

Autor


Bisher haben wir vor allem über Prognosen für reguläre Produkte gesprochen, die schon seit einiger Zeit im Regal stehen. Aber was ist mit Produkten, die erst vor kurzem auf den Markt gekommen sind?
In diesem Artikel zeigen wir Ihnen, wie wir dieses Problem angegangen sind, indem wir eine alternative Lösung für unser Boosting-Modell vorgeschlagen haben, die auf Produktähnlichkeiten basiert.
Es besteht darin, ein Clustermodell für alte Innovationen zu trainieren, um Ähnlichkeiten in den Absatzmustern zu erkennen, diese dann mit einem Klassifizierungsmodell auf Produktmerkmale abzubilden und dann mit einfachen statistischen Methoden auf der Grundlage der Ergebnisse von Modell 1 und 2 auf den Absatz der neuen Innovation zu schließen.
Warum ist es so schwierig, die Markteinführung neuer Produkte vorherzusagen?
Ein wenig Kontext
Produkteinführungen sind im Einzelhandel sehr üblich. Es liegt in der Natur von Konsumgüterherstellern, ihre Produkte zu diversifizieren. Sie wollen ihre Kunden ansprechen und ihre Produkte an Verhaltensänderungen anpassen. Das Unternehmen, für das wir das Projekt durchgeführt haben, war da keine Ausnahme. Es bringt jedes Jahr fast 50-60 Innovationen (neue Produkte) heraus.
Wir definieren eine Innovation eher als eine neue Produktmarke, die auf den Markt gebracht wird, oder als ein neues Produkt mit einer neuen Geschmacksrichtung, das zu einer bereits bestehenden Marke hinzugefügt wird. Nach einer gewissen Zeit (in unserem Fall zum Beispiel 2 Monate) wird eine Innovation zu einem regulären Produkt.
Es gibt andere Fälle, in denen ein neuer Produktcode generiert werden kann, wie z.B.
Wir betrachten diese Fälle nicht als Innovationen, sondern als Renovierungen und daher fallen sie nicht in unseren Anwendungsbereich. Wir hatten Zugang zu Produkteinführungen mit einem Umsatz von data von 2017 bis 2019, also etwa 150 innovative Produkte.
Die größte Herausforderung
Unsere Aufgabe war es, wöchentliche Prognosen für die kommenden 14 Wochen zu erstellen Lager/Tag/Produkt Niveau.
Das erste Mal, dass das Modell angewendet werden musste, war 7 Tage nach seinem Start, d.h. es hätte nur 7 Tage historische data und müsste die Verkäufe für die kommenden 14 x 7 = 98 Tage vorhersagen! Das letzte Mal, dass wir das Modell anwenden mussten, war 60 Tage nach dem Start. Das bedeutet, dass ein eingeführtes Produkt nach 2 Monaten als “reguläres Produkt” betrachtet wird, da es eine gewisse “Stabilität” in seinen Verkaufszyklen erreicht hat, aber das hängt natürlich von der Aktivität Ihres Unternehmens und der Art des Produkts ab. Nach dieser 2-monatigen Phase würde das Kernmodell (das für reguläre Produkte entwickelt wurde) das Innovationsmodell übernehmen und Prognosen für die jeweilige Markteinführung erstellen. Diese Entscheidung wurde von den Geschäftsteams bestätigt, die über einige Kenntnisse der Verkaufszyklen von Innovationen verfügen.
Sehr begrenzt historisch data
Die Menge an historischen data, die uns zur Verfügung steht, ist für genaue Prognosen kritisch gering. Wir haben ein Trainings-dataset, das viel kleiner ist als unser Vorhersage-/Test-dataset, und das führt oft zu einer sehr schlechten Prognosegenauigkeit. Wir sprechen hier von einem Trainings-data von einigen Wochen und müssen Prognosen für 98 Tage erstellen.
Eingeführte Produkte haben anfangs sehr instabile Verkaufszahlen
Außerdem, Die Verkäufe von data sind in den ersten Wochen nach der Markteinführung oft sehr chaotisch, da sich die Trends dramatisch ändern können.. In der Tat bestellen die Einzelhändler in den ersten 2 Wochen riesige Mengen der Innovation, um ihre Regale aufzufüllen, sie nennen dies die Erfüllungsphase. Danach gehen die Bestellungen im Allgemeinen auf W3 und W4 zurück und steigen dann wieder etwas an.
Auch hier kann viel passieren: Einige Einzelhändler stellen vielleicht fest, dass sich das neue Produkt in den ersten Wochen in ihren Geschäften nicht besonders gut verkauft und reduzieren daher als schnelle Reaktion ihre Bestellungen drastisch. Oder ein Produkt kann von einigen Einzelhändlern in großen Mengen bestellt werden, die der Hersteller nicht vollständig erfüllen kann, weil er nicht mit dieser Nachfrage gerechnet hat. Die Einzelhändler werden in den folgenden Wochen weiterhin große Mengen bestellen, um die Mengen zu kompensieren, für die sie nicht vollständig beliefert wurden.
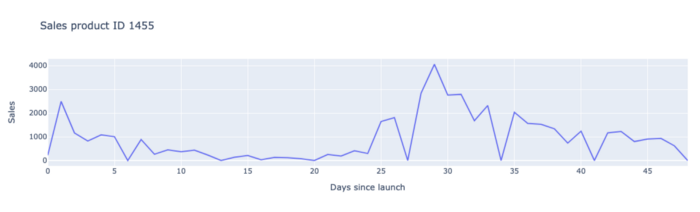
All die oben aufgeführten Elemente sind eine klare Erklärung dafür, warum die Vorhersage von Innovationsverkäufen schwierig ist und warum wir daher ein spezielles Modell für diese Produkte entwickeln mussten.
Bewertungskriterien
Wir hatten die gleichen Bewertungsmaßstäbe wie für reguläre Produkte (W+1 und W+2 Vorhersagegenauigkeit auf nationaler/wöchentlicher Ebene). Zur Erinnerung: Hier ist die Formel für die Vorhersagegenauigkeit:
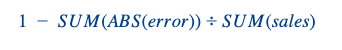
Wir haben diesem Problem eine weitere Dimension hinzugefügt. Wir haben diese Metriken für jede Vorhersagedatum (das Datum, an dem wir unsere Vorhersage machen) in Bezug auf den Starttermin.
Wir haben die W+1- und W+2-Prognosegenauigkeit für Vorhersagedaten von T+7 bis T+49 überwacht, was bedeutet, dass unsere Scorecard wie folgt aussehen würde:
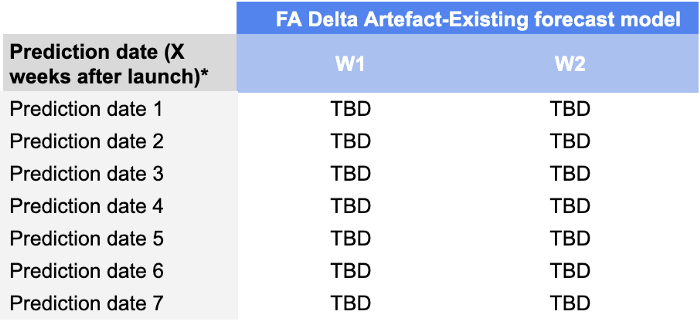
Der Grund, warum wir diese Dimension hinzugefügt haben, ist, dass es für Bedarfsplaner sehr wichtig ist, die Leistung ihrer Prognosen in den ersten Wochen der Markteinführung zu überwachen. Ein Modell, das in den ersten Wochen gute Prognosen liefert, ermöglicht es ihnen, große Nachschubprobleme zu vermeiden (die nach der Markteinführung aufgrund von Ungewissheit häufig auftreten) und letztendlich erfolgreich zu sein.
Vorgeschlagener Ansatz
Warum hat das klassische ML schlechte Ergebnisse geliefert?
Wie bereits gesagt, haben wir ein “kleines data” Problem. Die geringe Größe unseres Trainings data und seine sehr erratische Natur machen es für ein maschinelles Lernmodell ungeeignet.
Meistens benötigen Boosting-Modelle 2-3 Jahre historischer Verkäufe data, um allgemeine Trends/Saisonalitätseffekte zu erkennen, und mindestens 2-3 Monate der Zeitreihe data für ein Produkt, um “genaue Vorhersagen” zu machen. Dies war bei uns nicht der Fall. Unser XGBoost-Modell sah nur ein paar Wochen historischer Verkäufe für jedes Produkt.
Wir haben ein XGBoost-Modell auf Innovationsprodukte mit der folgenden Logik trainiert
Und die Ergebnisse waren ganz und gar nicht gut! Deshalb haben wir beschlossen, unseren Ansatz für diese Produkte komplett zu ändern.

Auch klassische Zeitreihenmodelle haben den Tag nicht gerettet
Da unser erster Versuch mit XGBoost ein totaler Fehlschlag war, haben wir beschlossen, unser Glück mit einigen guten altmodischen Zeitreihenmodellen (VARMA, SARIMAX, Prophet, usw.) zu versuchen. Zeitreihenmodelle haben den Vorzug, dass sie einfacher und leichter zu interpretieren sind als Boosting-Modelle. Da sie auf ein einziges Produkt trainiert werden, können sie sich außerdem leichter an abrupte Trendänderungen anpassen.
Die Idee war, ein Modell (z.B. ein Prophet-Modell) pro Produkt zu trainieren, das Vorhersagen auf nationaler/täglicher Ebene machen würde. Wie oben beschrieben, würde das Modell auch mehrmals trainiert werden, jedes Mal bis zum Tag vor dem Vorhersagedatum (T+7, T+14 usw.), und Prognosen für den 14-Wochen-Horizont erstellen.
Aber auch hier waren die Ergebnisse nicht zufriedenstellend und der Grund dafür war so ziemlich derselbe: nicht genügend historische data! Die Historie war zu oberflächlich und die data zu unübersichtlich, als dass das Modell ein klares Muster hätte erkennen und genaue Vorhersagen machen können.
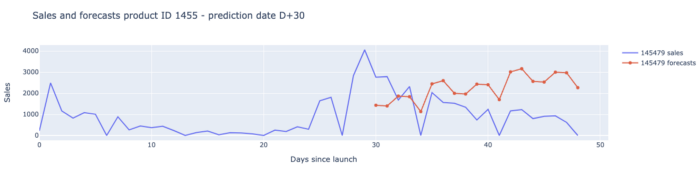
Produkt-Clustering auf der Grundlage von Ähnlichkeiten: der Messias
Da unsere beiden ersten Versuche, Prognosen zu erstellen, nicht schlüssig waren, haben wir beschlossen, eine ganz andere Richtung einzuschlagen.
Wir analysierten die Umsätze aller Innovationen von 2017 bis 2019 und stellten fest, dass viele in den ersten Monaten ihrer jeweiligen Einführung ähnliche Umsatzkurven aufwiesen. Das brachte uns auf die Idee, Prognosen auf der Grundlage von Produktähnlichkeiten mit alten Innovationen zu erstellen. Unsere Intuition wurde gestärkt, da wir einige Forschungsarbeiten anderer data-Kollegen fanden, die einen ähnlichen Ansatz vorschlugen (1).
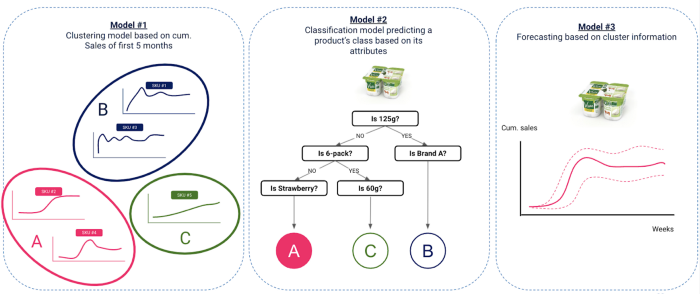
Unser Ansatz bestand aus 3 grundlegenden Schritten
Clustering alter Innovationen auf der Grundlage des Umsatzes - Data scope : Innovationen, die von 2017 bis 2018 eingeführt wurden, enthalten
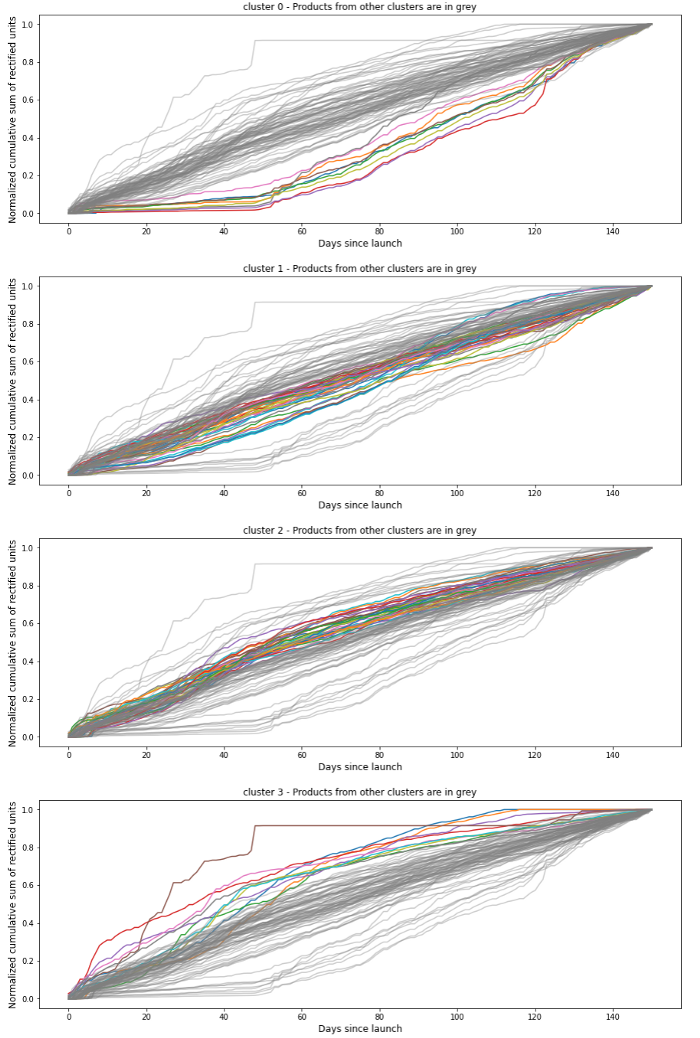
Die Idee besteht darin, alte Innovationen auf der Grundlage ihrer Zeitreihenkurve in Gruppen ähnlicher Produkte zu gruppieren. Produkte, die sich im gleichen Cluster befinden, haben ähnliche Absatzmuster. Daher kann der Absatz einer einzelnen Innovation aus der Kenntnis des Absatzes älterer Innovationen abgeleitet werden.
Unsere Eingabe data war die MinMax normalisierte kumulierte Verkäufe von alten Innovationen während ihrer ersten 5 Monate. Wir haben uns die kumulierten Umsätze angesehen, weil wir wollten, dass unser Clustermodell ein Gefühl dafür bekommt, wann jedes Produkt sein reguläres Umsatztempo erreichen wird. Wir haben die kumulierten Umsätze normalisiert, weil einige Produkte zwar die gleiche Kurvenform, aber unterschiedliche Umsatzvolumina aufwiesen und wir sie in das gleiche Cluster einordnen wollten, da wir uns hier auf die Ähnlichkeit konzentrieren.
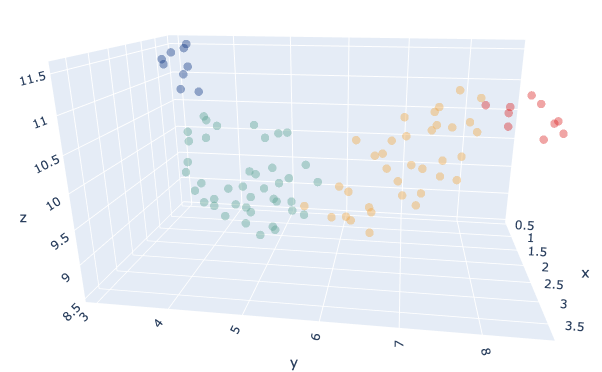
Wir haben unsere Produkte mit einem Cluster versehen K-Means Modell wobei der K-Parameter automatisch durch einen Benchmark ausgewählt wird, der die Scherenschnitt-Index.Die optimale Anzahl war K=4.Wir haben auch verschiedene Abstandsmetriken zwischen euklidisch und DTW, wobei euklidisch bei unseren Tests zufriedenstellendere Ergebnisse lieferte.
Klassifizierungsmodell zur Vorhersage des Clusters eines Produkts auf der Grundlage seiner Attribute - Data scope : Zu den von 2017 bis 2018 eingeführten Innovationen gehören
Die Idee dabei ist, eine Verbindung zwischen dem Cluster, zu dem das Produkt gehört, und seinen Attributen wie Dimension, Marke, Geschmack usw. sowie einigen kontextbezogenen data wie Einführungszeitraum, Medienkampagnen usw. zu finden. Diese Verbindung wird mit Hilfe eines Klassifizierungsmodells gefunden.
Das Modell würde mit Produktattributen zusammen mit kontextbezogenen data gefüttert werden und versuchen, auf dieser Grundlage das Cluster einer Innovation vorherzusagen. Die Intuition hinter diesem Ansatz ist, zu sehen, ob wir die folgende Frage beantworten können:
Wenn wir die Eigenschaften einer Innovation + den Kontext data im Voraus kennen, können wir dann vorhersagen, wie sich dieses Produkt nach seiner Einführung verkaufen wird?
Da wir nur eine sehr begrenzte Anzahl von data (etwa 100 Produkte) zur Verfügung hatten, trainierten wir einen einfachen BaggingClassifier auf unsere Produkte mit einem 75%-25%-Train/Test-Split. Am Ende hatten wir eine F1 Ergebnis von 84% auf dem Testset.
Wir haben eine Analyse der Produktattribute durchgeführt, um zu sehen, ob wir eine geschäftliche Erklärung für jedes Cluster finden können, und hier sind unsere Ergebnisse:
Umsatzprognose für neue Innovationen auf der Grundlage von prognostizierten Clustern - Data scope : Innovationen, die nach 2019 eingeführt werden
Da wir nun in der Lage sind, den Umsatz einer Innovation mit ihren Eigenschaften zu verknüpfen, können wir unser Modell auf neue Innovationen anwenden, um ihr Cluster zu bestimmen und somit ihren Umsatz vorherzusagen.
Wir haben ganz einfach angefangen. Für Für jede neue Innovation (die nach 2019 auf den Markt gebracht wurde) haben wir den durchschnittlichen Umsatz der alten Innovationen (die vor 2019 auf den Markt gebracht wurden) berechnet, die sich in den ersten Wochen nach ihrer Einführung im selben Cluster befanden wie die neue Innovation. und betrachteten dies als unsere Prognose für die neue Innovation.
Dieser vereinfachte Ansatz war eigentlich ein guter Anfang, hatte aber einen großen Makel: Wir konnten die Form der neuen Innovation zwar genau vorhersagen, aber der Umfang unserer Vorhersage war nicht gut.
Wir beschlossen, unsere Vorhersagen zu skalieren, indem wir die Verkäufe der neuen Innovation und der alten ähnlichen Innovation von T+0 bis zum Vorhersagedatum (Vorhersagedatum) verglichen. Da Sell-Out data bei der Vorhersage zukünftiger Verkäufe in unserem Fall genauso aufschlussreich war wie Sell-In data, haben wir 2 Skalierungskoeffizienten berechnet, einen mit Sell-In und einen mit Sell-Out.
Sell-in-Koeffizient = durchschnittlicher Sell-in alter ähnlicher Innovationen bis zum Prognosedatum / durchschnittlicher Sell-in neuer Innovationen bis zum Prognosedatum
Ausverkaufskoeffizient = durchschnittlicher Ausverkauf alter ähnlicher Innovationen bis zum Vorhersagedatum / durchschnittlicher Ausverkauf der neuen Innovation bis zum Vorhersagedatum
Schließlich haben wir unsere Vorhersagen mit dem Mittelwert dieser 2 Koeffizienten hoch- bzw. herunterskaliert.
Ergebnisse & Schlussfolgerungen
Hier sind unsere Ergebnisse für jedes Vorhersagedatum und jeden Vorhersagehorizont:
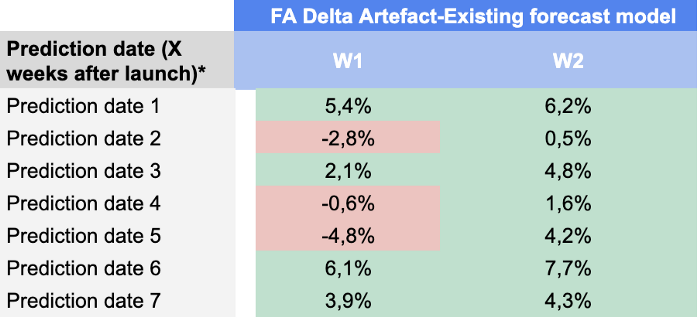
Wir waren mit diesen Ergebnissen recht zufrieden, denn unser Modell konnte die Prognose der Bedarfsplaner in fast jedem KPI bis zum Prognosedatum 49 schlagen.
Referenzen
1. Prognosen für neue Produkte mit analogen Produkten<
Ich möchte mich bei allen bedanken, die an diesem Projekt mitgearbeitet haben, insbesondere bei Sylvain Combettes, ohne den dieser Artikel nie geschrieben worden wäre.
Und danke, dass Sie so weit gelesen haben! Ich würde mich freuen, Ihr Feedback zu hören. Wenn Ihnen die Lektüre gefallen hat, schauen Sie doch mal bei unserem Offene Stellen bei Artefact 🙂
