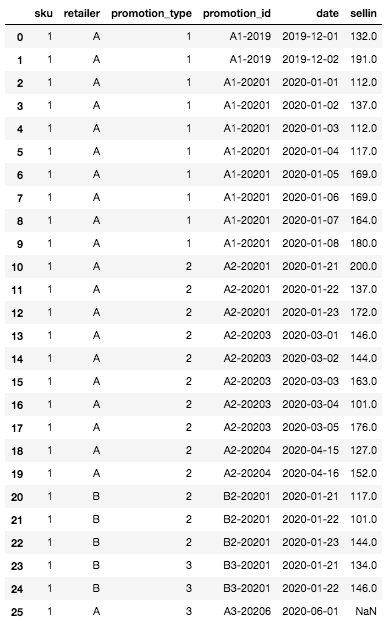
Inicial DataFrame
A continuación crearemos dos columnas importantes: la fecha de inicio de la promoción y la media móvil (vacío por ahora).
# Creamos dos nuevas columnas:
# - la fecha mínima de la promoción (fecha de inicio basada en el ID de la promoción)
df = df.merge(
df.groupby(["sku", "minorista", "promotion_id"]).date.min()
.reset_index()
.rename(columnas=),
on=["sku", "minorista", "promotion_id"],
how="izquierda"
)
df = df.sort_values("min_promo_date")
# - la característica media rodante, rellenada con NaN por el momento
df['promo_rolling_mean'] = np.nan
Ahora, el DataFrame debería tener este aspecto:
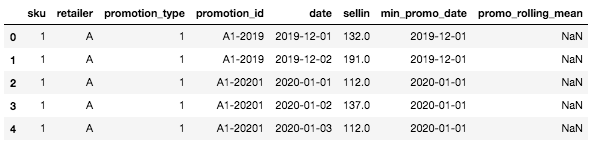
Cabeza del DataFrame con las dos nuevas columnas
A partir de ahí, podemos empezar a rellenar la columna promo_rolling_mean. Recuerde que el objetivo es calcular la media de ventas de promociones anteriores similares, pero la noción de similitud puede ser delicada. En el mejor de los casos, tenemos en nuestro historial una promoción con el mismo tipo, para el mismo minorista, para la misma SKU. En el peor de los casos, hay una nueva promoción con un nuevo tipo para el que no tenemos ningún historial para ninguna SKU, ningún minorista. Por lo tanto, la idea es definir varios niveles de granularidad para los que veremos si tenemos un historial y, por lo tanto, la posibilidad de calcular una media móvil, empezando por el nivel más granular (por ejemplo, SKU x minorista x tipo de promoción) hasta el nivel menos granular (por ejemplo, SKU).
Por ejemplo, tomemos SKU : 1, minorista : A, tipo de promoción : 1, fecha : 2020-01-01. Buscamos una promoción similar en el pasado. Por suerte para nosotros, ha habido una promoción con el mismo tipo de promoción, para la misma SKU, el mismo minorista (es decir, el nivel más granular) en 2019 (promotion_id = ‘A1-2019’). Así pues, tomaremos la media de las ventas de las 7 fechas más recientes en las que se haya producido este tipo de promoción. En otros casos puede que no encontremos ninguna coincidencia para esta granularidad, por lo que buscaremos una coincidencia sólo por SKU y tipo de promoción. De nuevo, si no hay coincidencia, tomaremos finalmente la media sólo a nivel de SKU.
# Definición de los niveles de granularidad para calcular las medias móviles, desde el más granular
# al menos granular
AGG_LEVELS =
# Iteramos sobre los niveles de granularidad (del más granular al menos granular) en
# fin de calcular la media móvil sobre la promoción más similar para cada fila
para agg_número_de_nivel, agg_columnas_de_nivel en AGG_LEVELS.items():
# Una vez rellenada la característica media rodante, rompemos el bucle
if df["promo_rolling_mean"].isna().sum() == 0:
romper
# (1) Agregamos nuestra trama data al nivel de granularidad actual
agg_level_df = df.groupby(["promotion_id"] + agg_level_columns)
.agg()
.reset_index()
.rename(columnas=)
.dropna(subconjunto=["sellin"])
.sort_values("min_promo_date")
# (2) Calculamos la media móvil en el horizonte dado para la granularidad actual
Nivel #
agg_level_df["sellin"] = agg_level_df.groupby(agg_level_columns)
.rolling(horizonte, 1)["sellin"]
.media()
.droplevel(
nivel=list(
range(len(agg_level_columns))
)
)
# (3) Fusionamos los resultados con el marco principal data en las columnas de la derecha y min promo
# fecha. Utilizamos el merge_asof para tomar únicamente medias móviles calculadas para fechas anteriores a cada
# fecha de observación.
df = pd.merge_asof(
df,
agg_level_df,
by=agg_level_columns,
on="min_promo_date",
direction="hacia atrás",
sufijos=(Ninguno, f"_"),
allow_exact_matches=False
)
# Rellenamos la característica con los valores medios móviles para el nivel de granularidad actual
df["promo_rolling_mean"] = df["promo_rolling_mean"].fillna(
df[f "sellin_"])
cols_to_keep = [
"sku", "retailer", "promotion_type", "promotion_id", "date",
"sellin", "promo_rolling_mean"
]
df = df[cols_a_guardar].ordenar_valores(
by=['sku', 'minorista', 'tipo_promoción', 'id_promoción', 'fecha'])
Al final del bucle for, al fusionar esta nueva función con el conjunto de trenes, debe prestar atención a la fuga data y tomar únicamente las medias móviles calculadas para las fechas anteriores a cada fecha de observación (la fecha para la que desea hacer previsiones). En este caso, hemos decidido utilizar el método merge_asof. Éste nos permite fusionar dos conjuntos data evitando las coincidencias exactas. La idea que subyace es la siguiente: no tome la coincidencia de fecha exacta (con el parámetro allow_exact_matches=False), sino las anteriores (con el parámetro direction=”hacia atrás”).
Este es el aspecto de nuestro dataset con la característica de media móvil rellenada después de este paso:
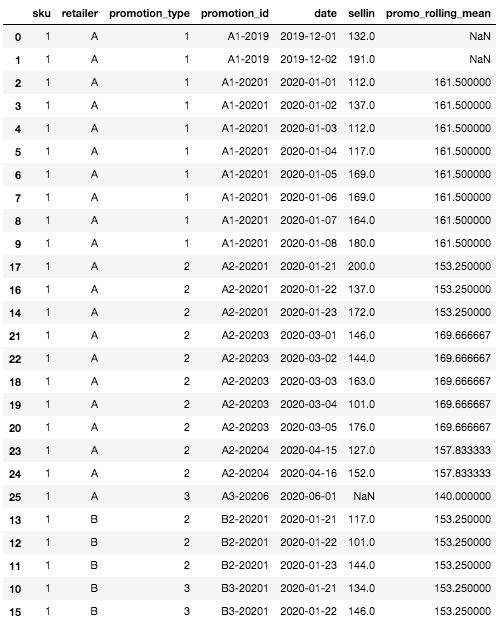
DataFrame final con la función de media móvil
En primer lugar, podemos ver que faltan algunos valores para la característica media rodante en la parte superior del DataFrame. Esto es normal y se debe al hecho de que para las primeras filas, no tenemos ningún historial sobre ninguna SKU, ningún minorista, por lo tanto no hay posibilidad de calcular una media rodante. Este es el único caso en el que la media rodante estará vacía, cualquier otro caso puede manejarse mediante la definición de los niveles de agregación de granularidad.
Por ejemplo, para la fila específica que hemos definido al principio (SKU: 1, Minorista A, Tipo de promoción: 3, Fecha: 2020-06-01), de la que aún no conocemos las entradas, el valor medio rodante será la media de las entradas para la promoción más similar y reciente. En nuestro caso, no hay historial para el tipo de promoción 3 para el minorista A, pero sí para el minorista B. Por lo tanto, el valor medio rodante será la media de entradas vendidas para SKU=1, Tipo de promoción= 3, Minorista=B, aquí: mean([134, 146]) = 140.
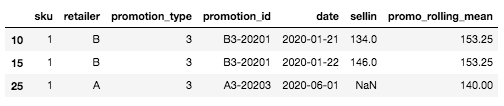
Ejemplo para un nuevo tipo de promoción para una pareja SKU x minorista
Esta lógica puede ampliarse a varios otros casos que pueden darse en este tipo de proyectos. Por ejemplo, se podría crear un nivel adicional que sería la familia de productos y que se podría utilizar en el caso de que no hubiera historial para un producto determinado. En ese caso tomaremos la media basada en los productos pertenecientes a la misma familia. Por lo tanto, es importante pensar en estos niveles de granularidad y darles prioridad en función de su propia definición de “similitud de promoción”, que puede basarse en su EDA o en su visión del negocio, por ejemplo.
En lugar de los medios rodantes, también puede medir el aumento promocional (es decir, el volumen adicional generado por una promoción determinada) para un producto y un cliente determinados. La idea sería calcular una relación entre las ventas durante una promoción determinada y las ventas sin ninguna promoción en su lugar.
Consejos 4: Tratar con grandes data
Trabajar a tal nivel de granularidad puede aumentar drásticamente la complejidad y la necesidad de potencia de cálculo. Si, como nosotros, trabaja con cientos de SKU, minoristas y varios años de histórico diario de ventas, será esencial encontrar una forma de paralelizar los cálculos. Por ejemplo, si no necesita obtener ninguna información de otras SKU para sus características de promoción, puede particionar su data en la columna sku y utilizar la computación distribuida. Nos ha resultado útil utilizar Dask para esta tarea:
from dask import retraso, cálculo
def compute_rolling_mean(df):
...
devolver df
skus_list = set(df[‘sku’])
dfs_con_promo = [
delayed(compute_rolling_mean)(df.loc[df.sku == sku]) for sku in skus_list
]
df_final = pd.concat(compute(*dfs_with_promo), axis=0, ignore_index=True)
Consejo 5: Tener en cuenta las transferencias de demanda entre productos
No olvide que las ventas de cada SKU se verán afectadas por sus promociones, pero también por las promociones de productos sustituibles, este fenómeno se conoce como canibalización. Para disponer de un modelo eficaz, es obligatorio anticipar el descenso potencial de algunos productos como consecuencia de la canibalización.
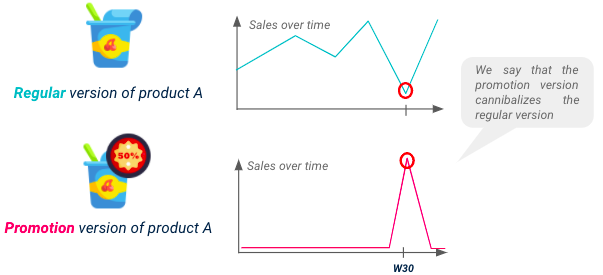
Ilustración de canibalización
Para poder modelizar el fenómeno, primero tenemos que detectar las relaciones de canibalización entre productos. Se pueden distinguir dos enfoques principales:
Inmersión profunda de detección automática
Una posibilidad para detectar automáticamente las relaciones de canibalización es utilizar puntuaciones de correlación. La idea es reunir los productos que realmente tienen probabilidades de canibalizarse entre sí, no en función de su categoría, sino de las correlaciones entre la evolución de sus ventas históricas. Las puntuaciones de correlación se calculan para cada par de productos y si son fuertemente negativas podemos suponer que estos productos se canibalizan entre sí
Características de la canibalización en profundidad
A partir de estas relaciones de canibalización podemos crear características siguiendo el mismo enfoque que para las promociones directas. Por ejemplo:
Resultados y conclusiones
En nuestros proyectos, hemos observado que, en la mayoría de los casos, las características rolling mean tendían a funcionar mejor para el modelo que las características uplift/downlift. Por ejemplo, para un país determinado, las características de media móvil dieron como resultado un aumento de 2,8% en la precisión de las previsiones, mientras que las características de elevación dieron como resultado un aumento de 2%.
Sin embargo, cada proyecto es diferente y nuestro principal aprendizaje es que la fase de exploración es esencial y sirve de base para la creación de características más adelante. Es necesario comprender realmente cómo funcionan las promociones y su impacto para modelarlas correctamente. Esto implica conversaciones con los propietarios de la empresa, así como un análisis exploratorio Data.
