

Auteur


Jusqu'à présent, nous avons surtout parlé des prévisions concernant les produits courants qui sont sur les étagères depuis un certain temps. Mais qu'en est-il des produits qui ont été lancés très récemment ?
Dans cet article, nous allons vous montrer comment nous avons résolu ce problème en proposant une solution alternative à notre modèle de stimulation basé sur les produits similaires.
Il s'agit d'entraîner un modèle de regroupement sur les anciennes innovations afin de détecter les similitudes entre les modèles de vente, de les mettre en correspondance avec les caractéristiques du produit à l'aide d'un modèle de classification, puis de déduire les ventes de la nouvelle innovation à l'aide de méthodes statistiques simples basées sur les résultats des modèles 1 et 2.
Pourquoi est-il si difficile de prévoir les produits lancés sur le marché ?
Un peu de contexte
Les lancements de produits sont très courants dans le commerce de détail. Il est dans la nature des entreprises de produits de grande consommation de diversifier leurs produits. Elles veulent séduire leurs clients et adapter leurs produits aux changements de comportement. L'entreprise pour laquelle nous avons réalisé ce projet ne fait pas exception à la règle : elle lance près de 50 à 60 innovations (nouveaux produits) chaque année.
Nous définissons une innovation comme le lancement d'une nouvelle marque de produit ou l'introduction d'un nouveau produit avec une nouvelle saveur dans une marque déjà existante. Après un certain temps (par exemple, dans notre cas, deux mois), une innovation devient un produit ordinaire.
Il existe d'autres cas où un nouveau code produit peut être généré, par exemple
Nous n'avons pas considéré ces cas comme des innovations mais comme des rénovations et ils sont donc hors de notre champ.Nous avons eu accès aux lancements de produits avec des ventes data de 2017 à 2019, soit environ 150 produits d'innovation.
Le principal défi
Notre tâche consistait à établir des prévisions hebdomadaires pour les 14 semaines à venir au niveau de l'Union européenne. entrepôt/quotidien/produit niveau.
La première fois que le modèle a dû être appliqué, c'était pour la première fois. 7 jours après son lancement, Cela signifie qu'il ne dispose que de 7 jours d'historique data et qu'il doit prévoir les ventes pour les 14 x 7 = 98 jours à venir ! La dernière fois que nous avons dû appliquer le modèle, c'était pour 60 jours après le lancement. Cela signifie qu'un produit lancé serait considéré comme un “produit normal” après 2 mois, puisqu'il aurait atteint une certaine “stabilité” dans ses cycles de vente, mais bien sûr, cela dépendra de l'activité de votre entreprise et de la nature du produit. Après cette phase de deux mois, le modèle de base (modèle développé pour les produits réguliers) prend le relais du modèle d'innovation et établit des prévisions pour le lancement en question. Cette décision a été validée par les équipes commerciales qui avaient une certaine connaissance des cycles de vente des innovations.
Historique très limité data
La quantité de données historiques data dont nous disposons est extrêmement faible pour établir des prévisions précises. Nous disposons d'un ensemble data d'entraînement qui est beaucoup plus petit que notre ensemble data de prédiction/test, ce qui se traduit souvent par une très faible précision des prévisions. Il s'agit de disposer de quelques semaines de data d'entraînement et de devoir faire des prévisions pour 98 jours.
Les produits lancés ont des ventes très instables au début.
En outre, les ventes data sont souvent très irrégulières au cours des premières semaines de lancement, car les tendances peuvent changer radicalement.. En fait, les détaillants commandent d'énormes quantités de l'innovation au cours des deux premières semaines pour remplir leurs rayons. la phase d'exécution. Ensuite, les commandes chutent généralement sur W3 et W4, puis elles augmentent légèrement.
Là encore, beaucoup de choses peuvent se produire : certains détaillants peuvent se rendre compte que le nouveau produit ne se vend pas très bien au cours des premières semaines dans leurs magasins et, par conséquent, réduire drastiquement leurs commandes en guise de réaction rapide. Ou bien un produit peut faire l'objet d'énormes volumes de commandes de la part de certains détaillants que le fabricant n'est pas en mesure de satisfaire entièrement parce qu'il n'a pas anticipé ce niveau de demande. Les détaillants continueront à commander des volumes importants au cours des semaines suivantes pour compenser les volumes pour lesquels ils n'ont pas été entièrement livrés.
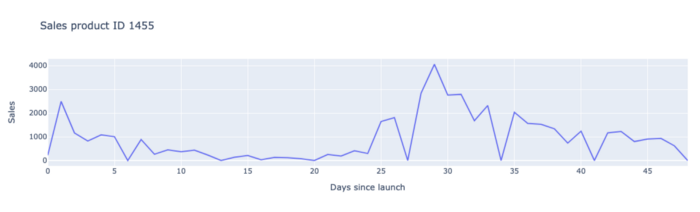
Tous les éléments énumérés ci-dessus expliquent clairement pourquoi il est difficile de prévoir les ventes d'innovations et donc pourquoi nous avons dû développer un modèle spécifique pour ces produits.
Critères d'évaluation
Nous avons utilisé les mêmes critères d'évaluation que pour les produits réguliers (précision des prévisions W+1 et W+2 au niveau national/hebdomadaire). Pour rappel, voici la formule de la précision d'une prévision :
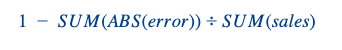
Nous avons ajouté une autre dimension à ce problème. Nous avons calculé ces paramètres pour chaque date de prédiction (date à laquelle nous faisons notre prédiction) en ce qui concerne la date de lancement.
Nous avons contrôlé la précision des prévisions W+1 et W+2 pour des dates de prévision allant de J+7 à J+49, ce qui signifie que notre tableau de bord ressemblerait à ceci :
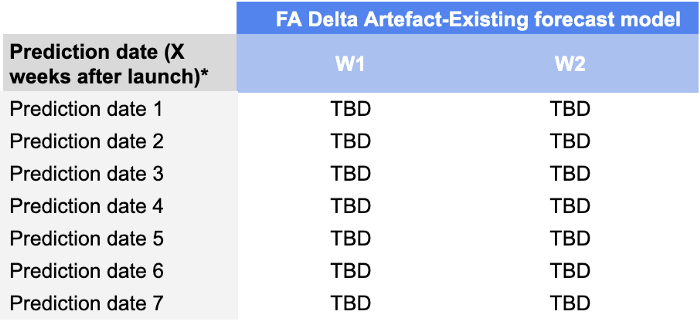
La raison pour laquelle nous avons ajouté cette dimension est qu'il est très important pour les planificateurs de la demande de surveiller les performances de leurs prévisions au cours des premières semaines de lancement. Un modèle qui fournit des prévisions de bonne qualité au cours des premières semaines leur permet d'éviter les gros problèmes de réapprovisionnement (qui sont fréquents après le lancement en raison de l'incertitude) et, en fin de compte, de réussir leur lancement.
Approche proposée
Pourquoi la ML classique n'a-t-elle pas donné de bons résultats ?
Comme nous l'avons dit précédemment, nous sommes confrontés à un problème de “petite data”. La petite taille de notre data d'entraînement et sa nature très erratique ne conviennent pas à un modèle d'apprentissage automatique.
Le plus souvent, les modèles de boosting nécessitent 2 à 3 ans d'historique des ventes data pour détecter les tendances générales/effets de saisonnalité et au moins 2 à 3 mois de séries temporelles data pour un produit afin de faire des “prédictions précises”. Ce n'était pas le cas pour nous ; notre modèle XGBoost ne voyait que quelques semaines d'historique des ventes pour chaque produit.
Nous avons formé un modèle XGBoost sur les produits innovants selon la logique suivante
Et les résultats n'étaient pas bons du tout ! Nous avons donc décidé de changer complètement notre approche pour ces produits.

Les modèles classiques de séries temporelles n'ont pas non plus sauvé la situation
Notre première tentative avec XGBoost ayant été un échec total, nous avons décidé de tenter notre chance avec quelques bons vieux modèles de séries temporelles (VARMA, SARIMAX, Prophet, etc.). Les modèles de séries temporelles ont la vertu d'être plus simples et plus faciles à interpréter que les modèles de boosting. De plus, comme ils sont entraînés sur un seul produit, ils s'adaptent plus facilement aux changements brusques de tendance.
L'idée était d'entraîner un modèle (un modèle Prophet par exemple) par produit qui ferait des prévisions au niveau national/quotidien. Comme ci-dessus, le modèle serait entraîné plusieurs fois, chaque fois jusqu'à la veille de la date de prévision (J+7, J+14, etc.) et ferait des prévisions pour l'horizon de 14 semaines.
Mais ici, comme ci-dessus, les résultats n'étaient toujours pas satisfaisants et la raison était à peu près la même : pas assez d'historique data ! L'historique était trop peu profond et le data était trop désordonné pour que le modèle puisse comprendre un modèle clair et faire des prédictions précises.
Regroupement de produits basé sur les ressemblances : le Messie
Nos deux premières tentatives de prévisions n'ayant pas été concluantes, nous avons décidé de nous engager dans une toute autre voie.
Nous avons analysé les ventes de toutes les innovations de 2017 à 2019 et nous avons réalisé que beaucoup d'entre elles avaient des courbes de ventes similaires au cours des premiers mois de leur lancement respectif, ce qui nous a donné l'idée de faire des prévisions basées sur les similitudes des produits avec d'anciennes innovations. Notre intuition a été renforcée par le fait que nous avons trouvé des articles de recherche d'autres collègues scientifiques de data suggérant une approche similaire (1).
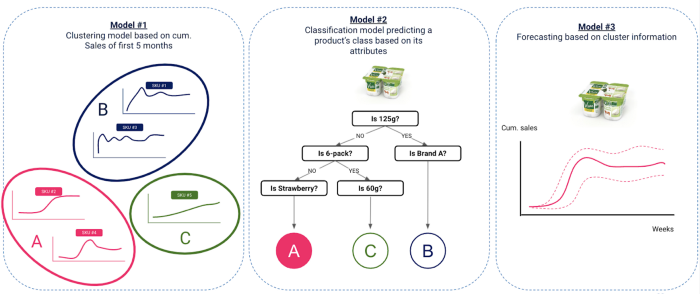
Notre approche a consisté en trois étapes fondamentales
Regroupement des anciennes innovations en fonction des ventes - périmètre Data : Innovations lancées de 2017 à 2018 incluses
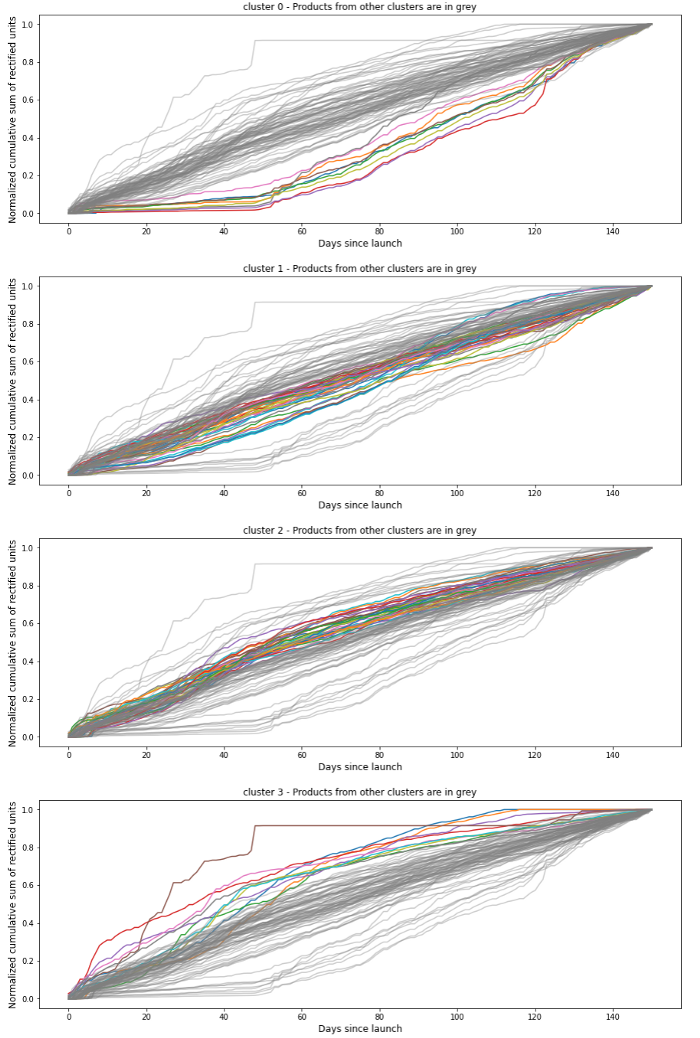
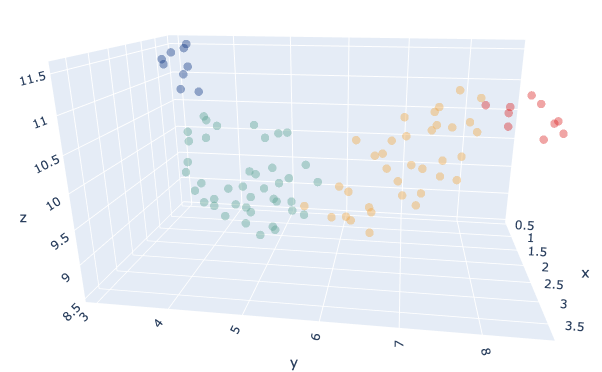
L'idée est de regrouper les anciennes innovations sur la base de leur courbe chronologique en groupes de produits similaires. Les produits appartenant à un même groupe ont des modèles de vente similaires et les ventes d'une innovation unique peuvent donc être déduites de la connaissance des ventes d'innovations plus anciennes.
Notre entrée data était la Ventes cumulées normalisées MinMax des anciennes innovations au cours de leurs 5 premiers mois d'existence. Nous avons examiné les ventes cumulées parce que nous voulions que notre modèle de regroupement ait une idée du moment où chaque produit atteindrait son rythme de vente habituel. Nous avons normalisé les ventes cumulées parce que certains produits avaient la même forme de courbe mais un volume de ventes différent et que nous voulions les placer dans le même groupe, puisque nous nous concentrons ici sur la similarité.
Nous avons regroupé nos produits avec un Modèle K-Means le paramètre K étant choisi automatiquement à l'aide d'un test de référence utilisant la méthode Index des silhouettes.Le nombre optimal était K=4.Nous avons également essayé différentes mesures de distance entre les euclidienne et DTW, avec euclidean qui a donné des résultats plus satisfaisants lors de nos tests.
Modèle de classification prédisant la grappe d'un produit en fonction de ses attributs - Data scope : Innovations lancées de 2017 à 2018 incluses
L'idée est ici de trouver un lien entre le groupe auquel le produit appartient et ses attributs, tels que la dimension, la marque, la saveur, etc. ainsi que certains éléments contextuels tels que la période de lancement, les campagnes médiatiques, etc. Ce lien serait trouvé à l'aide d'un modèle de classification.
Le modèle serait alimenté par les attributs du produit ainsi que par le contexte data et il essaierait de prédire le groupe d'innovations sur la base de ces attributs. L'intuition derrière cette approche est de voir si nous pouvons répondre à la question suivante :
Si nous connaissons à l'avance les attributs d'une innovation + le contexte data, pouvons-nous prédire le type de comportement de vente que ce produit aura après son lancement ?
Étant donné que nous disposions d'un nombre très limité de data (environ 100 produits), nous avons formé un simple classificateur de bagging sur nos produits avec une répartition 75%-25% entre la formation et le test. Nous avons obtenu un Score F1 de 84% sur l'ensemble de tests.
Nous avons effectué une analyse des attributs des produits pour voir si nous pouvions trouver une explication commerciale pour chaque groupe et voici nos conclusions :
Prévision des ventes de nouvelles innovations sur la base des clusters prévus - périmètre Data : Innovations lancées après 2019
Maintenant que nous sommes en mesure de relier les ventes d'une innovation à ses attributs, nous pouvons appliquer notre modèle aux nouvelles innovations pour déterminer leur regroupement et donc prédire leurs ventes.
Nous avons commencé très simplement. Pour pour chaque nouvelle innovation (lancée après 2019), nous avons calculé les ventes moyennes des anciennes innovations (lancées avant 2019) qui se trouvaient dans le même groupe que la nouvelle innovation, au cours de leurs premières semaines de lancement. et nous l'avons considéré comme notre prévision pour la nouvelle innovation.
Cette approche simpliste était en fait un bon début, mais elle présentait un défaut majeur : nous avons pu prédire avec précision la forme de la nouvelle innovation, mais l'échelle de notre prédiction n'était pas bonne.
Nous avons décidé d'échelonner nos prédictions en comparant les ventes de la nouvelle innovation et des anciennes innovations similaires entre J+0 et la date de prédiction (date de prédiction). Étant donné que la vente à perte data était aussi pertinente que la vente à l'entrée data pour prédire la vente à l'entrée future dans notre cas, nous avons calculé deux coefficients d'échelle, l'un pour la vente à l'entrée et l'autre pour la vente à l'entrée.
Coefficient de vente = vente moyenne d'anciennes innovations similaires jusqu'à la date de prédiction / vente moyenne d'une nouvelle innovation jusqu'à la date de prédiction
Coefficient d'écoulement = écoulement moyen des anciennes innovations similaires jusqu'à la date de prédiction / écoulement moyen de la nouvelle innovation jusqu'à la date de prédiction
Enfin, nous avons augmenté/diminué nos prédictions en fonction de la moyenne de ces deux coefficients.
Résultats et conclusions
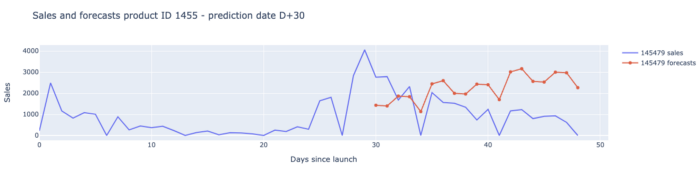
Voici nos résultats pour chaque date de prédiction et chaque horizon de prédiction :
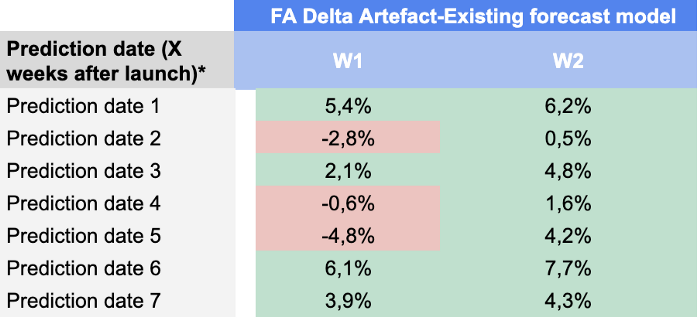
Nous avons été assez satisfaits de ces résultats car notre modèle a été capable de battre les prévisions des planificateurs de la demande dans presque tous les indicateurs clés de performance jusqu'à la date de prédiction 49.
Références
1. Prévision des nouveaux produits avec des produits analogues<
Je tiens à remercier toutes les personnes qui ont travaillé sur ce projet, en particulier Sylvain Combettes, sans qui cet article n'aurait jamais été écrit.
Et merci d'avoir lu jusqu'ici ! Je serais heureux d'entendre vos commentaires. Si vous avez apprécié cette lecture, n'hésitez pas à consulter notre rubrique postes ouverts à l'adresse Artefact 🙂 .
