


作者

2020 年 12 月 14 日
iOS 14 引入了应用程序的选择权限,这将使品牌更难针对个人消费者开展营销活动,也更难衡量营销活动的效果。Artefact 分析和 Data 营销主管 Bobby Gray 分析了这一影响,并解释了品牌如何使用 first-party data 进行应对。.
导言
该项目是 Artefact 在 "科技为善 "方面所做贡献的一部分。该项目是与致力于淋巴瘤合作研究的卡诺 CALYM 研究所和微软公司合作开展的。.
2019 年秋,卡诺 CALYM 研究所启动了一项结构化计划,旨在制定一个路线图,以优化联合体成员 20 多年来开展的临床、转化和临床前研究中 data 的价值评估和利用。该项目由卡诺 CALYM 研究所的卡米尔-洛朗教授(法国图卢兹大学 LYSA、IUCT)和克里斯蒂安娜-科皮教授(法国皮埃尔-贝尼特 LYSARC)提出,是结构化计划的一部分。.
本研究项目的主要目标是开发一种深度学习算法,以协助病理学家诊断滤泡性淋巴瘤。次要目标是确定信息标准,帮助医学专家理解滤泡性淋巴瘤和滤泡性增生(以下简称 FL 和 FH)之间的形态学差异。.
什么是滤泡性淋巴瘤?诊断过程中有哪些困难?
FL 是淋巴瘤的一种亚型,是世界上最常见的血癌。淋巴瘤有 80 多种类型,即使是专家也很难诊断。此外,FL 与不致癌的 FH 非常相似,这也为其诊断增加了难度。.
在这篇文章中,我们将介绍仅使用标记过的整张玻片图像建立 FL 和 FH 分类器的方法。全切片图像是扫描显微镜切片的高分辨率数字文件。在我们的案例中,它们包含淋巴结提取物。.
深度学习如何帮助进行检测?
我们使用 FL 和 FH 的整张幻灯片图像,通过基于斑块的方法训练二元分类器。我们的模型架构是一个简单的 Resnet-18,在几个历时(约 10 个)上进行训练。.
使用分类器预测观察结果的类别后,我们提取最后一个激活层,在输入图像的顶部绘制热图,突出显示促使模型定义特定类别的部分。.
为什么要使用基于斑块的分类方法?
基于斑块的分类法是一种分类技术,它是根据给定观测数据的组成部分(斑块)的预测结果来确定其类别的。在我们的案例中,使用这种方法是因为图像太大,无法直接用于模型。.
事实上,整张幻灯片图像非常大(约 10⁵ 像素见方)。它们的大小使得用普通工具训练深度学习模型几乎不可能。为了解决这个问题,我们按照两个重要标准将其划分为相同大小的斑块:
在基于斑块的分类法中,模型的输出结果可以理解为经典分类法的输出结果,只是第一层计算是在整个幻灯片的层面上进行的。例如,在预测 FL 幻灯片的类别时,98% 的得分意味着由其组成的 98 % 补丁被预测为 FL。.
在 dataset 级,该幻灯片在 FL 级的预测得分为 0.98。.
PS: 我们根据医学专家的结论提出了将图像划分为斑块的假设,医学专家的结论是,在 FL 的整张切片中,卵泡应该无处不在。.
培训集
我们的训练集由 58k 个随机选取的贴片组成 (1024 像素正方形) 从两个类别各 30 幅整张幻灯片图像中提取的 FL 和 FH 值。.
验证集
在训练时,对其中的 20% 补丁进行了采样,以验证模型的性能。.
测试套件
我们的测试集由 15 张整张幻灯片图像组成,每张幻灯片图像都被划分为不同的片段。这个参考集用于比较不同训练方法的结果,我们将在下文中精确说明。.
建模
我们的测试集由 15 张整张幻灯片图像组成,每张幻灯片图像都被划分为不同的片段。这个参考集用于比较不同训练方法的结果,我们将在下文中精确说明。.
在训练深度学习分类器之前 图像准备和处理
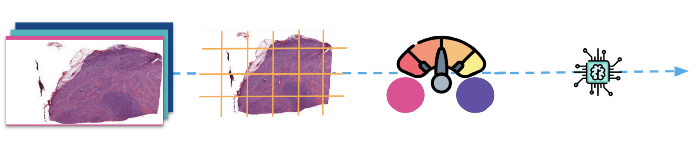
(上图:首先将图像划分为不同的斑块,然后进行归一化处理,再将其输入模型进行训练)。
培训之后:推理和解释
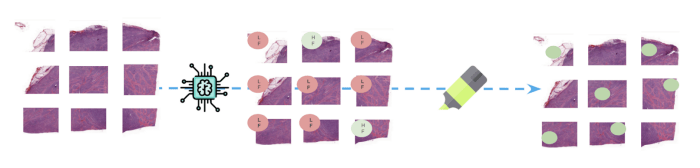
(上图:在推理过程中,新的整张幻灯片会被分割成不同的片段,然后由模型预测出
每一个。突出显示图像中负责预测 FL 类的部分,以帮助监测
结果)。
在下面的章节中,我们将详细介绍管道的这些不同步骤。.
Data 的准备和加工
1 - 瓦工
如前所述,整张幻灯片图像非常大,无法直接输入分类模型,除非使用超级星系硬件。我们使用了 开放式滑道 阅读幻灯片及其 深藏 我们还支持将图像分割成相对较小的 1024 像素正方形瓦片。将图像分割成方块后,我们将其放入一个基本的清除器中,清除所有不在组织中心的方块(边框、孔洞等)。.

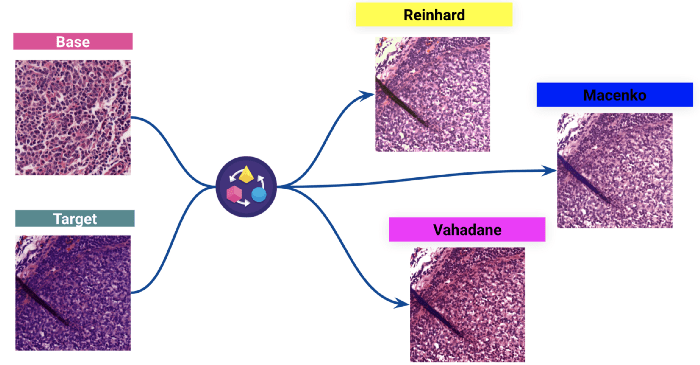
2 - 染色正常化
data 处理的第二步,也是最重要的一步,是染色颜色归一化。染色是突出幻灯片上的重要特征并增强它们之间对比度的过程。使用的染色系统是常见的 H&E (血色素和伊红)。.
然而,由于这些图像来自许多不同的实验室,我们观察到幻灯片的着色存在差异。这些差异主要来自于不同实验室染色工艺的不同。这些差异会严重影响模型的性能。.
在训练模型之前,我们使用经典技术对 dataset 的色彩进行了归一化处理。.
训练 Resnet-18 分类器
在处理整张幻灯片图像后,训练顺利进行(掉帧、权重衰减等)。除了在 data 增强中加入混淆之外,没有任何花哨的地方。我们使用了 Resnet18 由于预先训练的模型并没有明显改善我们的结果,因此我们选择了从头开始训练的 Resnet-18。此外,由于 Resnet-34 和 Resnet-56 并没有提高我们的性能,因此我们更倾向于使用 Resnet-18。经过约 10 个历时后,我们的模型就可以进行测试了。.
我们使用了非常实用的 Fastai 我们的模型库只需花很少的精力就能建立起来。.
测试
3 项实验的结果值得一提:
这 3 次实验的测试集结果如下:
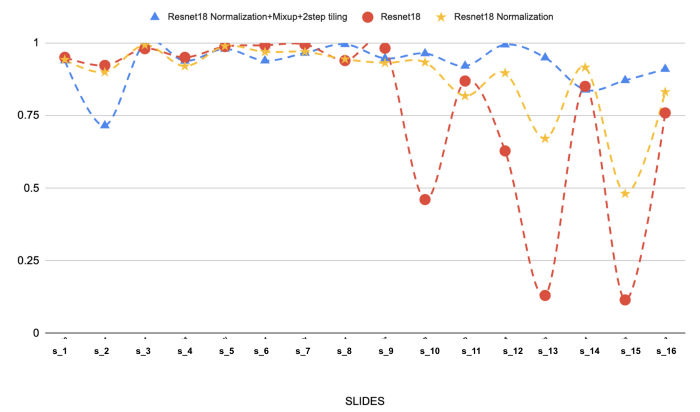
(上图:3 种不同模型在 16 张选定的滤泡淋巴瘤切片上的结果。我们可以看到染色规范化和混淆对性能的影响)。
污点归一化是我们建模方法中最重要的一步。我们遇到过归一化问题(红线),但归一化绝对有助于解决问题。添加混合和两步平铺后,效果会更好。.
MixUp 是一种 data 增强技术,它通过对许多样本进行线性插值来创建新的观测值。.
解读计算机视觉分类器的结果
为了便于向医学专家传达结果,我们提供了带有热图的图像,以突出模型在预测给定标签时的重点。为此,我们提取了卷积网络的最后一个激活层,并在预测的图像上对其进行线性外推。.
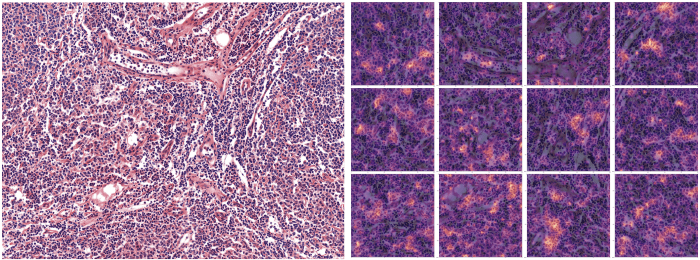
(上图:右侧图像突出显示了对预测滤泡性淋巴瘤类别贡献最大的图像部分--12 个补丁))。.
用热图来解释模型的输出对于调整建模方法非常有用,因为它为专家们提供了分析模型实际运行情况的方法。通过与专家的交流,我们(data 科学家)能够调整我们的方法,更好地处理 data 集,使模型更加稳健(即能够适应不同类型的输入)。此外,还能确保模型达到预期目的。事实上,我们就是这样认识到需要对图像染色进行归一化处理的。.
结论和主要经验教训
本研究的目标是探索创建一个良好的深度学习基础分类器的过程,以区分滤泡淋巴瘤和滤泡增生。我们的主要学习成果如下:

