

Auteur

5 conseils pour mieux prendre en compte la promotion data
TL;DR
Dans cet article d'une longue série consacrée à la prévision de la demande, nous allons nous concentrer sur la modélisation des promotions, un élément clé de la prévision des ventes, en examinant à quoi ressemble une promotion typique dataset, comment les caractéristiques doivent être élaborées, avec un exemple étape par étape en Python, et comment une granularité promotionnelle complexe peut être gérée.
Contexte
Lorsque nous prévoyons la demande en tant que détaillants, nous pouvons souvent exploiter plusieurs sources data utiles telles que l'historique des ventes, les hiérarchies de produits et de clients, les jours fériés, les soldes et les promotions. Il est important d'accorder une attention particulière à ces dernières car, dans la réalité, l'activité promotionnelle est souvent bien plus qu'un simple drapeau fictif que vous devriez ajouter comme caractéristique à votre modèle. Il s'agit d'un véritable mécanisme commercial complexe qui peut apporter des performances supplémentaires à votre modèle s'il est bien traité.
Conseils 1 : Comprendre les référentiels de promotion
Les ventes dataset n'incluent souvent pas la promotion data. Vous devez insérer un référentiel spécifique dans votre formation data. Les data promotionnelles se présentent souvent sous la forme d'un ensemble de colonnes, dans le format d'un plan de promotion avec des caractéristiques de promotion telles que :
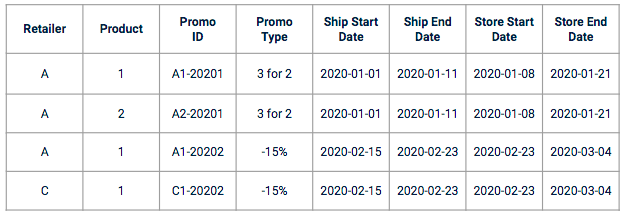
Exemple de promotion data
Avant de commencer l'ingénierie des fonctionnalités et la modélisation, il est recommandé de mener des entretiens avec les responsables de l'entreprise afin de comprendre comment les promotions sont créées et gérées. Prenons l'exemple des dates. Dans le cas d'une prédiction de vente, une promotion sera associée à plusieurs dates :
Il est très important de comprendre quelles sont les dates qui ont le plus d'impact sur la variable cible et de vérifier avec les chefs d'entreprise s'il y a des spécificités à prendre en compte (par exemple, si certains détaillants peuvent appliquer les promotions avant ou après les dates officielles de début et de fin).
L'analyse exploratoire Data (AED) peut vous aider à comprendre les fluctuations et l'impact que les promotions peuvent avoir sur la variable cible. Par exemple, vous pouvez voir ci-dessous qu'un type particulier de promotion a un impact plus important que d'autres.
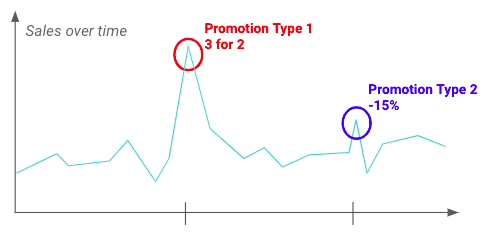
Exemple de l'impact de deux promotions différentes sur les ventes d'un produit donné
L'AED peut également être réalisée pour valider des informations précédemment mises en évidence par les équipes commerciales. Ci-dessous, il semble que les détaillants commencent les promotions bien avant la date officielle.
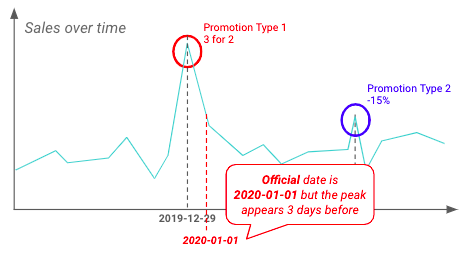
Exemple de différence entre la date officielle et la date réelle de début des promotions
Après l'exploration, nous devons traiter la promotion brute data afin de l'utiliser. Les dates doivent d'abord être développées et traitées afin d'obtenir une chronologie continue. Il se peut que certaines d'entre elles doivent être décalées en fonction de ce qui a été découvert au cours des phases d'exploration et d'entretien avec les entreprises.
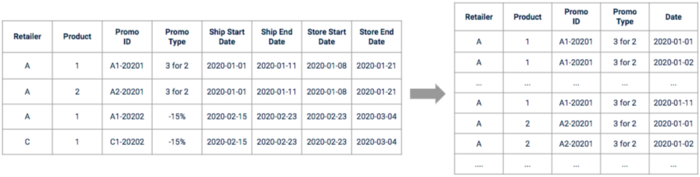
Illustration de la promotion data avant et après le prétraitement
Conseils 2 : Choisir la bonne granularité
Comme le montrera votre EDA, l'impact des promotions varie considérablement selon les produits, les détaillants (ou les magasins si vous travaillez avec des data en rupture de stock) et les types de promotions. Idéalement, vous devriez être aussi précis que possible et conserver une granularité UGS x détaillant x type de promotion.
Par exemple, vous pouvez avoir deux granularités géographiques différentes : le détaillant et l'entrepôt (c'est-à-dire qu'un entrepôt contient plusieurs détaillants). En traçant vos séries temporelles à chaque granularité, vous pouvez constater que l'impact de la promotion est vraiment visible au niveau du détaillant mais semble lissé pour les entrepôts. Cela peut s'expliquer par le fait que tous les détaillants d'un entrepôt ne sont pas touchés par la promotion de la même manière. Par conséquent, dans cet exemple, il est préférable de travailler au niveau des détaillants.
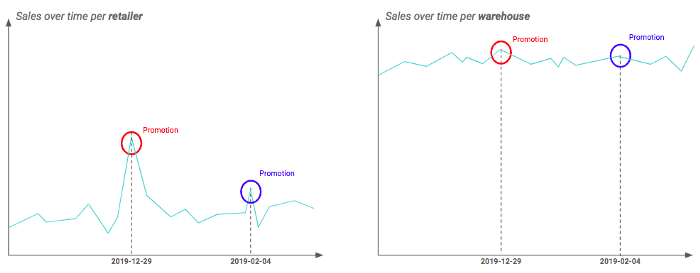
Différence de l'impact de la promotion en fonction de la granularité
Une fois que l'AED a été réalisée et que la promotion data est à la bonne granularité, l'objectif est de créer les caractéristiques les plus pertinentes pour les futures promotions planifiées pour lesquelles nous voulons prédire les ventes associées.
Conseils 3 : Créer les bonnes caractéristiques
On peut penser qu'il suffit d'ajouter une variable fictive dans votre dataset de formation. Cela permet de guider le modèle pour comprendre pourquoi la demande ou les ventes sont plus élevées à un moment donné. Toutefois, il s'agit d'une très mauvaise façon de modéliser l'impact des promotions sur les ventes. En règle générale, certains types de promotion peuvent être plus efficaces que d'autres, l'impact des promotions peut également être plus élevé à proximité de la date de début, et plus faible après (car il reste peu de personnes susceptibles de bénéficier de la réduction).
Une fonction plus sophistiquée que nous avons trouvée utile lors de l'utilisation d'algorithmes de stimulation consiste à calculer les moyennes glissantes des ventes afin de donner à votre modèle des indications sur le succès de chaque type de promotion dans le passé.
1. La théorie
L'idée derrière ce type de fonctionnalité est de mesurer, pour une promotion donnée, le volume moyen récemment généré par des “promotions similaires” dans le passé. Nous allons calculer la moyenne des ventes historiques sur un périmètre similaire (même type de promotion, même SKU, même détaillant) sur une fenêtre glissante avec un horizon donné (par exemple sur les 7 derniers jours).
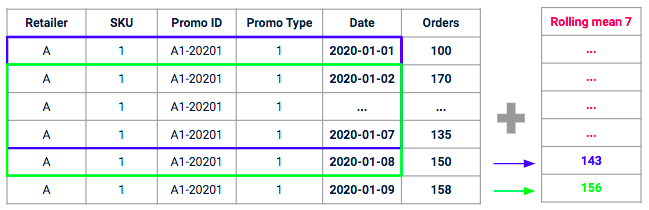
Exemple de moyenne mobile avec une fenêtre de 7 jours
Pour ce type de caractéristiques, il convient d'accorder une attention particulière aux fuites de data, notamment lors de la définition de l'horizon temporel.
2. Mise en œuvre de Python
Voyons comment implémenter une moyenne mobile sur 7 jours, étape par étape, en Python. Tout d'abord, définissons notre DataFrame avec les informations suivantes :
# Initialiser notre exemple dataframe avec 6 colonnes : sku, retailer, promotion type,
# promotion id, date, sellin
df = pd.DataFrame(
)
# Initialiser notre horizon : moyenne mobile sur 7 jours
horizon = 7
# Ajoutez une ligne "dans le futur" pour laquelle nous voulons prévoir le sell-in (inconnu pour
# maintenant) et donc pour laquelle nous voulons avoir une valeur pour la caractéristique de la moyenne glissante
df = df.append(
,
ignore_index=True
)
Une fois créé, notre DataFrame ressemble à ceci :
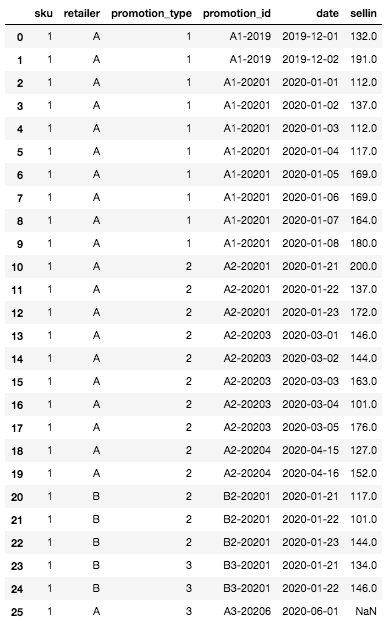
Initial DataFrame
Nous allons ensuite créer deux colonnes importantes : la date de début de la promotion et la moyenne mobile (vide pour l'instant).
# Nous créons deux nouvelles colonnes :
# - la date minimale de la promotion (date de début basée sur l'ID de la promotion)
df = df.merge(
df.groupby(["sku", "retailer", "promotion_id"]).date.min()
.reset_index()
.rename(columns=),
on=["sku", "retailer", "promotion_id"],
how="left"
)
df = df.sort_values("min_promo_date")
# - la fonction de moyenne mobile, remplie de NaN pour le moment
df['promo_rolling_mean'] = np.nan
Maintenant, le DataFrame devrait ressembler à ceci :
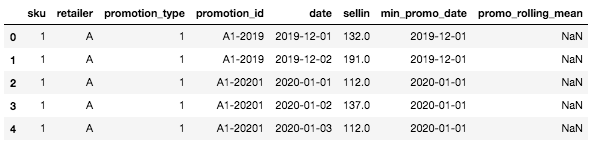
Tête du cadre DataFrame avec les deux nouvelles colonnes
À partir de là, nous pouvons commencer à remplir la colonne promo_rolling_mean. Rappelez-vous que l'objectif est de calculer la moyenne des ventes de promotions similaires précédentes, mais la notion de similarité peut être délicate. Dans le meilleur des cas, nous avons dans notre historique une promotion du même type, pour le même détaillant, pour la même UGS. Dans le pire des cas, il existe une nouvelle promotion d'un nouveau type pour laquelle nous ne disposons d'aucun historique, quelle que soit l'unité de stock ou le détaillant. L'idée est donc de définir plusieurs niveaux de granularité pour lesquels nous verrons si nous disposons d'un historique et donc d'une possibilité de calculer une moyenne mobile, en commençant par le niveau le plus granulaire (par exemple, UGS x détaillant x type de promotion) jusqu'au niveau le moins granulaire (par exemple, UGS).
Par exemple, prenons l'UGS : 1, le détaillant : A, le type de promotion : 1, la date : 2020-01-01. Nous recherchons une promotion similaire dans le passé. Heureusement pour nous, il y a eu une promotion avec le même type de promotion, pour le même SKU, le même détaillant (c'est-à-dire le niveau le plus granulaire) en 2019 (promotion_id = ‘A1-2019’). Nous prendrons donc la moyenne des ventes pour les 7 dates les plus récentes où ce type de promotion a eu lieu. Dans d'autres cas, il se peut que nous ne trouvions pas de correspondance pour cette granularité, nous chercherons donc une correspondance par UGS et par type de promotion uniquement. Là encore, s'il n'y a pas de correspondance, nous prendrons la moyenne au niveau de l'UGS uniquement.
# Définition des niveaux de granularité pour calculer les moyennes glissantes, à partir de la plus granulaire
# à la moins granulaire
AGG_LEVELS =
# Nous itérons sur les niveaux de granularité (du plus granulaire au moins granulaire) en
# afin de calculer la moyenne mobile sur la promotion la plus similaire pour chaque ligne
pour agg_level_number, agg_level_columns dans AGG_LEVELS.items() :
# Une fois que la fonction de moyenne mobile est remplie, nous sortons de la boucle.
si df["promo_rolling_mean"].isna().sum() == 0 :
pause
# (1) Nous agrégeons notre cadre data au niveau de granularité actuel.
agg_level_df = df.groupby(["promotion_id"] + agg_level_columns)
.agg()
.reset_index()
.rename(columns=)
.dropna(subset=["sellin"])
.sort_values("min_promo_date")
# (2) Nous calculons la moyenne glissante sur l'horizon donné pour la granularité actuelle
Niveau #
agg_level_df["sellin"] = agg_level_df.groupby(agg_level_columns)
.rolling(horizon, 1)["sellin"]
.mean()
.droplevel(
level=list(
range(len(agg_level_columns))
)
)
# (3) Nous fusionnons les résultats avec le cadre principal data sur les colonnes de droite et min promo
#. Nous utilisons la fonction merge_asof pour ne prendre que les moyennes glissantes calculées pour les dates antérieures à chaque date.
# date d'observation.
df = pd.merge_asof(
df,
agg_level_df,
by=agg_level_columns,
on="min_promo_date",
direction="backward",
suffixes=(None, f"_"),
allow_exact_matches=False
)
# Nous remplissons la caractéristique avec les valeurs moyennes glissantes pour le niveau de granularité actuel.
df["promo_rolling_mean"] = df["promo_rolling_mean"].fillna(
df[f "sellin_"])
cols_to_keep = [
"sku", "retailer", "promotion_type", "promotion_id", "date",
"sellin", "promo_rolling_mean"
]
df = df[cols_à_maintenir].sort_values(
by=['sku', 'retailer', 'promotion_type', 'promotion_id', 'date'])
A la fin de la boucle for, lorsque vous fusionnez cette nouvelle fonctionnalité avec la rame, vous devez faire attention aux fuites data et ne prendre que les moyennes glissantes calculées pour les dates antérieures à chaque date d'observation (la date pour laquelle vous voulez faire des prévisions). Ici, nous avons décidé d'utiliser la méthode merge_asof. Celle-ci nous permet de fusionner deux ensembles data en évitant les correspondances exactes. L'idée est la suivante : ne pas prendre la date exacte (avec le paramètre allow_exact_matches=False), mais prendre les précédentes (avec le paramètre direction=”backward”).
Voici à quoi ressemble notre ensemble dataset avec la caractéristique de moyenne mobile remplie après cette étape :
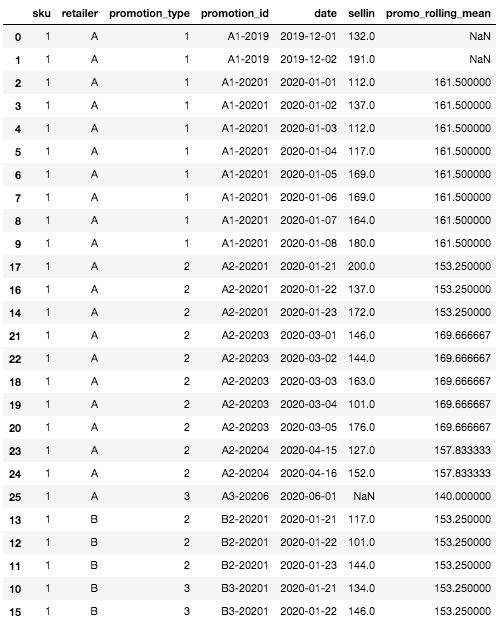
Cadre final DataFrame avec la fonction de moyenne mobile
Nous pouvons tout d'abord constater qu'il y a des valeurs manquantes pour la caractéristique de la moyenne mobile en haut du cadre DataFrame. C'est normal et c'est dû au fait que pour les premières lignes, nous n'avons pas d'historique sur les UGS, ni sur les détaillants, et donc pas de possibilité de calculer une moyenne mobile. C'est le seul cas où la moyenne mobile sera vide, tout autre cas peut être traité par la définition des niveaux d'agrégation de la granularité.
Par exemple, pour la ligne spécifique que nous avons définie au début (SKU : 1, Retailer A, Promotion type : 3, Date : 2020-06-01), celle pour laquelle nous ne connaissons pas encore les ventes, la valeur moyenne glissante sera la moyenne des ventes pour la promotion la plus similaire et la plus récente. Dans notre cas, il n'y a pas d'historique pour la promotion de type 3 pour le détaillant A, mais il y en a un pour le détaillant B. Par conséquent, la valeur moyenne glissante sera la moyenne des ventes pour UGS=1, Type de promotion= 3, Détaillant=B, ici : mean([134, 146]) = 140.
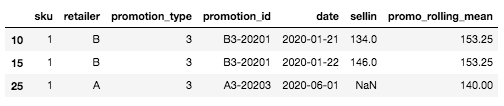
Exemple de nouveau type de promotion pour un couple SKU x détaillant
Cette logique peut être étendue à plusieurs autres cas que l'on peut rencontrer dans ce type de projets. Par exemple, on pourrait créer un niveau supplémentaire qui serait la famille de produits et qui pourrait être utilisé dans le cas où il n'y a pas d'historique pour un produit donné. Dans ce cas, nous prendrons la moyenne basée sur les produits appartenant à la même famille. Il est donc important de réfléchir à ces niveaux de granularité et de les classer par ordre de priorité en fonction de votre propre définition de la “similitude de la promotion”, qui peut être basée sur votre EDA ou sur des informations commerciales, par exemple.
Au lieu des moyens de roulement, vous pouvez également mesurer l'augmentation promotionnelle (c'est-à-dire le volume supplémentaire généré par une promotion donnée) pour un produit donné et un client donné. L'idée est de calculer un ratio entre les ventes réalisées au cours d'une promotion donnée et les ventes réalisées en l'absence de promotion.
Conseils 4 : Faire face aux grandes data
Travailler à un tel niveau de granularité peut augmenter considérablement la complexité et le besoin de puissance de calcul. Si, comme nous, vous avez affaire à des centaines d'unités de vente, à des détaillants et à plusieurs années d'historique quotidien des ventes, il sera essentiel de trouver un moyen de paralléliser les calculs. Par exemple, si vous n'avez pas besoin d'obtenir des informations sur d'autres UGS pour vos promotions, vous pouvez partitionner votre data sur la colonne sku et utiliser le calcul distribué. Nous avons trouvé utile d'utiliser Dask pour cette tâche :
from dask import delayed, compute
def compute_rolling_mean(df) :
...
retour df
skus_list = set(df[‘sku’])
dfs_with_promo = [
delayed(compute_rolling_mean)(df.loc[df.sku == sku]) for sku in skus_list
]
df_final = pd.concat(compute(*dfs_with_promo), axis=0, ignore_index=True)
Conseil 5 : Prise en compte des transferts de demande entre produits
N'oubliez pas que les ventes de chaque UGS seront affectées par ses promotions, mais aussi par les promotions de produits substituables, ce phénomène étant connu sous le nom de cannibalisation. Afin d'avoir un modèle performant, il est obligatoire d'anticiper la baisse potentielle de certains produits résultant de la cannibalisation.
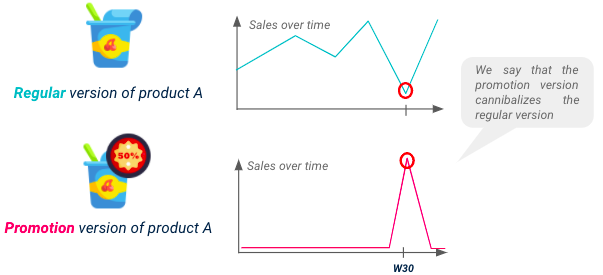
Illustration de la cannibalisation
Pour pouvoir modéliser le phénomène, nous devons d'abord détecter les relations de cannibalisation entre les produits. Deux approches principales peuvent être distinguées :
Détection automatique en profondeur
L'une des possibilités de détecter automatiquement les relations de cannibalisation consiste à utiliser des scores de corrélation. L'idée est de rassembler les produits qui sont réellement susceptibles de se cannibaliser l'un l'autre, non pas sur la base de leur catégorie, mais sur la base des corrélations entre l'évolution de leurs ventes historiques. Les scores de corrélation sont calculés pour chaque paire de produits et s'ils sont fortement négatifs, nous pouvons supposer que ces produits se cannibalisent l'un l'autre.
Les caractéristiques de la cannibalisation en profondeur
À partir de ces relations de cannibalisation, nous pouvons créer des caractéristiques en suivant la même approche que pour les promotions directes. Par exemple, nous pouvons créer des caractéristiques en suivant la même approche que pour les promotions directes :
Résultats et conclusions
Dans nos projets, nous avons observé que, dans la plupart des cas, les caractéristiques de moyenne mobile avaient tendance à mieux fonctionner pour le modèle que les caractéristiques d'élévation et d'abaissement. Par exemple, pour un pays donné, les caractéristiques de la moyenne mobile ont permis d'augmenter la précision des prévisions de 2,8%, tandis que les caractéristiques de l'élévation ont permis d'augmenter la précision des prévisions de 2%.
Cependant, chaque projet est différent et notre principale leçon est que la phase d'exploration est essentielle et sert de base à la création de fonctionnalités par la suite. Il est nécessaire de comprendre réellement le fonctionnement des promotions et leur impact afin de les modéliser correctement. Cela implique des discussions avec les propriétaires de l'entreprise ainsi qu'une analyse exploratoire Data.
