

作者


到目前为止,我们主要讨论的是对已上架一段时间的常规产品的预测。那么,最近上市的产品呢?
在本文中,我们将向您展示我们是如何解决这一问题的,我们提出了一种基于产品外观相似度的提升模型替代解决方案。.
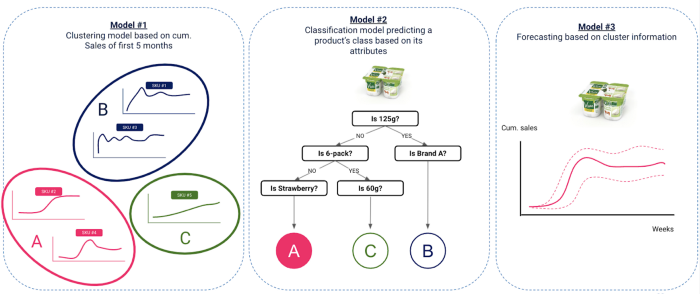
它包括在旧创新产品上训练一个聚类模型,以检测销售模式的相似性,然后用分类模型将其映射到产品特征上,再根据模型 1 和模型 2 的输出结果,用简单的统计方法推断新创新产品的销售情况。.
为什么预测新推出的产品如此困难?
背景介绍
产品发布在零售业非常常见。消费类商品公司的天性是使其产品多样化。他们希望吸引顾客,使产品适应行为变化。我们为之开展项目的公司也不例外,他们几乎每年都会推出 50-60 种创新产品(新产品)。.
我们将创新定义为推出一个新的产品品牌,或在已有品牌的基础上推出一种新口味的新产品。经过一段时间(例如,在我们的案例中为 2 个月)后,创新产品就会成为常规产品。.
在其他情况下,也可以生成新的产品代码,例如
我们不认为这些案例是创新,而是翻新,因此它们不在我们的研究范围内。我们可以获得 2017 年至 2019 年销售额为 data 的产品发布信息,因此大约有 150 种创新产品。.
主要挑战
我们的工作是每周预测未来 14 周的天气情况。 仓库/每日/产品 水平。.
第一次应用该模型是 发射 7 天后, 这意味着它只有 7 天的 data 历史数据,必须预测未来 14 x 7 = 98 天的销售情况!我们最后一次应用该模型是 发射后 60 天. .这意味着推出的产品在 2 个月后将被视为 “常规产品”,因为它的销售周期已达到一定的 “稳定性”,当然,这取决于贵公司的活动和产品性质。2 个月后,核心模型(为常规产品开发的模型)将取代创新模型,并对特定的发布产品进行预测,这一决定得到了对创新产品销售周期有一定了解的业务团队的认可。.
非常有限的历史 data
我们可以利用的历史 data 数量少得可怜,根本无法做出准确的预测。我们的训练 data 集远远小于我们的预测/测试 data 集,这往往会导致预测准确率非常低。我们的训练 data 只有几周的时间,却要对 98 天的时间进行预测。.
推出的产品一开始销售很不稳定
此外, data 在推出的头几周,销售情况往往非常混乱,因为趋势会发生急剧变化. .事实上,零售商会在头两周大量订购这种创新产品,以填充货架,他们称之为 "创新"。 履行阶段。. 之后,W3 和 W4 的订单量普遍下降,然后订单量又略有增加。.
同样,这里也可能发生很多情况:一些零售商可能会意识到,新产品在其商店销售的头几周并不畅销,因此,作为一种快速反应,他们会大幅减少订单。或者,一些零售商可能会大量订购某种产品,而制造商可能无法完全满足这些订单,因为他们没有预料到会有如此大的需求量。在接下来的几周里,零售商会继续大量订货,以弥补未能完全交付的订单量。.
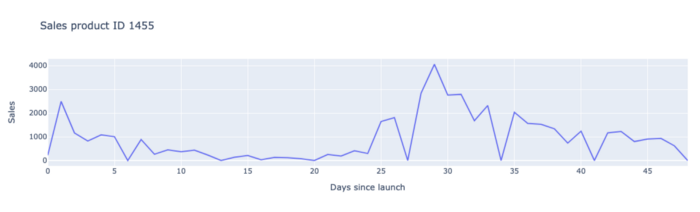
上述所有因素都清楚地说明了为什么创新产品的销售很难预测,因此我们必须为这些产品开发一个特定的模型。.
评估标准
我们采用了与常规产品相同的评估指标(全国/周级别的 W+1 和 W+2 预测准确率)。以下是预测准确率的计算公式:
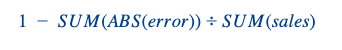
我们为这个问题增加了另一个维度。我们为每个 预测日期 (我们作出预测的日期)的发射日期。.
我们对从 D+7 到 D+49 的预测日期的 W+1 和 W+2 预测准确率进行了监测,也就是说,我们的记分卡是这样的:
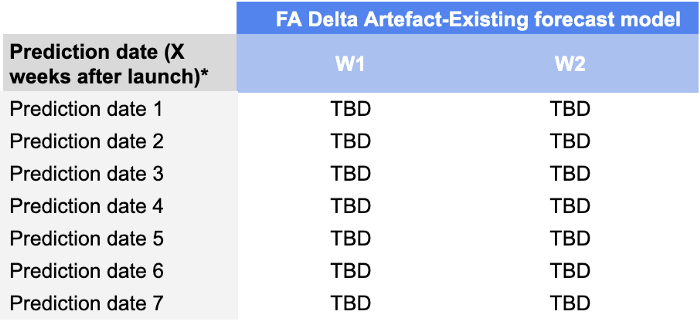
我们添加这一维度的原因是,对于需求计划人员来说,在投放的前几周监控其预测的执行情况是非常重要的。一个能在前几周提供高质量预测的模型能使他们避免出现大的补货问题(由于不确定性,这种问题在投放后很常见),并最终成功投放。.
建议的方法
为什么经典的 ML 方法效果不佳?
如前所述,我们遇到了一个 “小 data ”问题。我们训练的 data 体积很小,而且非常不稳定,因此不适合机器学习模型。.
大多数情况下,助推模型需要 2-3 年的历史销售 data 来检测总体趋势/季节性效应,并且至少需要 2-3 个月的时间序列 data 来对一种产品进行 “准确预测”。我们的情况并非如此;我们的 XGBoost 模型只能看到每个产品几周的历史销售额。.
我们在创新产品上训练了一个 XGBoost 模型,其逻辑如下
但结果并不理想!因此,我们决定彻底改变这些产品的生产方式。.

经典的时间序列模型也没能拯救世界
由于我们第一次使用 XGBoost 完全失败,我们决定用一些老式的时间序列模型(VARMA、SARIMAX、Prophet 等)试试运气。与 boosting 模型相比,时间序列模型具有更简单、更易于解释的优点。此外,由于它们是在一个产品上进行训练的,因此更容易适应突然的趋势变化。.
我们的想法是为每个产品训练一个模型(例如先知模型),该模型将进行全国/每日级别的预测。和上面一样,该模型也将训练多次,每次训练到预测日期的前一天(D+7、D+14 等),并对 14 周的范围进行预测。.
但在这里,和上面一样,结果仍然不尽人意,原因大致相同:没有足够的历史 data!历史太浅,data 太乱,模型无法理解清晰的模式并做出准确的预测。.
基于外观相似度的产品聚类:弥赛亚
由于最初的两次预测都没有结果,我们决定完全换一个方向。.
我们分析了 2017 年至 2019 年所有创新产品的销售情况,发现许多创新产品在各自上市的前几个月都有相似的销售曲线,这让我们萌生了根据产品与旧创新产品的相似性进行预测的想法。我们发现其他 data 同行科学家的一些研究论文也提出了类似的方法(1),这更加坚定了我们的直觉。.
我们的方法包括 3 个基本步骤
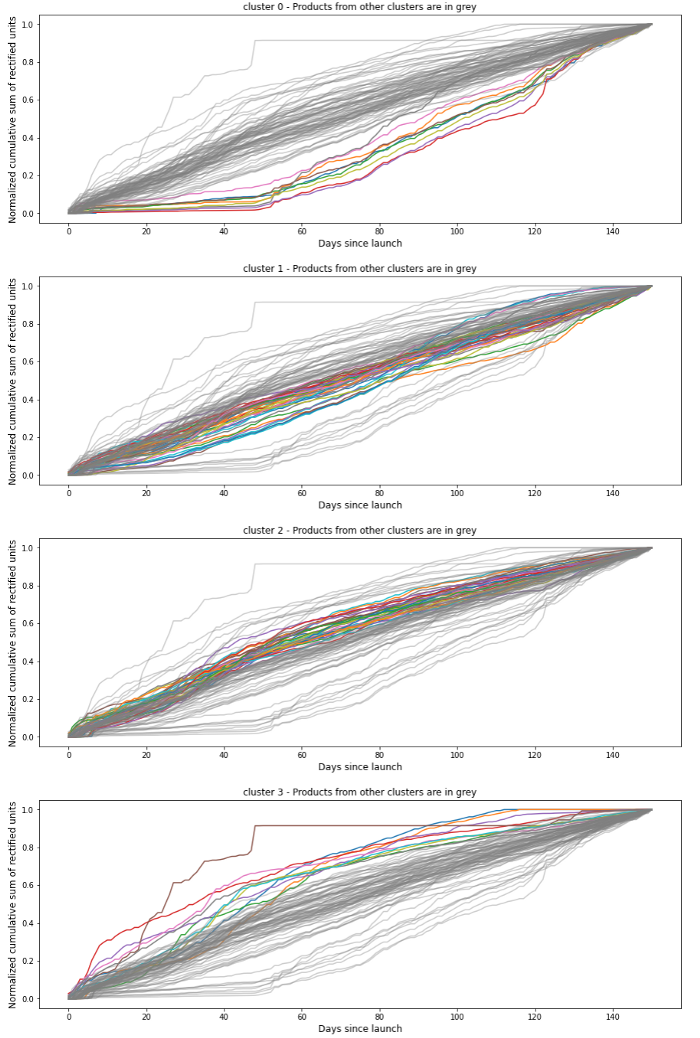
根据销售额对旧创新进行分组 - Data 范围:2017 年至 2018 年推出的创新包括
其原理是根据旧创新产品的时间序列曲线,将其归类为同类产品组。同一组中的产品具有相似的销售模式,因此可以通过了解旧创新产品的销售情况来推断单一创新产品的销售情况。.
我们的输入 data 是 MinMax 旧创新产品头 5 个月的正常化累计销售额. .我们之所以研究累计销售额,是因为我们希望聚类模型能够了解每种产品何时会达到正常的销售速度。我们对累计销售额进行了归一化处理,因为有些产品的曲线形状相同,但销售量却不同,我们希望将它们归入同一聚类,因为我们在这里关注的是相似性。.
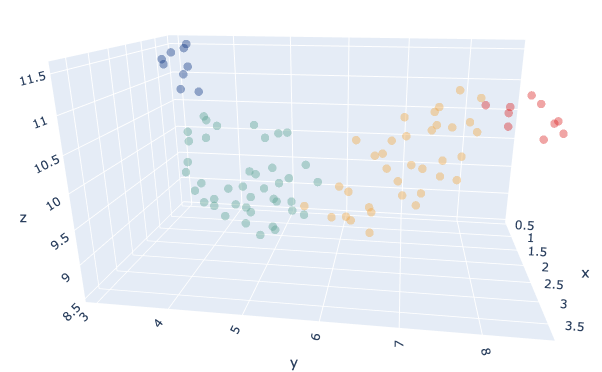
我们将我们的产品与 K-Means 模型 K 参数是通过使用 轮廓索引.最佳数量为 K=4。.我们还尝试了 欧几里得 和 DTW、, 在我们的测试中,欧几里得的结果更令人满意。.
根据产品属性预测产品集群的分类模型 - Data 范围:2017 年至 2018 年推出的创新包括
这里的想法是找到产品所属群组与其属性(如尺寸、品牌、口味等)以及一些上下文 data(如发布时间、媒体宣传等)之间的联系。这种联系将在分类模型的帮助下找到。.
该模型将获得产品属性和上下文 data,并以此为基础尝试预测创新集群。这种方法背后的直觉是,我们能否回答以下问题:......?
如果我们事先知道创新产品的属性+情境 data,我们能否预测该产品上市后的销售行为?
由于我们只有非常有限的 data(大约 100 个产品),因此我们对产品进行了简单的 BaggingClassifier 训练,训练/测试时间为 75%-25%。我们最终得到了 84% 的 F1 分数 在测试集上。.
我们对产品属性进行了一些分析,看看能否为每个群组找到一些商业解释,以下是我们的发现:
根据预测群组预测新创新产品的销售额 - Data 范围:2019 年后推出的创新产品
既然我们能够将创新产品的销售额与其属性联系起来,我们就可以将我们的模型应用于新的创新产品,以确定其群组,从而预测其销售额。.
我们一开始做得很简单。对于 对于每项新创新(2019 年后推出),我们计算了与新创新同属一个群组的旧创新(2019 年前推出)在推出首周的平均销售额 并将其视为我们对新创新的预测。.
这种简单化的方法实际上是一个良好的开端,但有一个重大缺陷:我们能够准确预测新创新的形态,但预测的规模却不理想。.
我们决定通过比较从 D+0 到预测日(预测日)期间新创新产品和旧有同类产品的销售情况来对我们的预测进行缩放。由于在我们的案例中,卖出 data 与卖入 data 在预测未来卖出方面具有同样的洞察力,因此我们计算了两个缩放系数,一个是卖入系数,另一个是卖出系数。.
销售系数 = 预测日之前旧的类似创新的平均销售额/预测日之前新的创新的平均销售额
销售系数 = 预测日期前旧有类似创新的平均销售额/预测日期前新创新的平均销售额
最后,我们用这两个系数的平均值对预测结果进行升幂/降幂处理。.
结果和结论
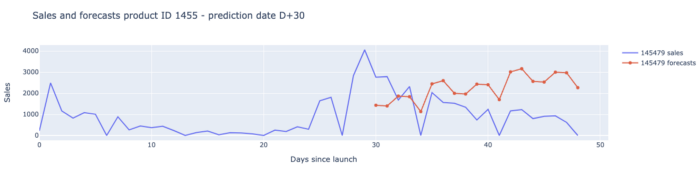
以下是我们对每个预测日期和预测范围的结果:
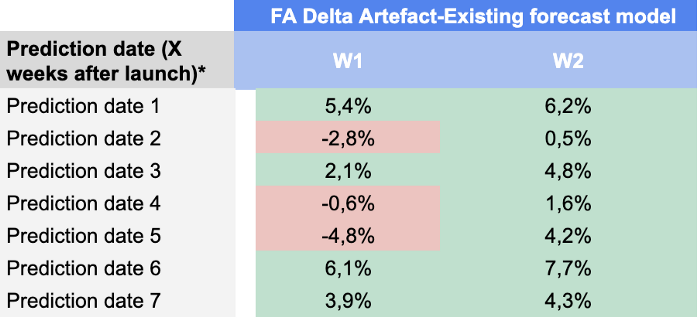
我们对这些结果非常满意,因为在预测日期 49 之前,我们的模型几乎在所有关键绩效指标上都超过了需求规划人员的预测。.
参考资料
1. 利用类比产品进行新产品预测<
我要感谢参与这个项目的所有人,特别是 Sylvain Combettes,没有他,这篇文章永远也写不出来。
感谢您读到这里!我很高兴听到您的反馈意见。如果您喜欢阅读,请随时查看我们的 空缺职位 在 Artefact 🙂

