

Autor


A modelagem de propensão pode ser usada para aumentar o impacto de sua comunicação com os clientes e otimizar os gastos com o orçamento de publicidade.
O data do Google Analytics é uma fonte data bem estruturada que pode ser facilmente transformada em um conjunto data pronto para aprendizado de máquina.
O backtest no histórico data e as métricas técnicas podem lhe dar uma primeira noção do desempenho do seu modelo, enquanto o teste ao vivo e as métricas comerciais lhe permitirão confirmar o impacto do seu modelo.
Nosso modelo personalizado de aprendizado de máquina superou as linhas de base existentes: durante os testes ao vivo em termos de ROAS (Return on advertising spend): +221% vs. modelo baseado em regras e +73% vs. aprendizado de máquina pronto para uso (índice de qualidade da sessão do Google Analytics).
Este artigo pressupõe fundamentos básicos de aprendizado de máquina e marketing.
O que é modelagem de propensão?
A modelagem de propensão é estimar a probabilidade de um cliente realizar uma determinada ação. Há várias ações que podem ser úteis para estimar:
Neste artigo, vamos nos concentrar em estimar a propensão de comprar um item em um site de comércio eletrônico.
Mas por que estimar a propensão a comprar? Porque isso permiteadaptar a forma como queremos interagir com um cliente. Por exemplo, suponha que tenhamos um modelo de propensão muito simples que classifica os clientes em “Frios”, “Mornos” e “Quentes” para um determinado produto (“Quentes” são os clientes com maior chance de compra e “Frios”, a menor):
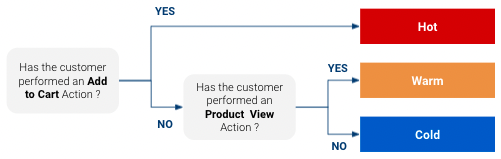
Bem, com base nessa classificaçãoo senhor pode ter uma resposta direcionada específica para cada classe. Talvez o senhor queira ter uma abordagem de marketing diferente com um cliente que está muito próximo de comprar do que com um que talvez nem tenha ouvido falar do seu produto. Além disso, se o senhor tiver um orçamento de mídia limitado, poderá concentrá-lo nos clientes que têm grande probabilidade de comprar e não gastar muito com aqueles que têm poucas chances.
Esse tipo simples de classificação baseada em regras pode dar bons resultados e, em geral, é melhor do que não ter nenhuma, mas tem várias limitações:
Para lidar com essas limitações, podemos usar uma abordagem mais voltada para o data: usar aprendizado de máquina em nosso data para prever uma probabilidade de compra para cada cliente.
Entendendo o Google Analytics data
O Google Analytics é um serviço analítico da web que rastreia o uso data e o tráfego em sites e aplicativos.
O Google Analytics data pode ser facilmente exportado para o Big Query (Google Cloud Platform totalmente gerenciado Serviço de armazém data), onde ele pode ser acessado por meio de uma sintaxe semelhante à do SQL:
Observe que a tabela de exportação do Big Query com o Google Analytics data é um tabela aninhada no nível da sessão:
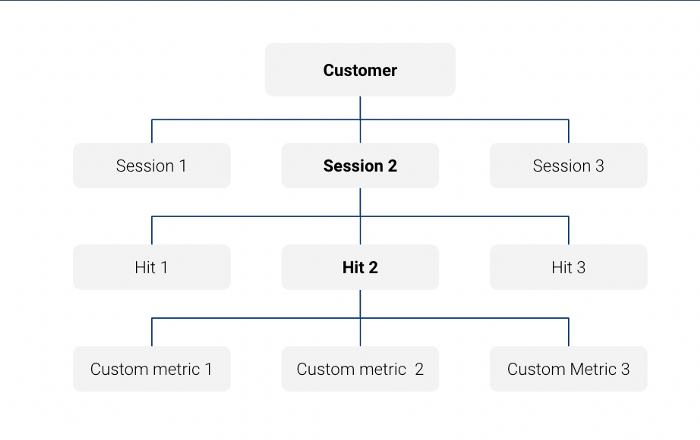
Por exemplo, nesta consulta, estamos analisando apenas recursos em nível de sessão:
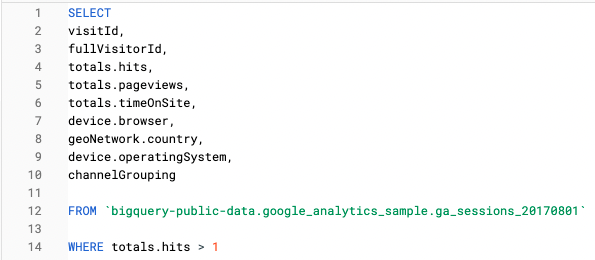
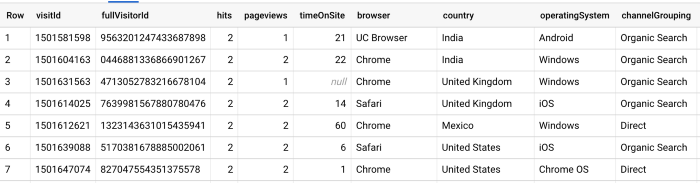
E, nessa consulta, usamos uma função Unnest para consultar as mesmas informações em nível de acerto:


Para obter mais informações sobre o GA data, consulte o documentação. Observe que nosso projeto foi desenvolvido no GA360, portanto, se o senhor estiver usando a versão mais recente, GA4, haverá algumas pequenas diferenças no modelo data, especialmente a tabela que estará no nível do evento. Há tabelas de amostra públicas do GA360 e GA4 data disponível no Big Query.
Agora que temos acesso à nossa fonte bruta data, precisamos realizar a engenharia de recursos antes de podermos alimentar nossa tabela com um algoritmo de aprendizado de máquina
Criando os recursos certos
O objetivo da etapa de engenharia de recursos é transformar o data bruto do Google Analytics (extraído do Big Query) em um mesa pronta a ser usado paraAprendizado de máquina.
O GA data é muito bem estruturado e exigirá o mínimo de etapas de limpeza data. No entanto, ainda há muitas informações presentes na tabela, muitas das quais não são úteis para o aprendizado de máquina ou não podem ser usadas como estão, portanto, é importante selecionar e criar os recursos certos. Para isso, criamos recursos que pareciam ser os mais correlacionados com a compra de um produto.
Criamos quatro tipos de recursos:
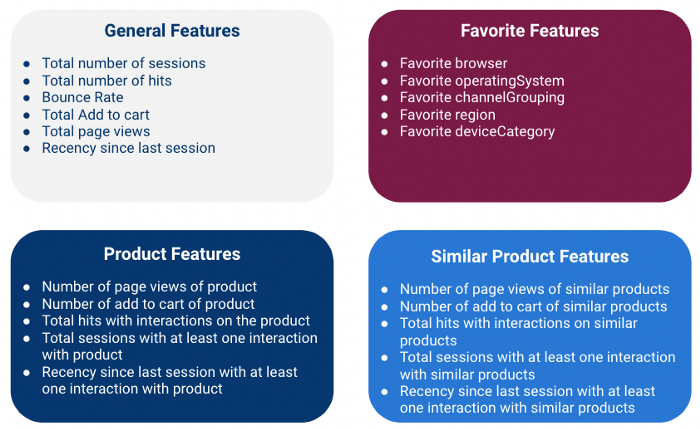
Observe que estamos computando todos esses recursos no nível do cliente, o que significa que estamos agregando informações de várias sessões para cada cliente (usando o campo fullVisitorId como chave)
Características gerais
Os recursos globais são características numéricas que fornecem informações gerais sobre a sessão.

Observe que a taxa de rejeição é definida como % de vezes que o cliente visitou apenas uma página da Web durante uma sessão.
Também foi importante incluir informações sobre o recência de eventosPor exemplo, um cliente que acabou de visitar seu site provavelmente está mais disposto a comprar do que um que o visitou há três meses. Para obter mais informações sobre esse tópico, o senhor pode consultar a teoria em RFM (valor monetário de recência, frequência).
Por isso, adicionamos um recurso Recência desde a última sessão = 1 / Número de dias desde a última sessão que permite que o valor seja normalizado entre 0 e 1
Recursos favoritos
Também queríamos incluir algumas informações sobre a chave categórica data disponíveis, tais como navegador ou dispositivo. Como essas informações estão no nível da sessão, pode haver vários valores diferentes para um único cliente, portanto, consideramos apenas aquele que ocorre mais por cliente (ou seja, o favorito). Além disso, para evitar ter recursos categóricos com cardinalidade muito alta, mantemos apenas os cinco valores mais comuns para cada recurso e substituímos todos os outros valores por um valor “Outro”

Características do produto
Embora os dois primeiros tipos de recursos sejam definitivamente úteis para nos ajudar a responder à pergunta “Um cliente vai comprar no meu site?”, eles não são suficientemente específicos se precisarmos saber “O cliente vai comprar um produto específico?”. Para ajudar a responder a essa pergunta, criamos recursos específicos do produto que incluem apenas o produto para o qual estamos tentando prever a compra:

Para Recência desde a última sessão com pelo menos uma interação com esse produto, usamos a mesma fórmula que para o Recência da sessão nos Recursos gerais. No entanto, podemos ter casos em que há 0 sessão com pelo menos uma interação com o produto e, nesse caso, preenchemos com 0. Isso faz sentido do ponto de vista comercial, pois o valor mais alto possível é 1 (quando o cliente teve uma sessão desde ontem).
Características de produtos similares
Além de observar a interação do cliente com o produto para o qual estamos tentando prever a probabilidade de compra, saber que o cliente interagiu com o outros produtos com função e faixa de preço semelhantes pode ser definitivamente útil (ou seja, produto substituto). Por esse motivo, adicionamos um conjunto de recursos de produtos similares que são idênticos aos recursos de produtos, exceto pelo fato de também incluirmos produtos similares no escopo da variável. Os produtos similares de um determinado produto foram definidos usando inputs comerciais.

Agora temos nosso dataset projetado com recursos no qual podemos treinar nosso modelo de aprendizado de máquina.
Treinamento do modelo
Como queremos saber se um cliente vai comprar um produto específico ou não, esse é um problema de classificação binária.
Em nossa primeira iteração, fizemos o seguinte para criar nosso dataset de aprendizado de máquina (que era uma linha por cliente):
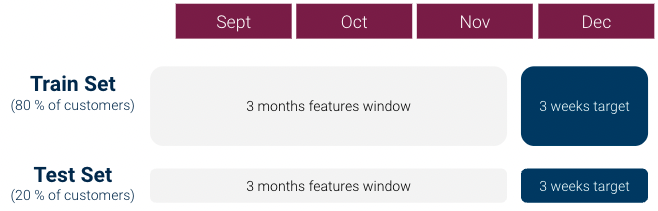
No entanto, uma primeira exploração do data mostrou rapidamente que havia um forte problema de desequilíbrio de classe: A relação Classe 1 / Classe 0 era superior a 1:1000 e não tínhamos clientes Classe 1 suficientes. Isso pode ser muito problemático para os modelos de aprendizado de máquina.
Para lidar com esses problemas, fizemos várias modificações em nossa abordagem:
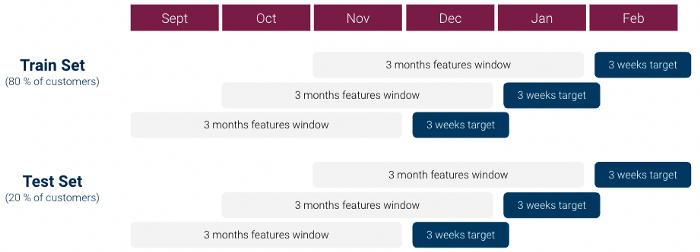
Usando esse dataset, testamos vários modelos de classificação: Modelo Linear, Random Forest e XGboost, ajustando os hiperparâmetros usando a busca em grade, e acabamos selecionando um Modelo XGboost.
Avaliação do nosso modelo
Ao avaliar um modelo de propensão, há dois tipos principais de avaliações que podem ser realizadas:
Avaliação de backtest
Primeiro, realizamos avaliação de backtest: aplicamos nosso modelo a histórico anterior data e verificamos se o nosso modelo está identificando corretamente os clientes que vão fazer uma adição ao carrinho. Como estamos usando um classificador binário, o modelo produz uma pontuação de probabilidade entre 0 e 1 de ser Classe 1 (Adicionar ao carrinho).
matriz de confusão e calcular o precisão/recuperação (ou sua forma combinada nopontuação f1). No entanto, há dois problemas com essas métricas simples:
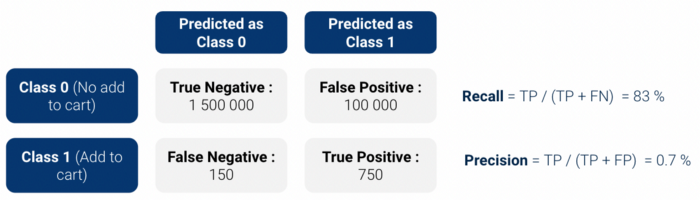
Por isso, decidimos usar duas métricas que eram mais interpretável:
Os resultados dessas métricas foram bastante positivos, principalmente, Elevação estava por perto 13.5.
A avaliação de backtest é um método livre de riscos para uma primeira avaliação de um modelo de propensão, mas tem várias limitações:
Avaliação de teste ao vivo
Portanto, para ter uma ideia melhor do valor comercial do nosso modelo, precisamos realizar avaliação de teste ao vivo. Aqui, ativamos nosso modelo e o usamos para priorizar os gastos com orçamento de publicidade:
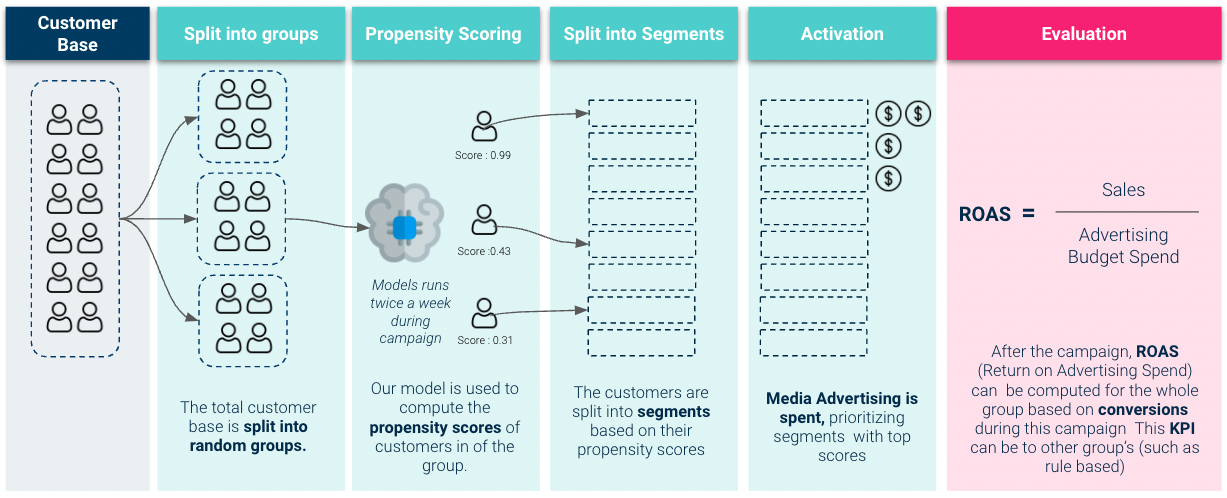
Os resultados que obtivemos no teste ao vivo foram muito sólidos:
Conclusão
Além de alcançar um desempenho sólido, um grande benefício colateral de nossa abordagem é que nossa engenharia de recursos é muito genérica. Quase Nenhuma das etapas de engenharia de recursos precisa ser adaptada para aplicar nosso modelo a um escopo de país ou escopo de produto diferente. De fato, após nosso primeiro sucesso no teste ao vivo, conseguimos implementar nosso modelo em vários países e produtos de maneira muito eficiente.
Obrigado ao senhor por ler. Ficaria feliz em ouvir os comentários do senhor sobre essa abordagem. O senhor já construiu modelos de propensão? Se sim, o que o senhor fez de diferente?
Agradecimentos a Bruce Delattre, Rafaëlle Aygalenq e Cédric Ly.
