

Autor


Hasta ahora hemos hablado principalmente de la previsión de productos habituales que llevan bastante tiempo en el lineal. Pero, ¿qué ocurre con los productos que se han lanzado muy recientemente?
En este artículo le mostraremos cómo abordamos esta cuestión proponiendo una solución alternativa a nuestro modelo de refuerzo basado en productos parecidos.
Consiste en entrenar un modelo de agrupación en innovaciones antiguas para detectar similitudes en los patrones de ventas, luego asignar eso a las características del producto con un modelo de clasificación y después inferir las ventas de la nueva innovación con métodos estadísticos simples basados en los resultados de los modelos 1 y 2.
¿Por qué es tan difícil prever los productos lanzados?
Un poco de contexto
Los lanzamientos de productos son muy habituales en el comercio minorista. Está en la naturaleza de las empresas de bienes de consumo diversificar sus productos. Quieren atraer a sus clientes y adaptar sus productos a los cambios de comportamiento. Y la empresa para la que hicimos el proyecto no era una excepción, casi lanzan entre 50 y 60 innovaciones (nuevos productos) cada año.
Definimos una innovación más bien como el lanzamiento de una nueva marca de producto o la introducción de un nuevo producto con un nuevo sabor en una marca ya existente. Al cabo de cierto tiempo (por ejemplo, en nuestro caso, 2 meses) una innovación se convierte en un producto habitual.
Hay otros casos en los que se puede generar un nuevo código de producto como
No consideramos estos casos como innovaciones sino como renovaciones y por lo tanto están fuera de nuestro alcance.Tuvimos acceso a lanzamientos de productos con ventas data de 2017 a 2019, por lo que aproximadamente 150 productos de innovación.
El principal reto
Nuestro trabajo consistía en hacer previsiones semanales para las 14 semanas siguientes en almacén/diario/producto nivel.
La primera vez que hubo que aplicar el modelo fue 7 días después de su lanzamiento, lo que significa que sólo dispondría de 7 días de data histórico y ¡tenía que predecir las ventas de los próximos 14 x 7 = 98 días! La última vez que tuvimos que aplicar el modelo fue 60 días después del lanzamiento. Esto significa que un producto lanzado se consideraría un “producto regular” al cabo de 2 meses, ya que habría alcanzado cierta “estabilidad” en sus ciclos de venta, pero por supuesto, esto dependerá de la actividad de su empresa y de la naturaleza del producto. Después de esta fase de 2 meses, el modelo central (modelo desarrollado para los productos regulares) tomaría el relevo del modelo de innovación y haría previsiones para el lanzamiento en cuestión, esta decisión fue validada por los equipos comerciales que tenían algunos conocimientos sobre los ciclos de venta de las innovaciones.
Histórico muy limitado data
La cantidad de data históricos de que disponemos es críticamente baja para hacer previsiones precisas. Disponemos de un conjunto de data de entrenamiento que es mucho menor que nuestro conjunto de data de predicción/prueba y eso a menudo conlleva una precisión de previsión muy pobre. Estamos hablando de disponer de unas pocas semanas en data de entrenamiento y tener que hacer previsiones para 98 días.
Los productos lanzados tienen ventas muy inestables al principio
Además, las ventas data suelen ser muy desordenadas durante las primeras semanas de lanzamiento, ya que las tendencias pueden cambiar drásticamente. De hecho los minoristas piden grandes cantidades de la innovación en las 2 primeras semanas para llenar sus estanterías, a esto lo llaman el fase de cumplimiento. Después de eso los pedidos caen generalmente en W3 y W4 y luego aumentan un poco.
De nuevo, aquí pueden ocurrir muchas cosas: algunos minoristas pueden darse cuenta de que el nuevo producto no se vende muy bien durante las primeras semanas en sus tiendas y, por tanto, reducir drásticamente sus pedidos como reacción rápida. O puede que un producto tenga grandes volúmenes de pedidos de algunos minoristas que el fabricante no pueda satisfacer totalmente porque no había previsto este nivel de demanda. Los minoristas seguirán haciendo pedidos de grandes volúmenes durante las semanas siguientes para compensar los volúmenes que no se les suministraron en su totalidad.
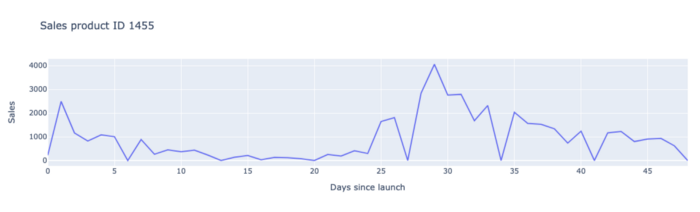
Todos los elementos enumerados anteriormente son una clara explicación de por qué es difícil predecir las ventas de innovación y, por tanto, de por qué hemos tenido que desarrollar un modelo específico para estos productos.
Criterios de evaluación
Tuvimos las mismas métricas de evaluación que para los productos normales (precisiones de previsión W+1 y W+2 a nivel nacional/semanal). A modo de recordatorio, he aquí la fórmula de una precisión de previsión:
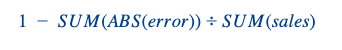
Añadimos otra dimensión a este problema. Calculamos estas métricas para cada fecha de predicción (fecha en la que hacemos nuestra predicción) con respecto a la fecha de lanzamiento.
Controlamos las precisiones de los pronósticos W+1 y W+2 para las fechas de predicción que van desde D+7 hasta D+49, lo que significa que nuestra tabla de puntuación tendría este aspecto:
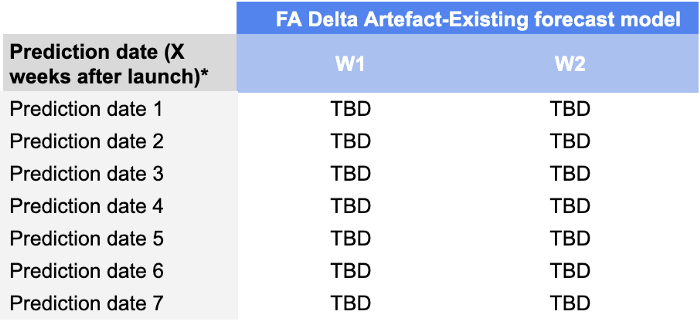
La razón por la que añadimos esta dimensión es que para los planificadores de la demanda es realmente importante controlar el rendimiento de sus previsiones durante las primeras semanas de lanzamiento. Un modelo que proporcione previsiones de buena calidad durante las primeras semanas les permite evitar grandes problemas de reabastecimiento (habituales tras el lanzamiento debido a la incertidumbre) y, en última instancia, tener éxito en su lanzamiento.
Enfoque propuesto
¿Por qué el ML clásico dio malos resultados?
Como ya hemos dicho, tenemos un problema de “data pequeño”. El pequeño tamaño de nuestro data de entrenamiento y su naturaleza muy errática lo hacen inadecuado para un modelo de aprendizaje automático.
La mayoría de las veces, los modelos de boosting requieren 2-3 años de ventas históricas data para detectar tendencias generales/efectos de estacionalidad y al menos 2-3 meses de series temporales data de un producto para hacer “predicciones precisas”. Este no era nuestro caso; nuestro modelo XGBoost sólo veía unas pocas semanas de ventas históricas para cada producto.
Entrenamos un modelo XGBoost sobre productos innovadores con la siguiente lógica
¡Y los resultados no fueron nada buenos! Por ello decidimos cambiar completamente nuestro enfoque para estos productos.

Los modelos clásicos de series temporales tampoco salvaron el día
Dado que nuestra primera iteración con XGBoost fue un fracaso total, decidimos probar suerte con algunos modelos de series temporales a la antigua usanza (VARMA, SARIMAX, Prophet, etc.). Los modelos de series temporales tienen la virtud de ser más sencillos y fáciles de interpretar que los modelos boosting. Además, como se entrenan con un solo producto, pueden adaptarse más fácilmente a los cambios bruscos de tendencia.
La idea era entrenar un modelo (un modelo Profeta, por ejemplo) por producto que hiciera previsiones a nivel nacional/diario. Como en el caso anterior, el modelo se entrenaría también varias veces, cada vez hasta el día anterior a la fecha de predicción (D+7, D+14, etc.) y haría previsiones para el horizonte de 14 semanas.
Pero aquí, como arriba, los resultados seguían sin ser satisfactorios y la razón era prácticamente la misma: ¡no había suficiente data histórico! La historia era demasiado superficial y el data demasiado desordenado para que el modelo pudiera entender un patrón claro y hacer predicciones precisas.
Agrupación de productos basada en productos similares : el Mesías
Como nuestros dos primeros intentos de hacer previsiones no fueron concluyentes, decidimos ir completamente en otra dirección.
Analizamos las ventas de todas las innovaciones de 2017 a 2019 y nos dimos cuenta de que muchas tenían curvas de ventas similares durante los primeros meses de sus respectivos lanzamientos, esto nos dio la idea de hacer previsiones basadas en las similitudes de los productos con innovaciones antiguas. Nuestra intuición se vio reforzada desde que encontramos algunos trabajos de investigación de otros compañeros de data que sugerían un enfoque similar (1).
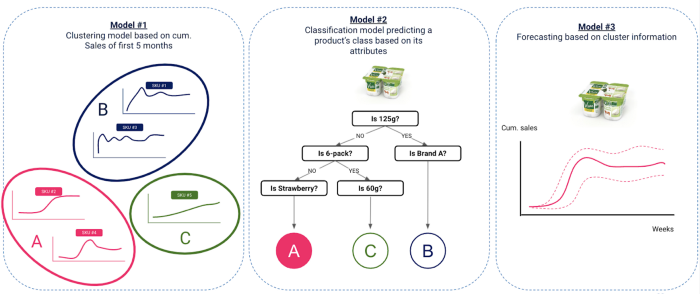
Nuestro enfoque consistió en 3 pasos fundamentales
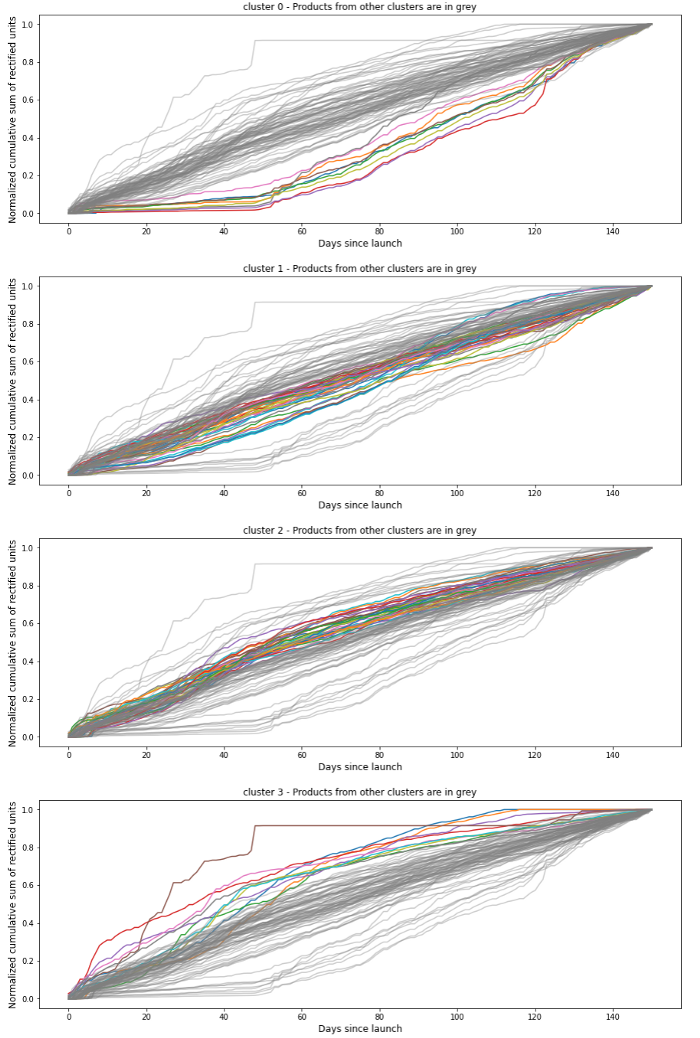
Agrupación de innovaciones antiguas en función de las ventas - Ámbito Data : Se incluyen las innovaciones lanzadas de 2017 a 2018
La idea es agrupar las innovaciones antiguas basándose en su curva de series temporales en grupos de productos similares. Los productos que se encuentran en el mismo grupo tienen patrones de ventas similares y, por tanto, las ventas de una única innovación pueden deducirse a partir del conocimiento de las ventas de las innovaciones más antiguas.
Nuestro data de entrada fue el Ventas acumuladas normalizadas MinMax de las innovaciones antiguas durante sus 5 primeros meses. Nos fijamos en las ventas acumulativas porque queríamos que nuestro modelo de agrupación tuviera una idea de cuándo alcanzaría cada producto su ritmo regular de ventas. Normalizamos las ventas acumuladas porque algunos productos tenían la misma forma de curva pero diferente volumen de ventas y queríamos ponerlos en el mismo cluster, ya que aquí nos centramos en la similitud.
Agrupamos nuestros productos con un Modelo K-Means eligiéndose automáticamente el parámetro K mediante una prueba comparativa utilizando el Índice de siluetas.El número óptimo fue K=4.También probamos diferentes métricas de distancia entre euclidiano y DTW, con el euclidiano dando resultados más satisfactorios durante nuestras pruebas.
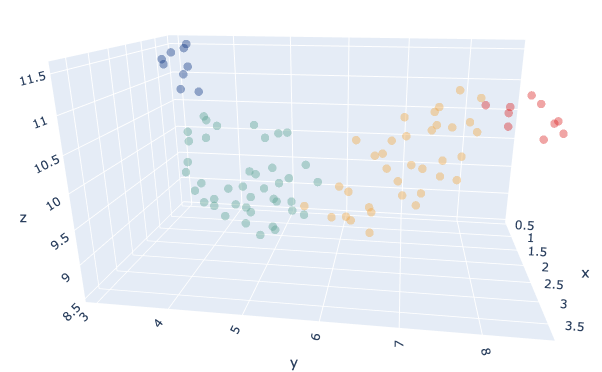
Modelo de clasificación que predice la agrupación de un producto en función de sus atributos - Ámbito Data : Las innovaciones lanzadas de 2017 a 2018 incluyen
La idea aquí es encontrar un vínculo entre el cluster al que pertenece el producto y sus atributos, como dimensión, marca, sabor, etc., así como algunos data contextuales como periodo de lanzamiento, campañas de medios, etc. Ese vínculo se encontraría con la ayuda de un modelo de clasificación.
El modelo se alimentaría con atributos del producto junto con data contextuales e intentaría predecir el cluster de una innovación basándose en ello. La intuición que subyace a este enfoque es ver si podemos responder a la siguiente pregunta :
Si conocemos de antemano los atributos de una innovación + data contextual, ¿podemos predecir el tipo de comportamiento de ventas que tendrá este producto tras su lanzamiento?
Dado que disponíamos de un data muy limitado (aproximadamente 100 productos), entrenamos un clasificador Bagging simple en nuestros productos con una división 75%-25% de entrenamiento/prueba. Terminamos con un Puntuación F1 de 84% en el conjunto de pruebas.
Hemos realizado algunos análisis sobre los atributos de los productos para ver si podemos encontrar alguna explicación empresarial para cada agrupación y aquí están nuestras conclusiones:
Previsión de las ventas de nuevas innovaciones en función de las agrupaciones previstas - Ámbito Data : Innovaciones lanzadas después de 2019
Ahora que somos capaces de vincular las ventas de una innovación a sus atributos, podemos aplicar nuestro modelo a las nuevas innovaciones para determinar su grupo y, por tanto, predecir sus ventas.
Empezamos de forma muy sencilla. Para cada nueva innovación (lanzada después de 2019), calculamos las ventas medias de las antiguas innovaciones (lanzadas antes de 2019) que se encontraban en el mismo clúster que la nueva, durante sus primeras semanas de lanzamiento y lo consideramos como nuestra previsión para la nueva innovación.
Este enfoque simplista fue en realidad un buen comienzo, pero tenía un fallo importante: fuimos capaces de predecir con exactitud la forma de la nueva innovación, sin embargo la escala de nuestra predicción no fue buena.
Decidimos escalar nuestras predicciones comparando las ventas de la nueva innovación y las antiguas similares desde D+0 hasta la fecha de predicción (fecha de predicción). Dado que en nuestro caso el sell-out data era tan perspicaz como el sell-in data para predecir las ventas futuras, calculamos 2 coeficientes de escala, uno con sell-in y otro con sell-out.
Coeficiente de venta = venta media de innovaciones similares antiguas hasta la fecha de predicción / venta media de la nueva innovación hasta la fecha de predicción
Coeficiente de venta = venta media de antiguas innovaciones similares hasta la fecha de predicción / venta media de la nueva innovación hasta la fecha de predicción
Finalmente, aumentamos/reducimos nuestras predicciones con la media de estos 2 coeficientes.
Resultados y conclusiones
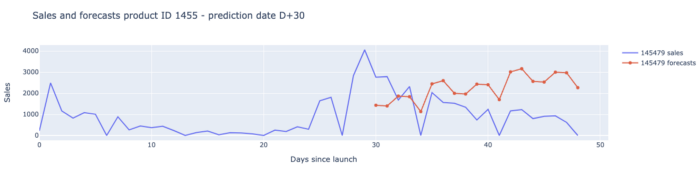
Estos son nuestros resultados para cada fecha y horizonte de predicción:
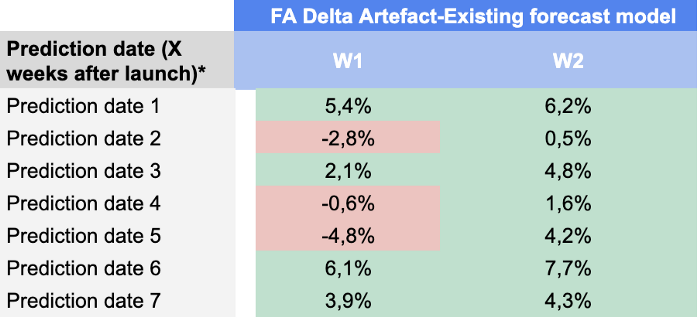
Quedamos bastante satisfechos con estos resultados, ya que nuestro modelo fue capaz de batir la previsión de los planificadores de la demanda en casi todos los KPI hasta la fecha de predicción 49.
Referencias
1. Previsión de nuevos productos con productos análogos<
Me gustaría dar las gracias a todos los que han trabajado en este proyecto, especialmente a Sylvain Combettes, sin el cual este artículo nunca se habría escrito>.
Y gracias por leer hasta aquí. Estaré encantada de escuchar sus comentarios. Si le ha gustado la lectura, no dude en consultar nuestro puestos vacantes en Artefact 🙂 .
