

Autor


Até agora, falamos principalmente sobre a previsão de produtos regulares que já estão nas prateleiras há algum tempo. Mas e quanto aos produtos que foram lançados muito recentemente?
Neste artigo, mostraremos aos senhores como resolvemos esse problema, propondo uma solução alternativa para o nosso modelo de impulsionamento baseado em produtos semelhantes.
Ele consiste em treinar um modelo de agrupamento em inovações antigas para detectar semelhanças no padrão de vendas, mapear isso para as características do produto com um modelo de classificação e, em seguida, inferir as vendas da nova inovação com métodos estatísticos simples baseados nos resultados dos modelos 1 e 2.
Por que a previsão de produtos lançados é tão difícil?
Um pouco de contexto
O lançamento de produtos é muito comum no varejo. É da natureza das empresas de CPG diversificar seus produtos. Elas querem atrair seus clientes e adaptar seus produtos às mudanças de comportamento. E a empresa para a qual realizamos o projeto não foi exceção: eles lançam cerca de 50 a 60 inovações (novos produtos) todos os anos.
Definimos uma inovação como sendo uma nova marca de produto que está sendo lançada ou um novo produto com um novo sabor que está sendo introduzido em uma marca já existente. Depois de um certo tempo (por exemplo, em nosso caso, 2 meses), uma inovação se torna um produto regular.
Há outros casos em que um novo código de produto pode ser gerado, como
Não consideramos esses casos como inovações, mas como renovações e, portanto, estão fora de nosso escopo. Tivemos acesso a lançamentos de produtos com vendas de data de 2017 a 2019, ou seja, aproximadamente 150 produtos inovadores.
O principal desafio
Nosso trabalho era fazer previsões semanais para as 14 semanas seguintes no warehouse/daily/product nível.
A primeira vez que o modelo teve de ser aplicado foi 7 dias após seu lançamento, O senhor não tinha um modelo de vendas para o data, o que significa que ele teria apenas 7 dias de histórico do data e teria de prever as vendas para os próximos 14 x 7 = 98 dias! A última vez que tivemos que aplicar o modelo foi 60 dias após o lançamento. Isso significa que um produto lançado seria considerado um “produto regular” após dois meses, uma vez que teria alcançado certa “estabilidade” em seus ciclos de vendas, mas é claro que isso dependerá da atividade de sua empresa e da natureza do produto. Após essa fase de 2 meses, o modelo principal (modelo desenvolvido para produtos regulares) assumiria o modelo de inovação e faria previsões para o lançamento em questão. Essa decisão foi validada pelas equipes de negócios que tinham algum conhecimento sobre os ciclos de vendas de inovações.
Histórico muito limitado data
A quantidade de data histórico à nossa disposição é extremamente baixa para fazer previsões precisas. Temos um conjunto de data de treinamento que é muito menor do que o nosso conjunto de data de previsão/teste, o que geralmente resulta em uma precisão de previsão muito baixa. Estamos falando de ter algumas semanas no data de treinamento e ter de fazer previsões para 98 dias.
Os produtos lançados têm vendas muito instáveis no início
Além disso, As vendas data costumam ser muito confusas durante as primeiras semanas de lançamento, pois as tendências podem mudar drasticamente. Na verdade, os varejistas encomendam grandes quantidades da inovação nas primeiras duas semanas para encher suas prateleiras, o que eles chamam de fase de realização. Depois disso, os pedidos caem geralmente em W3 e W4 e depois aumentam um pouco.
Novamente, aqui muita coisa pode acontecer: alguns varejistas podem perceber que o novo produto não está vendendo muito bem durante as primeiras semanas em suas lojas e, portanto, reduzir drasticamente seus pedidos como uma reação rápida. Ou um produto pode ter grandes volumes de pedidos de alguns varejistas que o fabricante pode não conseguir atender totalmente porque não previu esse nível de demanda. Os varejistas continuarão fazendo pedidos de grandes volumes nas semanas seguintes para compensar os volumes que não foram totalmente atendidos.
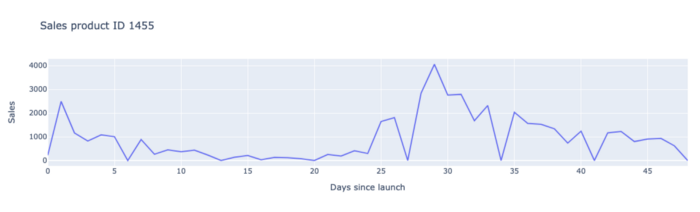
Todos os elementos listados acima são uma explicação clara de por que é difícil prever as vendas de inovações e, portanto, por que tivemos de desenvolver um modelo específico para esses produtos.
Critérios de avaliação
Tivemos as mesmas métricas de avaliação dos produtos regulares (W+1 e W+2 Forecast Accuracies em nível nacional/semanal). Como lembrete, aqui está a fórmula de uma precisão de previsão:
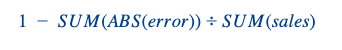
Adicionamos outra dimensão a esse problema. Calculamos essas métricas para cada data da previsão (a data em que fazemos nossa previsão) com relação à data de lançamento.
Monitoramos as precisões de previsão de W+1 e W+2 para datas de previsão que vão de D+7 até D+49, o que significa que nosso scorecard ficaria assim:
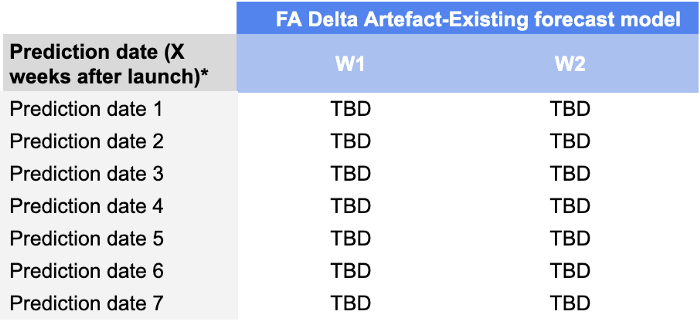
O motivo pelo qual acrescentamos essa dimensão é que é realmente importante para os planejadores de demanda monitorar o desempenho de suas previsões durante as primeiras semanas de lançamento. Um modelo que forneça previsões de boa qualidade durante as primeiras semanas permite que eles evitem grandes problemas de reabastecimento (que são comuns após o lançamento devido à incerteza) e, por fim, tenham sucesso em seu lançamento.
Abordagem proposta
Por que o ML clássico apresentou resultados ruins?
Como dito anteriormente, temos um problema de “data pequeno”. O tamanho pequeno do nosso data de treinamento e sua natureza muito errática o tornam inadequado para um modelo de aprendizado de máquina.
Na maioria das vezes, os modelos de boosting exigem de 2 a 3 anos de histórico de vendas data para detectar tendências gerais/efeitos de sazonalidade e pelo menos 2 a 3 meses de séries temporais data de um produto para fazer “previsões precisas”. Esse não era o nosso caso; nosso modelo XGBoost via apenas algumas semanas de histórico de vendas para cada produto.
Treinamos um modelo XGBoost em produtos de inovação com a seguinte lógica
E os resultados não foram nada bons! Por isso, decidimos mudar completamente nossa abordagem para esses produtos.

Os modelos clássicos de séries temporais também não salvaram o dia
Como nossa primeira iteração com o XGBoost foi um fracasso total, decidimos tentar a sorte com alguns bons e velhos modelos de séries temporais (VARMA, SARIMAX, Prophet etc.). Os modelos de séries temporais têm a virtude de serem mais simples e fáceis de interpretar do que os modelos de reforço. Além disso, como são treinados em um produto, podem se adaptar mais facilmente a mudanças abruptas de tendência.
A ideia era treinar um modelo (um modelo Prophet, por exemplo) por produto que faria previsões em nível nacional/diário. Como acima, o modelo também seria treinado várias vezes, cada vez até o dia anterior à data de previsão (D+7, D+14, etc.) e faria previsões para o horizonte de 14 semanas.
Mas aqui, como acima, os resultados ainda não eram satisfatórios e o motivo era praticamente o mesmo: não havia histórico suficiente de data! O histórico era muito superficial e o data era muito confuso para que o modelo pudesse entender um padrão claro e fazer previsões precisas.
Agrupamento de produtos com base em sósias: o Messias
Como nossas duas primeiras tentativas de fazer previsões foram inconclusivas, decidimos seguir uma direção completamente diferente.
Analisamos as vendas de todas as inovações de 2017 a 2019 e percebemos que muitas tinham curvas de vendas semelhantes durante os primeiros meses de seus respectivos lançamentos, o que nos deu a ideia de fazer previsões com base em semelhanças de produtos com inovações antigas. Nossa intuição foi reforçada porque encontramos alguns trabalhos de pesquisa de outros colegas cientistas do data que sugeriam uma abordagem semelhante (1).
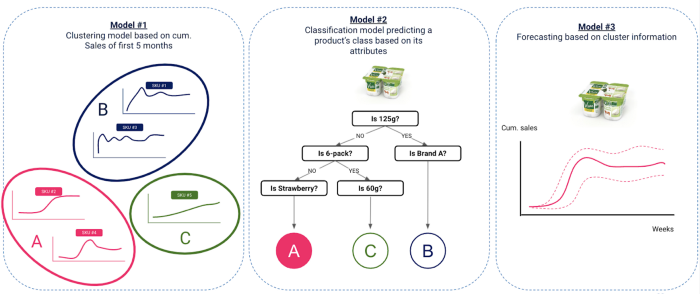
Nossa abordagem consistiu em três etapas fundamentais
Agrupamento de inovações antigas com base nas vendas - escopo Data: as inovações lançadas de 2017 a 2018 incluíam
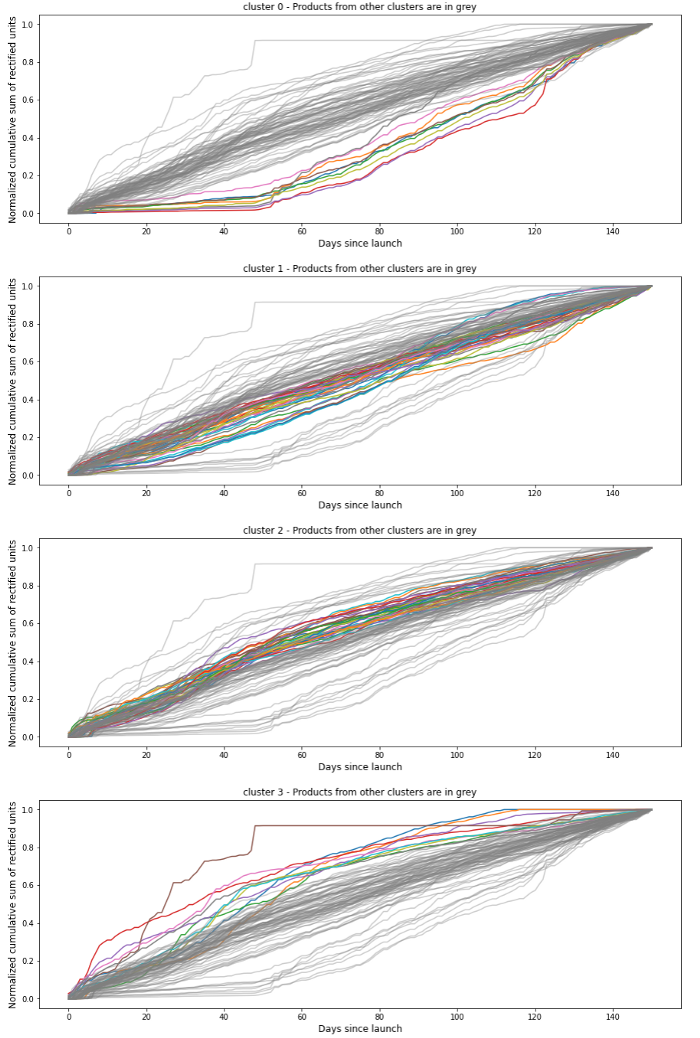
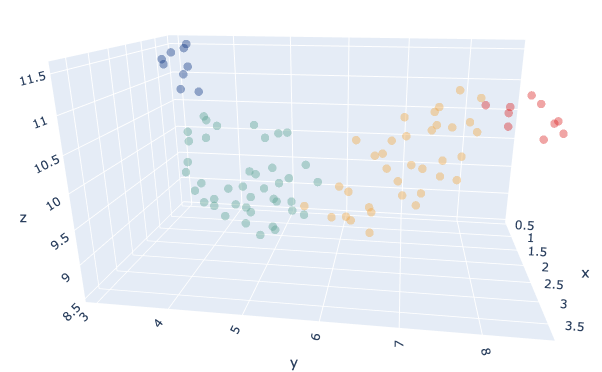
A ideia é agrupar inovações antigas com base em sua curva de série temporal em grupos de produtos semelhantes. Os produtos que estão no mesmo cluster têm padrões de vendas semelhantes e, portanto, as vendas de uma única inovação podem ser deduzidas a partir do conhecimento das vendas de inovações mais antigas.
Nosso data de entrada foi o Vendas cumulativas normalizadas MinMax de inovações antigas durante seus 5 primeiros meses. Analisamos as vendas cumulativas porque queríamos que nosso modelo de agrupamento tivesse uma noção de quando cada produto atingiria seu ritmo regular de vendas. Normalizamos as vendas cumulativas porque alguns produtos tinham a mesma forma de curva, mas um volume de vendas diferente, e queríamos colocá-los no mesmo cluster, já que nosso foco aqui é a similaridade.
Agrupamos nossos produtos com um Modelo K-Means com o parâmetro K sendo escolhido automaticamente por meio de um benchmark usando o Índice de silhuetas.O número ideal foi K=4.Também tentamos diferentes métricas de distância entre os euclidiano e DTW, com o euclidean apresentando resultados mais satisfatórios durante nossos testes.
Modelo de classificação que prevê o cluster de um produto com base em seus atributos - Escopo do Data: As inovações lançadas de 2017 a 2018 incluíram
A ideia aqui é encontrar um vínculo entre o cluster ao qual o produto pertence e seus atributos, como dimensão, marca, sabor, etc., bem como alguns data contextuais, como período de lançamento, campanhas de mídia, etc. Essa ligação seria encontrada com a ajuda de um modelo de classificação.
O modelo seria alimentado com atributos do produto juntamente com o contexto data e tentaria prever o cluster de uma inovação com base nisso. A intuição por trás dessa abordagem é ver se podemos responder à seguinte pergunta:
Se conhecermos antecipadamente os atributos de uma inovação + data contextual, podemos prever o tipo de comportamento de vendas que esse produto terá após seu lançamento?
Como tínhamos um data muito limitado (cerca de 100 produtos), treinamos um BaggingClassifier simples em nossos produtos com uma divisão de treinamento/teste de 75%-25%. Acabamos com um Pontuação F1 do 84% no conjunto de teste.
Realizamos algumas análises sobre os atributos do produto para ver se conseguimos encontrar alguma explicação comercial para cada cluster e aqui estão nossas descobertas:
Previsão de vendas de inovações com base em clusters previstos - escopo Data: inovações lançadas após 2019
Agora que conseguimos vincular as vendas de uma inovação a seus atributos, podemos aplicar nosso modelo a novas inovações para determinar seu cluster e, portanto, prever suas vendas.
Começamos de forma muito simples. Para cada nova inovação (lançada após 2019), calculamos a média de vendas das inovações antigas (lançadas antes de 2019) que estavam no mesmo cluster que a nova, durante suas primeiras semanas de lançamento e consideramos isso como nossa previsão para a nova inovação.
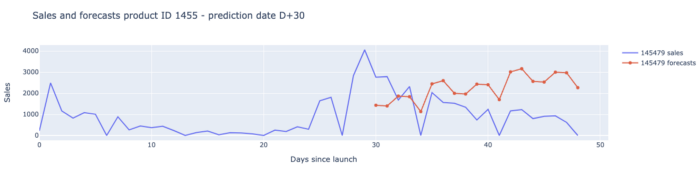
Essa abordagem simplista foi, na verdade, um bom começo, mas teve uma falha importante: conseguimos prever com precisão a forma da nova inovação, mas a escala de nossa previsão não foi boa.
Decidimos dimensionar nossas previsões comparando as vendas da nova inovação e das antigas similares de D+0 até a data da previsão (data da previsão). Como o sell-out data foi tão perspicaz quanto o sell-in data na previsão de sell-in futuro em nosso caso, calculamos dois coeficientes de escala, um com sell-in e outro com sell-out.
Coeficiente de venda = venda média de inovações similares antigas até a data da previsão / venda média da nova inovação até a data da previsão
Coeficiente de sell-out = sell-out médio de inovações similares antigas até a data da previsão / sell-out médio da nova inovação até a data da previsão
Por fim, aumentamos/diminuímos a escala de nossas previsões com a média desses dois coeficientes.
Resultados e conclusões
Aqui estão nossos resultados em cada data de previsão e horizonte de previsão:
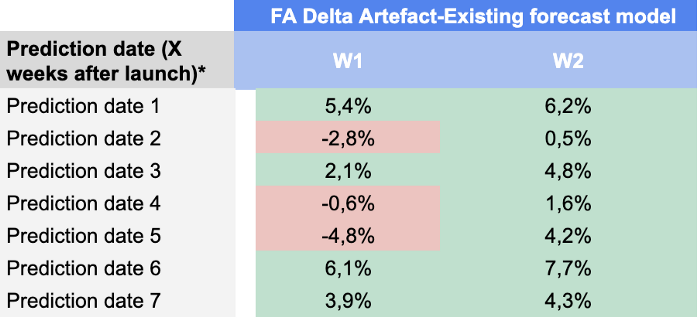
Ficamos bastante satisfeitos com esses resultados, pois nosso modelo foi capaz de superar a previsão dos planejadores de demanda em quase todos os KPIs até a data de previsão 49.
Referências
1. Previsão de novos produtos com produtos análogos<
Gostaria de agradecer a todos que trabalharam neste projeto, especialmente a Sylvain Combettes, sem o qual este artigo nunca teria sido escrito.
E obrigado pelo senhor ter lido até aqui! Ficarei feliz em ouvir seus comentários. Se o senhor gostou da leitura, fique à vontade para conferir nosso posições em aberto em Artefact 🙂
