

Auteur


Tot nu toe hebben we het voornamelijk gehad over het voorspellen van reguliere producten die al een tijdje in de schappen liggen. Maar hoe zit het met producten die zeer recent gelanceerd zijn?
In dit artikel laten we u zien hoe we dit probleem hebben aangepakt door een alternatieve oplossing voor te stellen voor ons boostingmodel op basis van product look-alikes.
Het bestaat uit het trainen van een clustermodel op oude innovaties om overeenkomsten in verkooppatronen op te sporen, dat vervolgens met een classificatiemodel in kaart te brengen voor productkenmerken en vervolgens de verkoop van nieuwe innovaties af te leiden met eenvoudige statistische methoden op basis van de resultaten van model 1 en 2.
Waarom is het voorspellen van gelanceerde producten zo moeilijk?
Een beetje context
Productlanceringen zijn heel gewoon in de detailhandel. Het ligt in de aard van CPG-bedrijven om hun producten te diversifiëren. Ze willen hun klanten aanspreken en hun producten aanpassen aan gedragsveranderingen. En het bedrijf waarvoor wij het project deden, was geen uitzondering: zij brengen elk jaar bijna 50-60 innovaties (nieuwe producten) uit.
Wij definiëren een innovatie eerder als een nieuw productmerk dat wordt gelanceerd of een nieuw product met een nieuwe smaak dat wordt toegevoegd aan een al bestaand merk. Na een bepaalde tijd (in ons geval bijvoorbeeld 2 maanden) wordt een innovatie een gewoon product.
Er zijn andere gevallen waarin een nieuwe productcode kan worden gegenereerd, zoals
Wij beschouwen deze gevallen niet als innovaties maar als renovaties en daarom vallen ze buiten ons bereik.Wij hadden toegang tot productlanceringen met een omzet van data van 2017 tot 2019, dus ruwweg 150 innovatieproducten.
De grootste uitdaging
Het was onze taak om wekelijkse voorspellingen te doen voor de komende 14 weken op magazijn/dagelijks/product niveau.
De eerste keer dat het model moest worden toegepast was 7 dagen na de lancering, wat betekent dat het slechts 7 dagen historische data zou hebben en de verkoop voor de komende 14 x 7 = 98 dagen moest voorspellen! De laatste keer dat we het model moesten toepassen was 60 dagen na de lancering. Dit betekent dat een gelanceerd product na 2 maanden als een “normaal product” zou worden beschouwd, omdat het enige “stabiliteit” in de verkoopcycli zou hebben bereikt, maar dit hangt natuurlijk af van de activiteit van uw bedrijf en de aard van het product. Na deze fase van 2 maanden zou het kernmodel (het model dat ontwikkeld is voor reguliere producten) het innovatiemodel overnemen en voorspellingen doen voor de betreffende lancering, deze beslissing werd gevalideerd door de bedrijfsteams die enige kennis hadden van de verkoopcycli van innovaties.
Zeer beperkt historisch data
De hoeveelheid historische data waarover we beschikken is kritisch laag voor het maken van nauwkeurige voorspellingen. We hebben een training dataset die veel kleiner is dan onze voorspelling/test dataset en dat zorgt vaak voor een zeer slechte voorspellingsnauwkeurigheid. We hebben het over een paar weken in training data en we moeten voorspellingen doen voor 98 dagen.
Gelanceerde producten hebben in het begin een zeer onstabiele verkoop
Bovendien, De verkoop data is vaak erg rommelig tijdens de eerste weken van de lancering, omdat trends drastisch kunnen veranderen.. Het is zelfs zo dat detailhandelaren in de eerste 2 weken enorme hoeveelheden van de innovatie bestellen om hun schappen te vullen, ze noemen dit de uitvoeringsfase. Daarna dalen de bestellingen over het algemeen op W3 en W4 en daarna stijgen ze weer een beetje.
Ook hier kan er veel gebeuren: sommige detailhandelaren kunnen zich realiseren dat het nieuwe product niet erg goed verkoopt tijdens de eerste weken in hun winkels en daarom als snelle reactie hun bestellingen drastisch verlagen. Of een product kan enorme bestelvolumes hebben van sommige detailhandelaren, waaraan de fabrikant niet volledig kan voldoen omdat hij dit vraagniveau niet had voorzien. De detailhandelaren zullen in de weken daarna grote volumes blijven bestellen om de volumes te compenseren die niet volledig geleverd werden.
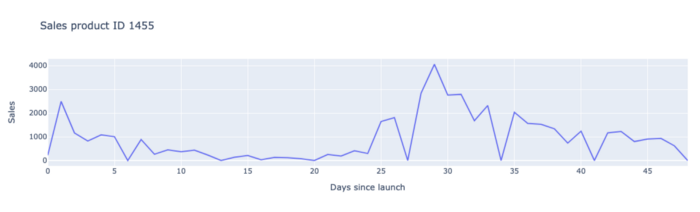
Alle bovenstaande elementen zijn een duidelijke verklaring waarom het voorspellen van de verkoop van innovaties moeilijk is en waarom we daarom een specifiek model voor deze producten moesten ontwikkelen.
Evaluatiecriteria
We hadden dezelfde evaluatiecijfers als voor gewone producten (W+1 en W+2 prognosenauwkeurigheden op nationaal/wekelijks niveau). Ter herinnering volgt hier de formule van een prognosenauwkeurigheid:
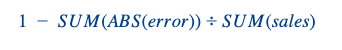
Wij hebben nog een dimensie aan dit probleem toegevoegd. We berekenden deze metriek voor elke voorspellingsdatum (de datum waarop we onze voorspelling doen) met betrekking tot de lanceerdatum.
We controleerden de W+1 en W+2 voorspellingsnauwkeurigheden voor voorspellingsdata van D+7 tot D+49, wat betekent dat onze scorekaart er als volgt uit zou zien:
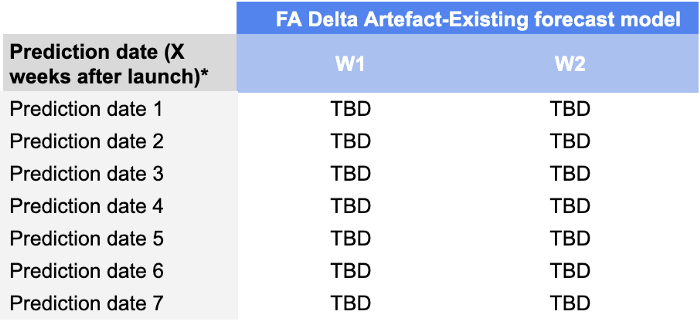
De reden dat we deze dimensie hebben toegevoegd, is dat het voor vraagplanners heel belangrijk is om de prestaties van hun voorspellingen tijdens de eerste weken van de lancering te controleren. Een model dat prognoses van goede kwaliteit levert tijdens de eerste weken, stelt hen in staat om grote aanvulproblemen (die vaak voorkomen na de lancering als gevolg van onzekerheid) te voorkomen en uiteindelijk te slagen in hun lancering.
Voorgestelde benadering
Waarom leverde klassieke ML slechte resultaten op?
Zoals eerder gezegd hebben we een “klein data” probleem. De kleine omvang van onze trainings data en de zeer grillige aard ervan maakt het ongeschikt voor een machine-learningmodel.
Meestal hebben boostingmodellen 2-3 jaar historische verkoop data nodig om algemene trends/seizoensinvloeden te detecteren en minstens 2-3 maanden tijdreeksen data voor één product om “accurate voorspellingen” te doen. Dit was voor ons niet het geval; ons XGBoost-model zag slechts een paar weken historische verkoop voor elk product.
We trainden een XGBoost-model op innovatieproducten met de volgende logica
En de resultaten waren helemaal niet goed! Daarom besloten we onze aanpak voor deze producten volledig te veranderen.

Klassieke tijdreeksmodellen redden de dag ook niet
Aangezien onze eerste poging met XGBoost een totale mislukking was, besloten we ons geluk te beproeven met een paar ouderwetse tijdreeksmodellen (VARMA, SARIMAX, Prophet, enz.). Tijdreeksmodellen hebben het voordeel dat ze eenvoudiger en gemakkelijker te interpreteren zijn dan boostingmodellen. Omdat ze getraind worden op één product, kunnen ze zich ook gemakkelijker aanpassen aan abrupte trendveranderingen.
Het idee was om per product een model te trainen (bijvoorbeeld een Prophet-model) dat voorspellingen zou doen op nationaal/dagelijks niveau. Net als hierboven zou het model ook meerdere keren worden getraind, telkens tot de dag voor de voorspellingsdatum (D+7, D+14, enz.) en voorspellingen doen voor de horizon van 14 weken.
Maar hier waren de resultaten, net als hierboven, nog steeds niet bevredigend en de reden was vrijwel hetzelfde: niet genoeg historische data! De geschiedenis was te ondiep en de data was te rommelig voor het model om een duidelijk patroon te begrijpen en nauwkeurige voorspellingen te doen.
Productclustering op basis van look-alikes: de Messias
Omdat onze twee eerste pogingen om voorspellingen te doen geen uitsluitsel gaven, besloten we om het helemaal over een andere boeg te gooien.
We analyseerden de verkoopcijfers van alle innovaties van 2017 tot 2019 en realiseerden ons dat veel innovaties een vergelijkbare verkoopcurve hadden tijdens de eerste maanden van hun respectievelijke lanceringen, wat ons op het idee bracht om voorspellingen te doen op basis van productovereenkomsten met oude innovaties. Onze intuïtie werd versterkt doordat we enkele onderzoekspapers van andere collega data-wetenschappers vonden die een soortgelijke aanpak voorstelden (1).
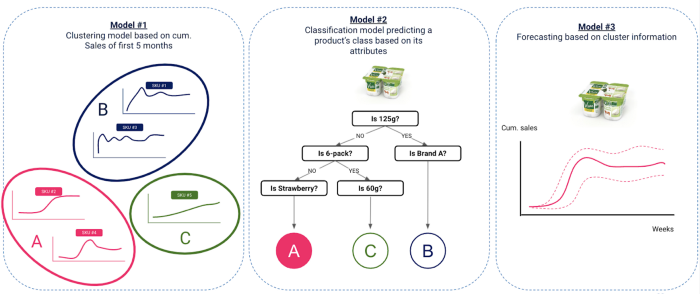
Onze aanpak bestond uit 3 fundamentele stappen
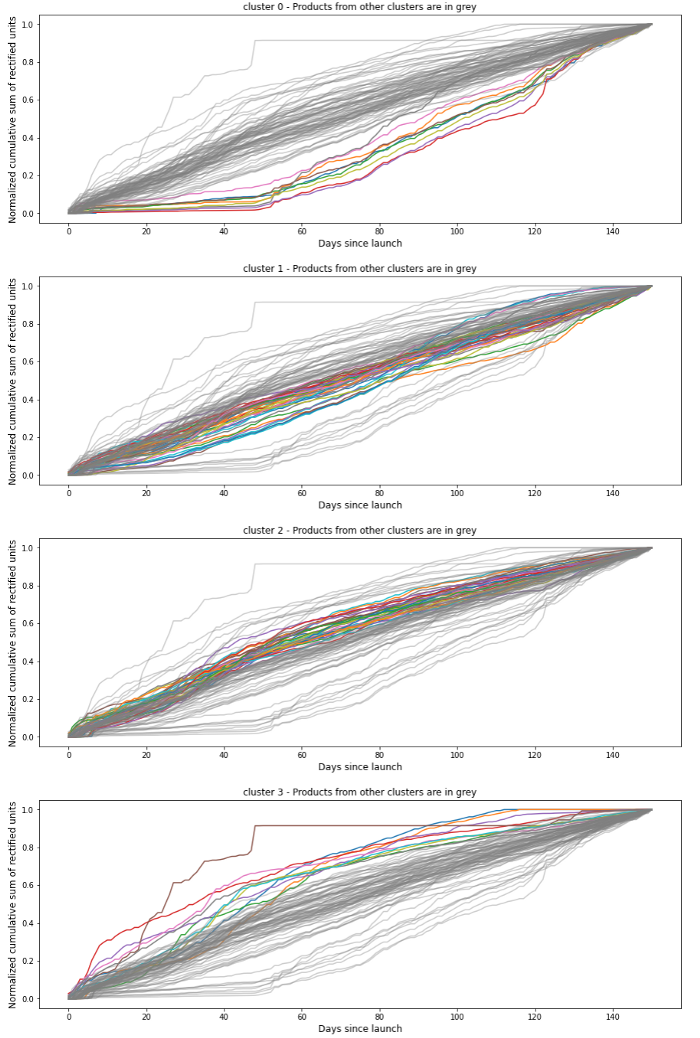
Clustering van oude innovaties op basis van verkoop - Data bereik : Innovaties gelanceerd van 2017 tot 2018 inbegrepen
Het idee is om oude innovaties op basis van hun tijdreekscurve te clusteren in groepen van vergelijkbare producten. Producten in dezelfde cluster hebben vergelijkbare verkooppatronen en daarom kan de verkoop van een enkele innovatie worden afgeleid uit de verkoopcijfers van oudere innovaties.
Onze ingang data was de MinMax genormaliseerde cumulatieve verkoop van oude innovaties tijdens hun eerste 5 maanden. We keken naar de cumulatieve verkoop omdat we ons clustermodel een idee wilden geven van wanneer elk product zijn normale verkooptempo zou bereiken. We hebben de cumulatieve verkoop genormaliseerd omdat sommige producten dezelfde curvevorm hadden maar verschillende verkoopvolumes en we wilden ze in hetzelfde cluster plaatsen omdat we ons hier richten op gelijkenis.
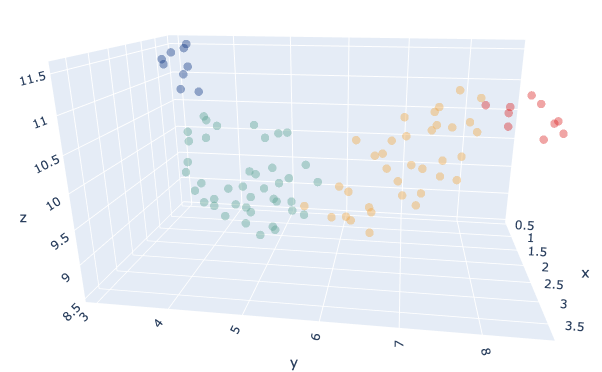
We hebben onze producten geclusterd met een K-Means model waarbij de K-parameter automatisch wordt gekozen via een benchmark met de Silhouet index.Het optimale aantal was K=4.We hebben ook verschillende afstandsmetingen tussen euclidisch en DTW, waarbij euclidean meer bevredigende resultaten gaf tijdens onze tests.
Classificatiemodel dat de productcluster voorspelt op basis van zijn attributen - Data bereik : Innovaties gelanceerd van 2017 tot 2018 inbegrepen
Het idee hier is om een verband te vinden tussen de cluster waartoe het product behoort en de attributen ervan, zoals dimensie, merk, smaak, enzovoort, evenals enkele contextuele data zoals de introductieperiode, mediacampagnes, enzovoort. Dat verband wordt gevonden met behulp van een classificatiemodel.
Het model wordt gevoed met productkenmerken en contextuele data en probeert op basis daarvan het innovatiecluster te voorspellen. De intuïtie achter deze aanpak is om te kijken of we de volgende vraag kunnen beantwoorden:
Als we de kenmerken + contextuele data van een innovatie van tevoren kennen, kunnen we dan voorspellen welk verkoopgedrag dit product zal vertonen na de lancering?
Aangezien we zeer beperkte data hadden (ruwweg 100 producten), trainden we een eenvoudige BaggingClassifier op onze producten met een 75%-25% train/test opsplitsing. We eindigden met een F1 score van 84% op de testset.
We hebben wat analyses uitgevoerd op productkenmerken om te zien of we een zakelijke verklaring voor elk cluster kunnen vinden en dit zijn onze bevindingen:
Prognose van de verkoop van nieuwe innovaties op basis van voorspelde clusters - Data bereik : Innovaties gelanceerd na 2019
Nu we de verkoop van een innovatie kunnen koppelen aan haar kenmerken, kunnen we ons model toepassen op nieuwe innovaties om hun cluster te bepalen en zo hun verkoop te voorspellen.
We zijn heel eenvoudig begonnen. Voor voor elke nieuwe innovatie (gelanceerd na 2019) berekenden we de gemiddelde verkoop van oude innovaties (gelanceerd voor 2019) die in dezelfde cluster zaten als de nieuwe innovatie, tijdens hun eerste weken van lancering en beschouwden dat als onze voorspelling voor de nieuwe innovatie.
Deze simplistische benadering was eigenlijk een goed begin, maar had één grote tekortkoming: we konden de vorm van de nieuwe innovatie nauwkeurig voorspellen, maar de schaal van onze voorspelling was niet goed.
We besloten om onze voorspellingen te schalen door de verkopen van de nieuwe innovatie en de oude vergelijkbare innovaties vanaf D+0 tot de voorspellingsdatum (predictiedatum) met elkaar te vergelijken. Aangezien sell-out data even inzichtelijk was als sell-in data in het voorspellen van toekomstige sell-in in ons geval, berekenden we 2 schaalcoëfficiënten, één met sell-in en één met sell-out.
Verkoopcoëfficiënt = gemiddelde verkoop van oude vergelijkbare innovaties tot voorspellingsdatum / gemiddelde verkoop van nieuwe innovatie tot voorspellingsdatum
Verkoopcoëfficiënt = gemiddelde verkoop van oude vergelijkbare innovaties tot de voorspellingsdatum / gemiddelde verkoop van nieuwe innovatie tot de voorspellingsdatum
Uiteindelijk hebben we onze voorspellingen opgeschaald/afgeschaald met het gemiddelde van deze 2 coëfficiënten.
Resultaten & conclusies
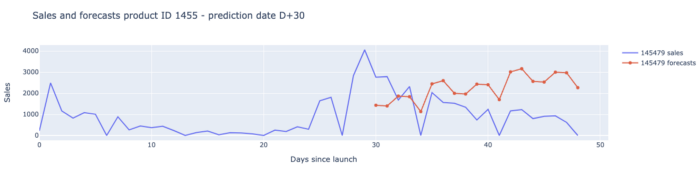
Hier zijn onze resultaten voor elke voorspellingsdatum en voorspellingshorizon:
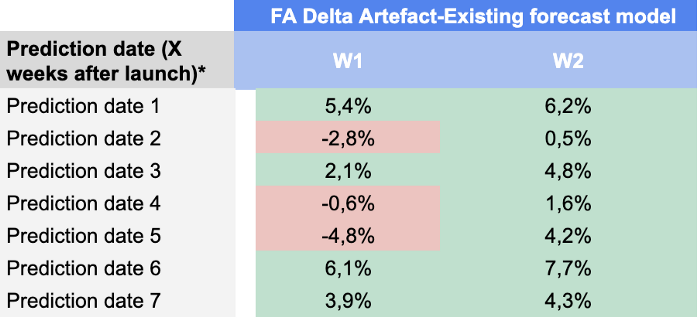
We waren erg tevreden met deze resultaten, aangezien ons model in staat was om de voorspelling van de planners voor bijna elke KPI tot voorspellingsdatum 49 te overtreffen.
Referenties
1. Voorspelling van nieuwe producten met analoge producten<
Ik wil iedereen bedanken die aan dit project heeft meegewerkt, in het bijzonder Sylvain Combettes, zonder wie dit artikel nooit zou zijn geschreven>.
En bedankt voor het lezen! Ik hoor graag uw feedback. Als u het leuk vond om te lezen, kijk dan gerust eens naar onze openstaande posities bij Artefact 🙂
