

Autor

5 Tipps zur besseren Berücksichtigung von Werbeaktionen data
TL;DR
In diesem folgenden Artikel einer großen Serie von Beiträgen, die der Nachfrageprognose gewidmet sind, konzentrieren wir uns auf die Modellierung von Promotionen, einem wichtigen Faktor bei der Absatzprognose. Wir sehen uns an, wie ein typisches Promo dataset aussieht, wie die Funktionen gestaltet werden sollten, mit einem Schritt-für-Schritt-Beispiel in Python, und wie man mit komplexer Promotion-Granularität umgehen kann.
Kontext
Wenn wir als Einzelhändler die Nachfrage prognostizieren, können wir oft mehrere nützliche data-Quellen nutzen, z.B. historische Verkaufszahlen, Produkt- und Kundenhierarchien, Feiertage, Ausverkäufe und Werbeaktionen. Letzterem sollten Sie besondere Aufmerksamkeit schenken, denn in der Realität sind Werbeaktionen oft viel mehr als nur ein Dummy-Flag, das Sie als Funktion in Ihr Modell aufnehmen sollten. Es handelt sich um einen wirklich komplexen Geschäftsmechanismus, der Ihrem Modell zusätzliche Leistung verleihen kann, wenn er gut verarbeitet wird.
Tipps 1: Verstehen von Referenzen für Werbeaktionen
Der Verkauf dataset enthält oft keine Promo data. Sie müssen eine spezifische Referenz in Ihr Training data einfügen. Werbeartikel data werden oft als ein Satz von Spalten im Format eines Werbeplans mit Werbemerkmalen wie z.B.:
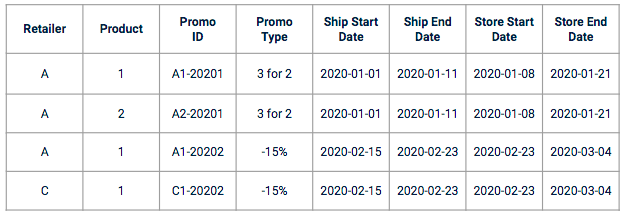
Beispiel einer Werbeaktion data
Bevor Sie mit dem Feature-Engineering und der Modellierung beginnen, empfiehlt es sich, Interviews mit den Geschäftsinhabern zu führen, um zu verstehen, wie Werbung erstellt und gehandhabt wird. Nehmen wir das Beispiel der Termine. Im Falle einer Sell-in-Vorhersage wird eine Promotion mit mehreren Terminen verknüpft sein:
Es ist wirklich wichtig zu verstehen, welche Daten die Zielvariable am meisten beeinflussen und mit den Geschäftsinhabern zu klären, ob es Besonderheiten zu berücksichtigen gibt (z.B. ob einige Einzelhändler die Werbeaktionen vor oder nach den offiziellen Start- und Enddaten durchführen).
Die Durchführung einer explorativen Data-Analyse (EDA) kann Ihnen helfen, die Schwankungen und die Auswirkungen, die Promotions auf die Zielvariable haben können, zu verstehen. Unten sehen Sie zum Beispiel, dass eine bestimmte Art von Werbeaktion einen größeren Einfluss hat als andere.
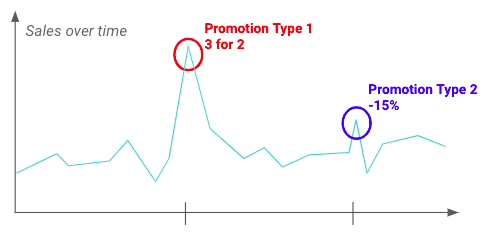
Beispiel für die Auswirkungen von zwei verschiedenen Werbeaktionen auf den Verkauf eines bestimmten Produkts
EDA kann auch durchgeführt werden, um Erkenntnisse zu validieren, die zuvor von Geschäftsteams hervorgehoben wurden. Im Folgenden sehen Sie, dass die Einzelhändler schon lange vor dem offiziellen Starttermin mit der Werbung beginnen.
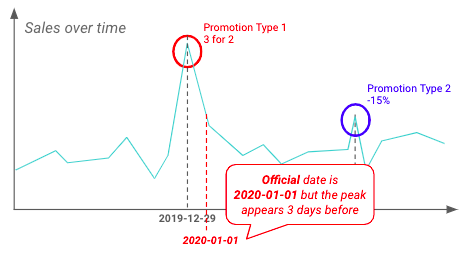
Beispiel für den Unterschied zwischen dem offiziellen und dem tatsächlichen Startdatum einer Beförderung
Nach der Erkundung müssen wir die Rohförderung data verarbeiten, damit sie verwendet werden kann. Die Daten müssen zunächst erweitert und verarbeitet werden, um eine kontinuierliche Zeitleiste zu erhalten. Einige von ihnen müssen möglicherweise verschoben werden, je nachdem, was in der Explorations- und Interviewphase herausgefunden wurde.
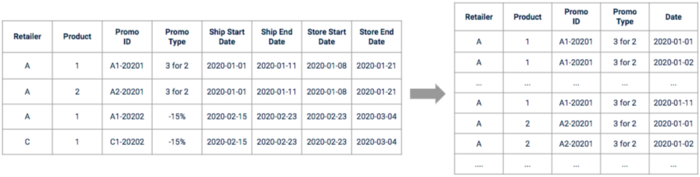
Illustration der Promotion data vor und nach der Vorverarbeitung
Tipps 2: Auswahl der richtigen Granularität
Wie Ihre EDA zeigt, sind die Auswirkungen von Werbeaktionen je nach Produkt, Händler (oder Filiale, wenn Sie mit ausverkauften data arbeiten) und Art der Werbeaktion sehr unterschiedlich. Im Idealfall möchten Sie so genau wie möglich sein und eine Granularität von SKU x Einzelhändler x Aktionsart beibehalten.
Sie können zum Beispiel zwei verschiedene geografische Granularitäten haben: Einzelhändler und Lagerhäuser (d.h. ein Lagerhaus enthält mehrere Einzelhändler). Wenn Sie Ihre Zeitreihen für jede Granularität aufzeichnen, stellen Sie vielleicht fest, dass die Auswirkungen von Werbeaktionen auf der Einzelhändlerebene deutlich sichtbar sind, während sie für Lagerhäuser geglättet erscheinen. Dies lässt sich dadurch erklären, dass nicht alle Einzelhändler eines Lagers in gleicher Weise von der Aktion betroffen sind. Daher ist es in diesem Beispiel besser, auf der Ebene der Einzelhändler zu arbeiten.
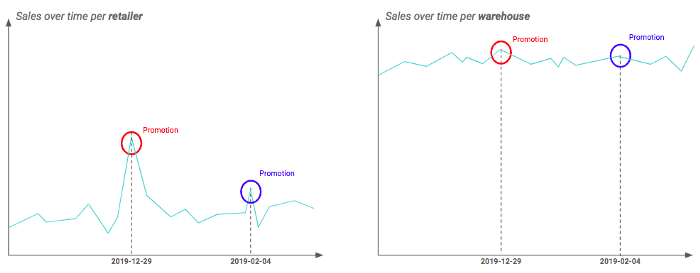
Unterschiedliche Auswirkungen der Beförderung je nach Granularität
Sobald die EDA durchgeführt wurde und die Promotion data die richtige Granularität aufweist, besteht das Ziel darin, die relevantesten Merkmale für zukünftige geplante Promotionen zu erstellen, für die wir die zugehörigen Verkäufe vorhersagen möchten.
Tipps 3: Die richtigen Funktionen entwickeln
Man könnte meinen, dass es ausreicht, eine Dummy-Variable in Ihr Training dataset einzufügen. Dies hilft dem Modell zu verstehen, warum die Nachfrage oder der Umsatz zu einem bestimmten Zeitpunkt höher ist. Es ist jedoch eine sehr schlechte Methode, um zu modellieren, wie sich Werbeaktionen auf den Umsatz auswirken. Typischerweise sind einige Arten von Werbeaktionen effizienter als andere, und die Auswirkungen von Werbeaktionen können in der Nähe des Startdatums höher und danach niedriger sein (da nur noch wenige Menschen von der Preisreduzierung profitieren können).
Eine ausgefeiltere Funktion, die wir bei der Verwendung von Boosting-Algorithmen als nützlich empfunden haben, ist die Berechnung von rollierenden Mittelwerten der Verkäufe, um Ihrem Modell Einblicke darüber zu geben, wie erfolgreich die einzelnen Werbetypen in der Vergangenheit waren.
1. Theorie
Die Idee hinter dieser Art von Funktion ist es, für eine bestimmte Aktion das durchschnittliche Volumen zu messen, das in der Vergangenheit durch “ähnliche Aktionen” erzielt wurde. Wir berechnen den durchschnittlichen historischen Abverkauf in einem ähnlichen Rahmen (gleiche Aktionsart, gleiche SKU, gleicher Händler) in einem rollierenden Fenster mit einem bestimmten Zeithorizont (z.B. für die letzten 7 Tage).
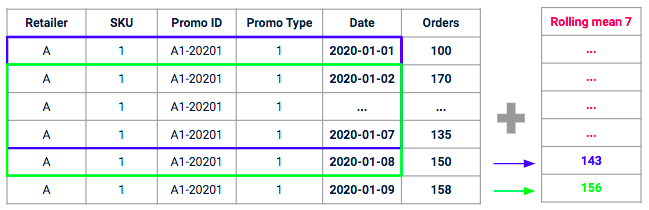
Beispiel für einen gleitenden Mittelwert mit einem 7-Tage-Fenster
Bei dieser Art von Merkmalen sollte ein besonderes Augenmerk auf data Leckage gelegt werden, insbesondere bei der Festlegung des Zeithorizonts.
2. Python-Implementierung
Sehen wir uns an, wie Sie ein 7-Tage-Mittelwert-Feature Schritt für Schritt in Python implementieren. Lassen Sie uns zunächst unseren DataFrame mit den folgenden Informationen definieren:
# Initialisieren Sie unser Beispiel dataframe mit 6 Spalten: sku, retailer, promotion type,
# Aktions-ID, Datum, Verkauf
df = pd.DataFrame(
)
# Initialisieren Sie unseren Horizont: 7-tägiges gleitendes Mittel
Horizont = 7
# Fügen Sie eine Zeile "in der Zukunft" hinzu, für die wir den Sell-in prognostizieren wollen (unbekannt für
# jetzt) und für die wir daher einen Wert für das Merkmal des gleitenden Mittelwerts haben möchten
df = df.append(
,
ignore_index=True
)
Einmal erstellt, sieht unser DataFrame wie folgt aus:
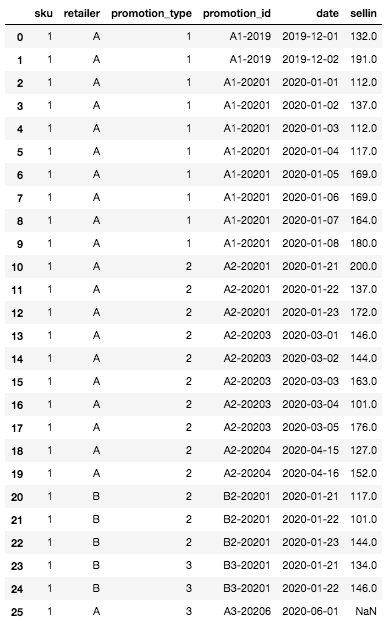
Initial DataFrame
Als Nächstes erstellen wir zwei wichtige Spalten: das Anfangsdatum der Beförderung und den gleitenden Mittelwert (vorerst leer).
# Wir erstellen zwei neue Spalten:
# - das Mindestdatum der Werbeaktion (Startdatum basierend auf der Werbe-ID)
df = df.merge(
df.groupby(["sku", "retailer", "promotion_id"]).date.min()
.reset_index()
.rename(columns=),
on=["sku", "retailer", "promotion_id"],
how="links"
)
df = df.sort_values("min_promo_date")
# - das rollierende Mittelwertmerkmal, vorerst mit NaN gefüllt
df['promo_rolling_mean'] = np.nan
Der DataFrame sollte nun wie folgt aussehen:
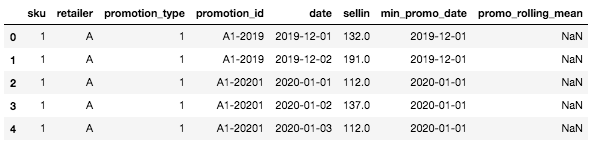
Kopf des DataFrame mit den beiden neuen Säulen
Von dort aus können wir mit dem Ausfüllen der Spalte promo_rolling_mean beginnen. Denken Sie daran, dass das Ziel darin besteht, den Mittelwert der Verkaufszahlen früherer ähnlicher Werbeaktionen zu berechnen, aber der Begriff der Ähnlichkeit kann heikel sein. Im besten Fall haben wir in unserer Historie eine Aktion mit der gleichen Art, für den gleichen Händler, für die gleiche SKU. Im schlimmsten Fall gibt es eine neue Aktion mit einer neuen Art, für die wir keine Historie für irgendeine SKU, irgendeinen Einzelhändler haben. Die Idee ist daher, mehrere Granularitätsebenen zu definieren, für die wir sehen können, ob wir eine Historie haben und somit die Möglichkeit, einen gleitenden Mittelwert zu berechnen, beginnend mit der granularsten Ebene (z.B. SKU x Händler x Aktionsart) bis zur am wenigsten granularen Ebene (z.B. SKU).
Nehmen wir zum Beispiel SKU : 1, Einzelhändler : A, Aktionsart : 1, Datum : 2020-01-01. Wir suchen nach einer ähnlichen Aktion in der Vergangenheit. Glücklicherweise gab es im Jahr 2019 (promotion_id = ‘A1-2019’) eine Aktion mit der gleichen Aktionsart, für die gleiche SKU, den gleichen Einzelhändler (d.h. die granularste Ebene). Wir nehmen also den Mittelwert der Verkaufszahlen für die letzten 7 Termine, an denen diese Art von Aktion stattfand. In anderen Fällen kann es sein, dass wir keine Übereinstimmung für diese Granularität finden, so dass wir nur nach einer Übereinstimmung nach SKU und Aktionsart suchen. Wenn es auch hier keine Übereinstimmung gibt, nehmen wir schließlich nur den Mittelwert auf SKU-Ebene.
# Definition der Granularitätsstufen zur Berechnung des gleitenden Mittelwerts, von der granularsten
# zum weniger granularen
AGG_LEVELS =
# Wir iterieren die Granularitätsstufen (von der granularsten zur weniger granularen) in
#, um den gleitenden Mittelwert für die ähnlichste Werbeaktion für jede Zeile zu berechnen
for agg_level_number, agg_level_columns in AGG_LEVELS.items():
# Sobald das rollierende Mittelwertmerkmal gefüllt ist, brechen wir die Schleife ab.
if df["promo_rolling_mean"].isna().sum() == 0:
Pause
# (1) Wir aggregieren unseren data-Frame auf die aktuelle Granularitätsebene
agg_level_df = df.groupby(["promotion_id"] + agg_level_columns)
.agg()
.reset_index()
.rename(spalten=)
.dropna(subset=["sellin"])
.sort_values("min_promo_date")
# (2) Wir berechnen das gleitende Mittel über den gegebenen Horizont für die aktuelle Granularität
# Niveau
agg_level_df["sellin"] = agg_level_df.groupby(agg_level_columns)
.rolling(horizon, 1)["sellin"]
.mean()
.droplevel(
level=list(
Bereich(len(agg_level_columns))
)
)
# (3) Wir fügen die Ergebnisse mit dem Hauptframe data auf den rechten Spalten und min promo
# Datum. Wir verwenden die Funktion merge_asof, um nur rollierende Mittelwerte zu verwenden, die für Daten vor jedem
# Beobachtungsdatum.
df = pd.merge_asof(
df,
agg_level_df,
by=agg_level_columns,
on="min_promo_date",
direction="rückwärts",
suffixes=(Keine, f"_"),
allow_exact_matches=False
)
# Wir füllen das Merkmal mit den gleitenden Mittelwerten für die aktuelle Granularitätsstufe
df["promo_rolling_mean"] = df["promo_rolling_mean"].fillna(
df[f "sellin_"])
cols_to_keep = [
"sku", "retailer", "promotion_type", "promotion_id", "date",
"sellin", "promo_rolling_mean"
]
df = df[cols_to_keep].sort_values(
by=['sku', 'retailer', 'promotion_type', 'promotion_id', 'date'])
Am Ende der for-Schleife, wenn Sie dieses neue Merkmal mit dem Zugsatz zusammenführen, müssen Sie auf data-Leckagen achten und nur rollierende Mittelwerte verwenden, die für Daten vor jedem Beobachtungsdatum berechnet wurden (das Datum, für das Sie Prognosen erstellen möchten). Wir haben uns hier für die Methode merge_asof entschieden. Damit können wir zwei data-Sets zusammenführen und dabei exakte Übereinstimmungen vermeiden. Die Idee dahinter ist: Nehmen Sie nicht die exakte Datumsübereinstimmung (mit dem Parameter allow_exact_matches=False), sondern die vorherigen (mit dem Parameter direction=”backward”).
Hier sehen Sie, wie unser dataset nach diesem Schritt mit dem Merkmal Rolling Mean gefüllt ist:
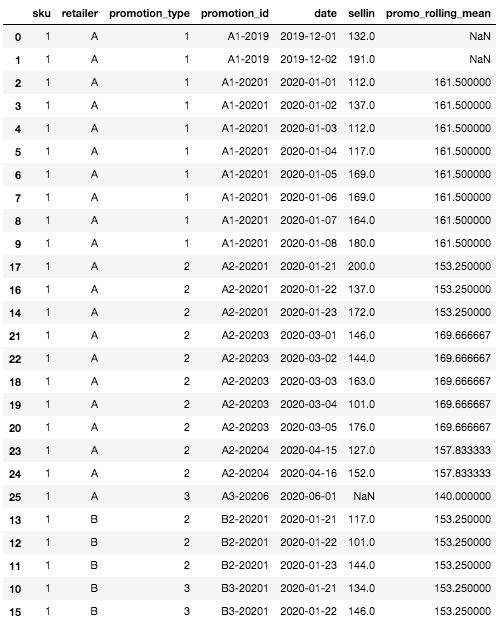
Endgültiger DataFrame mit der Funktion des gleitenden Mittelwerts
Zunächst können wir sehen, dass einige Werte für das Merkmal Rollierender Mittelwert oben im DataFrame fehlen. Das ist normal und liegt daran, dass wir für die ersten Zeilen keine Historie zu einer SKU oder einem Händler haben und daher keine Möglichkeit, einen rollenden Mittelwert zu berechnen. Dies ist der einzige Fall, in dem der rollende Mittelwert leer ist. Alle anderen Fälle können durch die Definition der Granularitätsaggregationsstufen behandelt werden.
Für die spezifische Zeile, die wir zu Beginn definiert haben (SKU: 1, Händler A, Aktionsart: 3, Datum: 2020-06-01), für die wir den Verkaufswert noch nicht kennen, ist der gleitende Mittelwert der Mittelwert des Verkaufswertes für die ähnlichste und jüngste Aktion. In unserem Fall gibt es keine Historie für die Aktionsart 3 für Händler A, aber für Händler B. Daher ist der gleitende Mittelwert der Mittelwert des Sell-in für SKU=1, Aktionsart=3, Händler=B, hier: mean([134, 146]) = 140.
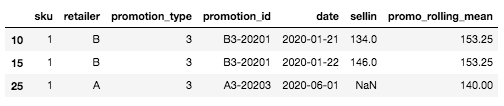
Beispiel für eine neue Aktionsart für ein Paar SKU x Einzelhändler
Diese Logik kann auf verschiedene andere Fälle ausgedehnt werden, die bei dieser Art von Projekten vorkommen können. So könnte zum Beispiel eine zusätzliche Ebene geschaffen werden, die die Produktfamilie darstellt und für den Fall verwendet werden könnte, dass es für ein bestimmtes Produkt keine Historie gibt. In diesem Fall nehmen wir den Durchschnitt auf der Grundlage der Produkte, die zu derselben Familie gehören. Es ist daher wichtig, über diese Granularitätsebenen nachzudenken und sie entsprechend Ihrer eigenen Definition von “Werbeähnlichkeit” zu priorisieren, die z.B. auf Ihrer EDA oder Ihren Geschäftserkenntnissen basieren kann.
Anstelle des rollierenden Mittels können Sie auch den Aktions-Uplift (d.h. das zusätzliche Volumen, das durch eine bestimmte Aktion generiert wird) für ein bestimmtes Produkt und einen bestimmten Kunden messen. Die Idee ist, ein Verhältnis zwischen den Verkäufen während einer bestimmten Promotion und den Verkäufen ohne Promotion zu berechnen.
Tipps 4: Der Umgang mit großen data
Die Arbeit auf einer solchen Granularitätsebene kann die Komplexität und den Bedarf an Rechenleistung drastisch erhöhen. Wenn Sie wie wir mit Hunderten von SKUs, Einzelhändlern und mehreren Jahren täglicher historischer Verkaufszahlen zu tun haben, müssen Sie unbedingt einen Weg finden, die Berechnungen zu parallelisieren. Wenn Sie z.B. keine Informationen von anderen SKUs für Ihre Aktionsmerkmale benötigen, können Sie Ihr data nach der sku-Spalte partitionieren und verteiltes Rechnen verwenden. Wir fanden es nützlich, Dask für diese Aufgabe zu verwenden:
from dask import verzögert, berechnen
def compute_rolling_mean(df):
...
return df
skus_list = set(df[‘sku’])
dfs_with_promo = [
delayed(compute_rolling_mean)(df.loc[df.sku == sku]) for sku in skus_list
]
df_final = pd.concat(compute(*dfs_with_promo), axis=0, ignore_index=True)
Tipps 5: Berücksichtigung von Nachfrageübertragungen zwischen Produkten
Vergessen Sie nicht, dass die Verkäufe der einzelnen SKUs nicht nur von den eigenen Aktionen beeinflusst werden, sondern auch von den Aktionen substituierbarer Produkte, ein Phänomen, das als Kannibalisierung bekannt ist. Um ein leistungsfähiges Modell zu haben, müssen Sie den potenziellen Umsatzrückgang bei einigen Produkten aufgrund von Kannibalisierung vorhersehen.
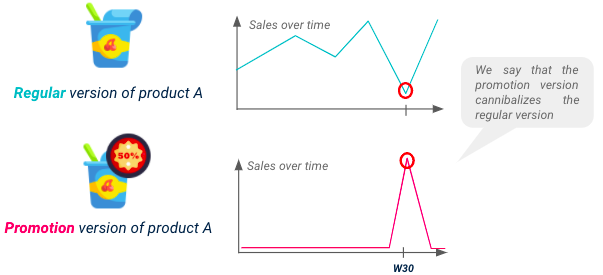
Illustration der Kannibalisierung
Um das Phänomen modellieren zu können, müssen wir zunächst die Kannibalisierungsbeziehungen zwischen Produkten ermitteln. Dabei lassen sich zwei Hauptansätze unterscheiden:
Automatische Erkennung Deep Dive
Eine Möglichkeit, Kannibalisierungsbeziehungen automatisch zu erkennen, ist die Verwendung von Korrelationswerten. Die Idee besteht darin, Produkte zusammenzubringen, bei denen die Wahrscheinlichkeit besteht, dass sie sich gegenseitig kannibalisieren, und zwar nicht auf der Grundlage ihrer Kategorie, sondern auf der Grundlage von Korrelationen zwischen der Entwicklung ihrer historischen Umsätze. Die Korrelationswerte werden für jedes Produktpaar berechnet. Wenn sie stark negativ sind, können wir davon ausgehen, dass sich diese Produkte gegenseitig kannibalisieren.
Kannibalisierungsfunktionen im Detail
Aus diesen Kannibalisierungsbeziehungen können wir nach dem gleichen Ansatz wie bei den direkten Werbemaßnahmen Merkmale erstellen. Zum Beispiel:
Ergebnisse und Schlussfolgerungen
Bei unseren Projekten haben wir festgestellt, dass rollierende Mittelwertmerkmale in den meisten Fällen besser für das Modell funktionieren als Uplift-/Downlift-Merkmale. Für ein bestimmtes Land beispielsweise führten die rollenden Mittelwertmerkmale zu einer Erhöhung der Vorhersagegenauigkeit um 2,8%, während die Uplift-Merkmale zu einer Erhöhung um 2% führten.
Jedes Projekt ist jedoch anders und unsere wichtigste Erkenntnis ist, dass die Erkundungsphase wesentlich ist und als Grundlage für die spätere Erstellung von Funktionen dient. Man muss wirklich verstehen, wie Promotionen funktionieren und welche Auswirkungen sie haben, um sie richtig zu modellieren. Dazu gehören Gespräche mit den Geschäftsinhabern sowie eine explorative Data-Analyse.
