

作者


倾向性建模可用于提高与客户沟通的效果,优化广告预算支出。.
Google Analytics data 是一个结构良好的 data 源,可以轻松转化为机器学习就绪的 data 集。.
对历史 data 和技术指标的回溯测试可以让您初步了解模型的性能,而实时测试和业务指标则可以让您确认模型的影响。.
我们的定制机器学习模型在 ROAS(广告支出回报率)方面的表现优于现有基准:在实时测试期间:与基于规则的模型相比,+221%;与现成的机器学习(Google Analytics 会话质量得分)相比,+73%。.
本文以机器学习和市场营销方面的基础知识为前提。.
什么是倾向模型?
倾向模型是 估计客户执行特定操作的可能性. .有几种方法可以用于估算:
在本文中,我们将重点估算在电子商务网站上购买商品的倾向。.
但为什么要估算购买倾向呢?因为它可以调整我们与客户互动的方式。. 举例来说,假设我们有一个非常简单的倾向模型,可以将某一产品的客户分为 “冷”、“暖 ”和 “热 ”三类(“热 ”指购买几率最高的客户,“冷 ”指购买几率最低的客户):
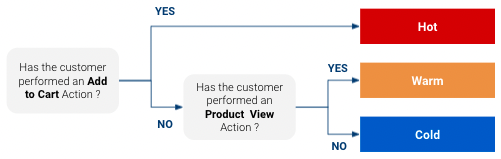
那么,根据这种分类您可以对每个班级做出有针对性的回应. .对于即将购买产品的客户,您可能需要采取不同的营销方式,而对于那些可能连听都没听说过您的产品的客户,您可能需要采取不同的营销方式。此外,如果您的媒体预算有限,您可以将预算重点放在购买可能性高的客户身上,而不要在那些不确定的客户身上花费太多。.
这种基于规则的简单分类方法可以产生很好的结果,通常比没有规则要好,但它有以下缺点 有几个局限性:
为了应对这些限制,我们可以使用更多的 data 驱动方法:使用 机器学习 在我们的 data 上 预测购买概率 为每个客户服务。.
了解谷歌分析 data
谷歌分析 分析网络服务 跟踪网站和应用程序的使用情况 data 和流量。.
谷歌分析 data 可以 可轻松导出至大查询 (谷歌云平台全面管理 data 仓库服务),可以通过类似 SQL 的语法进行访问:
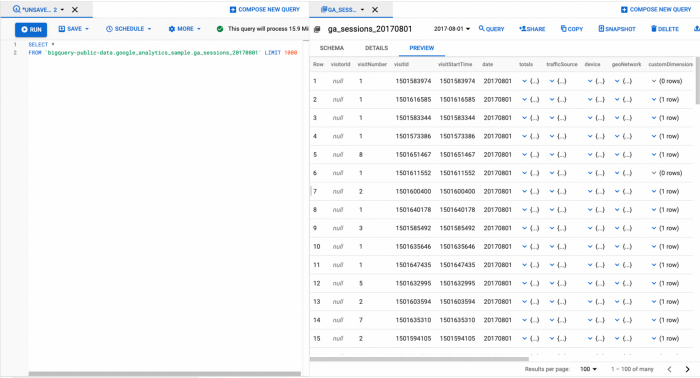
请注意,带有 Google Analytics data 的大查询导出表是一个 会话级别的嵌套表:
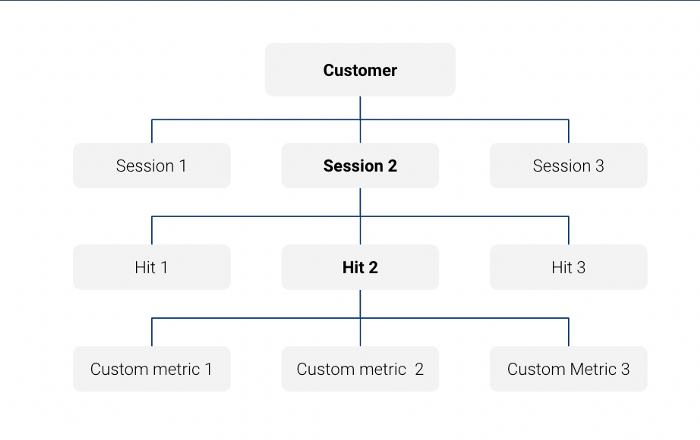
例如,在这个查询中,我们只查看 会话级功能:
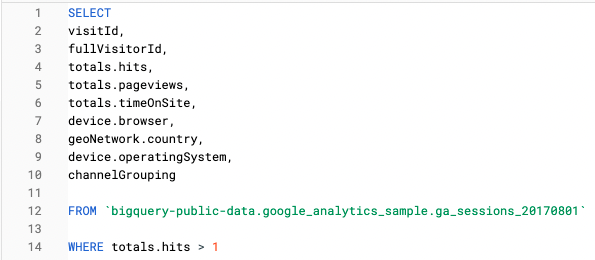
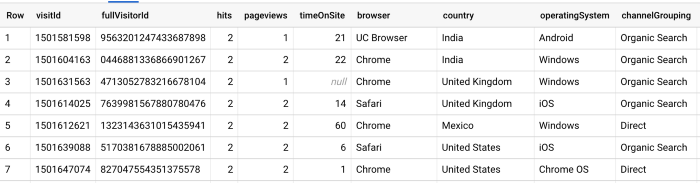
在这个查询中,我们使用了 Unnest 函数来查询相同的信息,即 命中率:


有关 GA data 的更多信息,请查阅 文献资料. .请注意,我们的项目是在 GA360 上开发的,因此如果您使用的是最新版本的 GA4,data 模型会有一些细微差别,特别是表格将是事件级的。以下是公开的示例表 GA360 和 GA4 data 可通过 Big Query 查询。.
现在,我们已经获得了原始的 data 数据源,在将我们的表格输入机器学习算法之前,我们需要执行特征工程
设计正确的功能
特征工程步骤的目的是将原始的 Google Analytics data(从大查询中提取)转换为 就绪 用于机器学习.
GA data 的结构非常合理,只需最少的 data 清理步骤。然而,表格中仍存在大量信息,其中许多信息对机器学习并无用处,或者无法按原样使用,因此选择和制作正确的特征非常重要。为此,我们构建了似乎与购买产品最相关的特征。.
我们精心设计了 4 类功能:
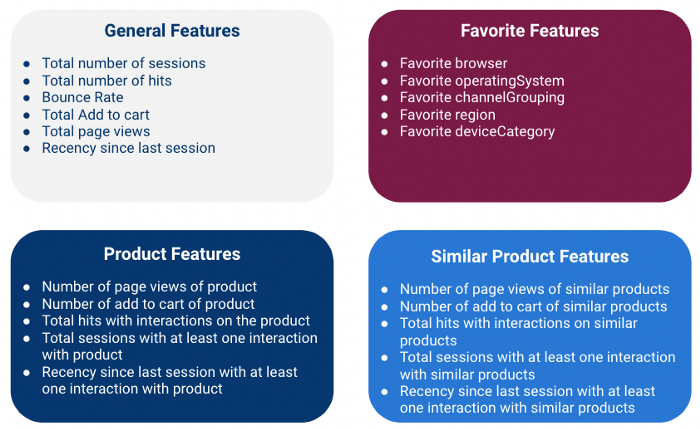
请注意,我们是在客户级别计算所有这些功能,这意味着我们要汇总每个客户的多个会话信息(使用 fullVisitorId 字段作为关键字)
一般功能
全球功能包括 数值特征 提供会议的一般信息。.

请注意,跳出率是指客户在会话期间只访问一个网页的 % 次。.
同样重要的是要包括以下方面的信息 事件发生的时间例如:刚刚访问过您网站的客户可能比 3 个月前访问过您网站的客户更有购买欲望。有关此主题的更多信息,您可以查看以下理论 RFM(频率、频率货币价值).
因此,我们增加了一项功能 自上次会议以来的重复性 = 1 / 自上次会议以来的天数 使数值在 0 和 1 之间正常化
最喜爱的功能
我们还希望提供以下信息 关键分类 data 如 浏览器或设备. .由于该信息是会话级别的,一个客户可能有多个不同的值,因此我们只取每个客户出现最多的一个值(即最喜欢的值)。此外,为了避免分类特征的卡方值过高,我们只保留每个特征中最常见的 5 个值,并用 “其他 ”值代替所有其他值。

产品特点
虽然前两类功能对于帮助我们回答 “客户是否会在我的网站上购买? “客户会购买特定产品吗?”. .为了帮助回答这个问题,我们建立了产品特定功能,这些功能只包括我们试图预测购买的产品:

对于 自上次与该产品至少有一次互动以来的时间间隔、, 我们使用与 会议间隔 在一般特征中。然而,我们可能会遇到这样的情况,即与产品至少有一次交互的会话为 0,在这种情况下,我们填写 0。从业务角度来看,这是有道理的,因为我们可能的最高值是 1(即客户从昨天开始有一次会话)。.
类似产品功能
除了研究客户与我们试图预测购买概率的产品之间的互动外,还需要了解客户与以下产品的互动情况 其他功能和价格类似的产品 绝对有用 (即替代产品)。因此,我们增加了一组类似产品特征,这些特征与产品特征完全相同,只是在变量范围中也包含了类似产品。特定产品的类似产品是通过业务输入定义的。.

我们现在有了我们的 dataset 在此基础上,我们可以训练机器学习模型。.
训练模型
因为我们想知道客户是否会购买特定产品,所以这是一个 二元分类问题。.
在第一次迭代中,我们按照以下步骤创建了机器学习 dataset(每个客户 1 行):
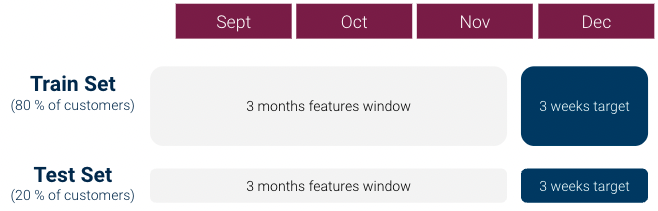
不过,对 data 的初步探索很快就表明,有一个 强烈的阶层失衡问题:1 类与 0 类的比例超过 1:1000,我们没有足够的 1 类客户。这对机器学习模型来说是个大问题。.
为了解决这些问题,我们对我们的方法做了一些修改:
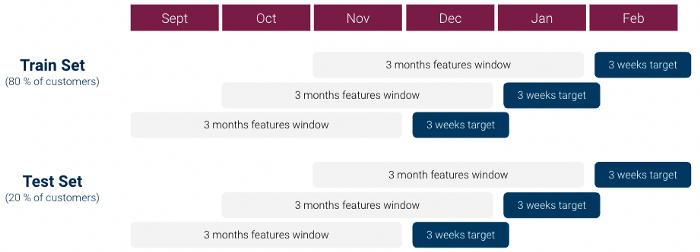
我们使用 dataset 测试了多个分类模型:线性模型、随机森林和 XGboost,使用网格搜索对超参数进行微调,最终选择了一个 XGboost 型号.
评估我们的模型
在评估倾向模型时,主要可以进行两种评估:
回溯测试评估
首先,我们进行了 反向测试评估: 我们将模型应用于 过去的历史 data 并检查我们的模型是否能正确识别将执行添加到购物车的客户。由于我们使用的是二元分类器,因此该模型产生的是类别 1(添加到购物车)的概率分数,介于 0 和 1 之间。.
混淆矩阵 并计算 精确度/召回率 (或它们在f1得分).然而,这些简单的衡量标准存在两个问题:
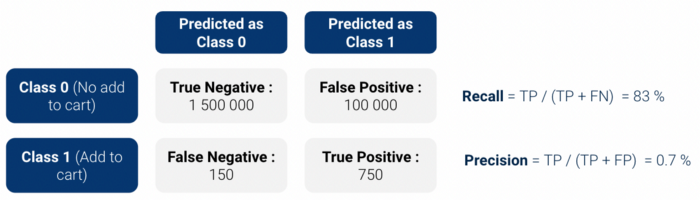
因此,我们决定使用两个更加 可解释:
尤其是在这些指标上取得了相当积极的成果、, 提升 当时 13.5.
回溯测试评估是对倾向模型进行首次评估的一种无风险方法,但也有一些局限性:
实时测试评估
因此,为了更好地了解我们模型的商业价值,我们需要执行以下操作 现场测试评估。在这里,我们启动了我们的模型,并用它来确定广告预算支出的优先次序:
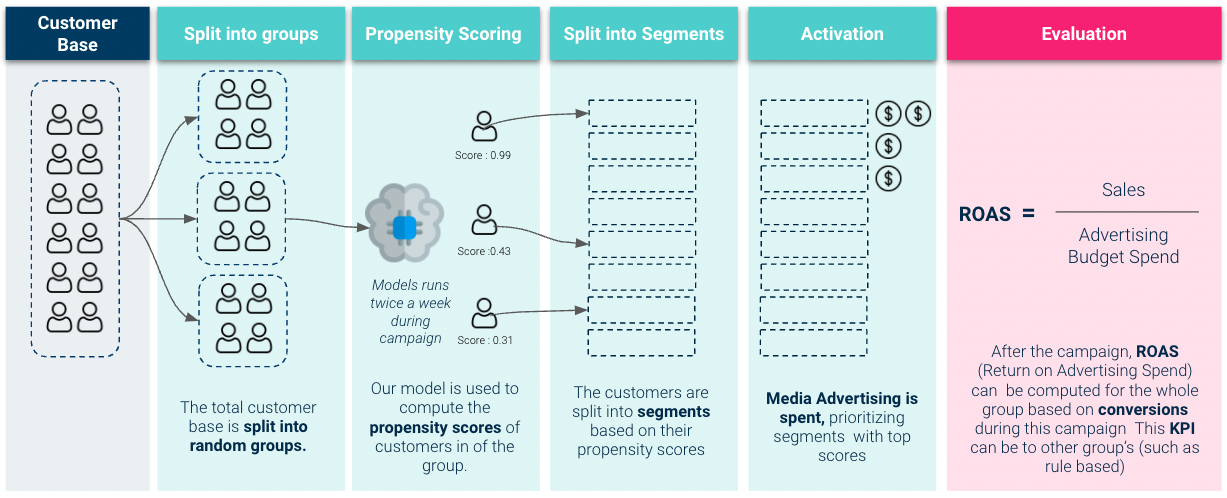
我们在实时测试中获得的结果非常可靠:
结论
除了性能稳定外,我们的方法还有一个很大的好处,那就是我们的功能工程非常通用。几乎 无需调整任何特征工程步骤 将我们的模型应用于 不同的国家范围或产品范围. .事实上,在首次成功进行现场测试后,我们能够 以非常高效的方式将我们的模式推广到多个国家和产品。.
感谢您的阅读。我很高兴听到您对这种方法的评论。您建立过倾向模型吗?如果有,您的做法有什么不同?
感谢 Bruce Delattre、Rafaëlle Aygalenq 和 Cédric Ly。.

