

Autor


El modelado de la propensión puede utilizarse para aumentar el impacto de su comunicación con los clientes y optimizar el gasto de su presupuesto publicitario.
Google Analytics data es una fuente data bien estructurada que puede transformarse fácilmente en un conjunto data preparado para el aprendizaje automático.
Las pruebas retrospectivas sobre el histórico data y las métricas técnicas pueden darle una primera idea del rendimiento de su modelo, mientras que las pruebas en vivo y las métricas comerciales le permitirán confirmar el impacto de su modelo.
Nuestro modelo de aprendizaje automático personalizado superó las líneas de base existentes: durante las pruebas en vivo en términos de ROAS (Retorno de la inversión publicitaria): +221% frente al modelo basado en reglas y +73% frente al aprendizaje automático estándar (puntuación de calidad de la sesión de Google Analytics).
Este artículo asume fundamentos básicos en aprendizaje automático y marketing.
¿Qué es el modelo de propensión?
El modelo de propensión es estimar la probabilidad de que un cliente realice una acción determinada. Hay varias acciones que pueden ser útiles para estimar:
En este artículo nos centraremos en la estimación de la propensión a comprar un artículo en un sitio web de comercio electrónico.
Pero, ¿por qué estimar la propensión a la compra? Porque permiteadaptar cómo queremos interactuar con un cliente. Por ejemplo, supongamos que tenemos un modelo de propensión muy sencillo que clasifica a los clientes en “Fríos”, “Templados” y “Calientes” para un producto determinado (“Calientes” son los clientes con mayor probabilidad de compra y “Fríos” los que menos):
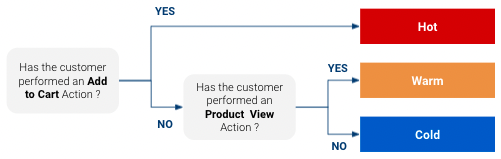
Bien, basándonos en esta clasificaciónpuede tener una respuesta específica para cada clase. Es posible que desee tener un enfoque de marketing diferente con un cliente que está muy cerca de comprar que con uno que puede que ni siquiera haya oído hablar de su producto. Además, si dispone de un presupuesto limitado para medios de comunicación, puede centrarlo en los clientes que tienen muchas probabilidades de comprar y no gastar demasiado en los que son poco probables.
Este tipo simple de clasificación basada en reglas puede dar buenos resultados y suele ser mejor que no tener ninguna, pero tiene varias limitaciones:
Para hacer frente a esas limitaciones podemos utilizar un enfoque más orientado al data: utilizar aprendizaje automático en nuestro data a predecir una probabilidad de compra para cada cliente.
Comprender Google Analytics data
Google Analytics es un servicio web de análisis que rastrea el uso data y el tráfico en el sitio web y las aplicaciones.
Google Analytics data puede ser fácilmente exportable a Big Query (Google Cloud Platform totalmente gestionado data servicio de almacén) donde se puede acceder mediante una sintaxis similar a la de SQL:
Tenga en cuenta que la tabla de exportación Big Query con Google Analytics data es un tabla anidada a nivel de sesión:
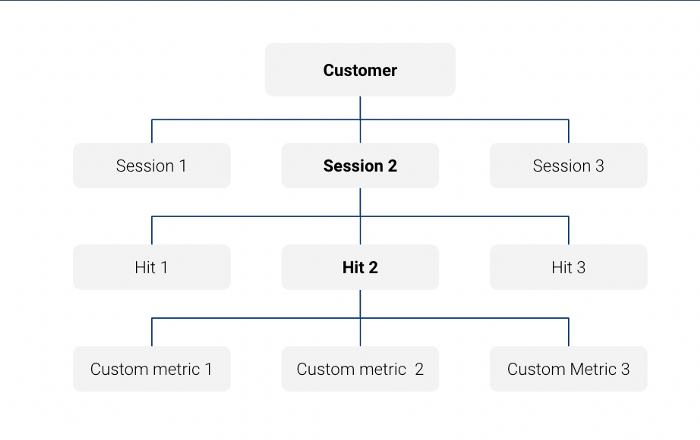
Por ejemplo, en esta consulta sólo buscamos características a nivel de sesión:
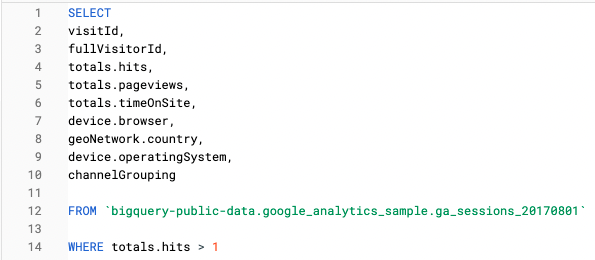
Y en esta consulta hemos utilizado una función Unnest para consultar la misma información en nivel de acierto:


Para más información sobre el GA data consulte el documentación. Tenga en cuenta que nuestro proyecto se desarrolló en GA360, por lo que si está utilizando la última versión, GA4, habrá algunas ligeras diferencias en el modelo data, especialmente en la tabla a nivel de evento. Existen tablas de muestra públicas de GA360 y GA4 data disponible en Big Query.
Ahora que tenemos acceso a nuestra fuente bruta data necesitamos realizar ingeniería de características antes de poder alimentar nuestra tabla a un algoritmo de aprendizaje automático
Elaborar las características adecuadas
El objetivo del paso de ingeniería de características es transformar el data bruto de Google Analytics (extraído de Big Query) en un mesa lista que se utilizará paraAprendizaje automático.
El GA data está muy bien estructurado y requerirá unos pasos de limpieza mínimos. Sin embargo, todavía hay mucha información presente en la tabla, mucha de la cual no es útil para el aprendizaje automático o no puede utilizarse tal cual, por lo que es importante seleccionar y elaborar las características adecuadas. Para ello construimos características que parecían ser las más correlacionadas con la compra de un producto.
Elaboramos 4 tipos de características:
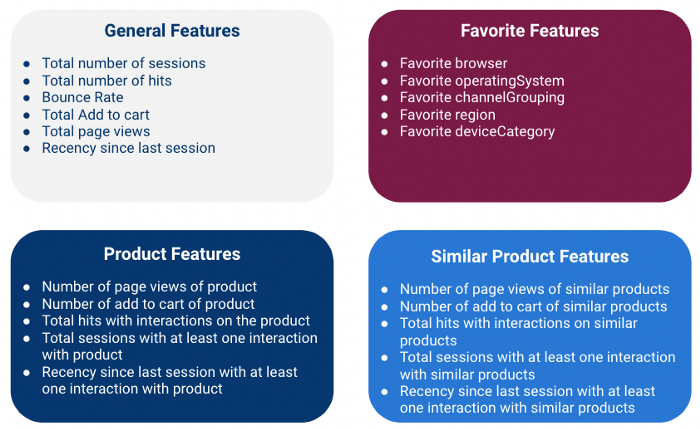
Tenga en cuenta que estamos calculando todas esas características a nivel de cliente, lo que significa que estamos agregando información de varias sesiones para cada cliente (utilizando el campo fullVisitorId como clave).
Características generales
Las características globales son características numéricas que ofrecen información general sobre la sesión.

Tenga en cuenta que la tasa de rebote se define como el % de veces que el cliente sólo visitó una página web durante una sesión.
También era importante incluir información sobre la recencia de los acontecimientos: por ejemplo, un cliente que acaba de visitar su sitio web probablemente tenga más ganas de comprar que uno que lo visitó hace 3 meses. Para más información sobre este tema puede consultar la teoría en RFM (recencia, frecuencia valor monetario).
Así que hemos añadido una función Recencia desde la última sesión = 1 / Número de días transcurridos desde la última sesión que permite normalizar el valor entre 0 y 1
Características favoritas
También queríamos incluir información sobre la clave categórica data disponibles como navegador o dispositivo. Dado que esa información se encuentra a nivel de sesión, puede haber varios valores diferentes para un mismo cliente, por lo que sólo tomamos el que más se da por cliente (es decir, el favorito). Además, para evitar tener características categóricas con una cardinalidad demasiado alta, sólo conservamos los 5 valores más comunes para cada característica y sustituimos todos los demás valores por un valor “Otro”.

Características del producto
Aunque los dos primeros tipos de características son definitivamente útiles para ayudarnos a responder a la pregunta “¿Va a comprar un cliente en mi sitio web?”, no son lo suficientemente específicas si necesitamos saber “¿El cliente va a comprar un producto concreto?”. Para ayudar a responder a esta pregunta construimos características específicas de producto que sólo incluyen el producto para el que intentamos predecir la compra:

Para Recuencia desde la última sesión con al menos una interacción con este producto, utilizamos la misma fórmula que para el Recencia de la sesión en las Características Generales. Sin embargo, podemos tener casos en los que haya 0 sesiones con al menos una interacción con el producto, en cuyo caso rellenamos con 0. Esto tiene sentido desde una perspectiva empresarial, ya que es nuestro valor más alto posible es 1 (cuando el cliente tuvo una sesión desde ayer).
Características de productos similares
Además de fijarnos en la interacción del cliente con el producto para el que intentamos predecir la probabilidad de compra, saber que el cliente interactuó con otros productos con funciones y precios similares sin duda puede ser útil (es decir, producto sustituto). Por este motivo, añadimos un conjunto de características de Producto similar que son idénticas a las características de Producto, salvo que también incluimos los productos similares en el ámbito variable. Los productos similares para un producto determinado se definieron utilizando entradas empresariales.

Ya tenemos nuestro característica ingeniería dataset sobre el que podemos entrenar nuestro modelo de aprendizaje automático.
Entrenamiento del modelo
Puesto que queremos saber si un cliente va a comprar o no un producto específico, se trata de un problema de clasificación binaria.
Para nuestra primera iteración, hicimos lo siguiente para crear nuestro conjunto dataset de aprendizaje automático (que era de 1 fila por cliente):
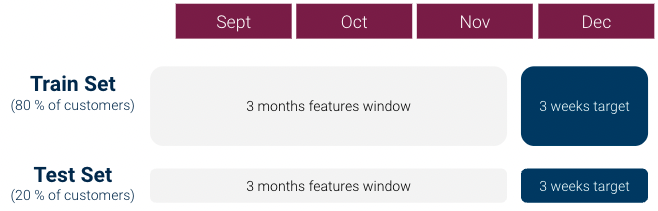
Sin embargo una primera exploración data mostró rápidamente que había una fuerte problema de desequilibrio de clases: La relación Clase 1 / Clase 0 era superior a 1:1000 y no teníamos suficientes clientes de Clase 1. Esto puede ser muy problemático para los modelos de aprendizaje automático.
Para hacer frente a estos problemas realizamos varias modificaciones en nuestro enfoque:
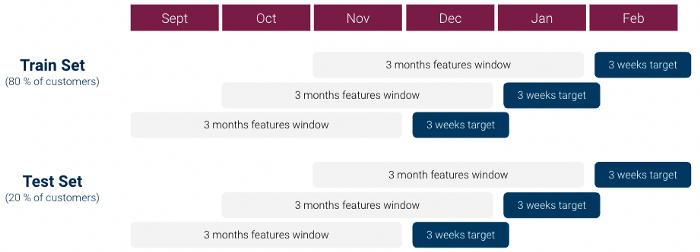
Utilizando este dataset probamos con varios modelos de clasificación: Modelo lineal, Random Forest y XGboost, afinando los hiperparámetros mediante la búsqueda en cuadrícula, y acabamos seleccionando un Modelo XGboost.
Evaluación de nuestro modelo
Al evaluar un modelo de propensión se pueden realizar dos tipos principales de evaluaciones:
Evaluación Backtest
Primero realizamos evaluación backtest: aplicamos nuestro modelo a pasado histórico data y comprobamos que nuestro modelo identifica correctamente a los clientes que van a realizar un añadir al carro. Dado que estamos utilizando un clasificador binario, el modelo produce una puntuación de probabilidad entre 0 y 1 de ser la clase 1 (Añadir al carro).
matriz de confusión y calcular el precisión / recall (o su forma combinada en elf1 puntuación). Sin embargo, hay dos problemas con estas métricas simples:
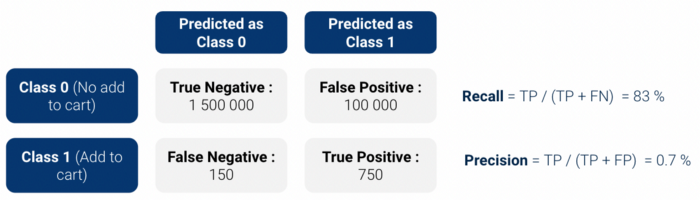
Así que decidimos utilizar dos métricas más interpretable:
Los resultados en esas métricas fueron bastante positivos, sobre todo, Elevar estaba alrededor de 13.5.
La evaluación backtest es un método sin riesgo para una primera evaluación de un modelo de propensión, pero tiene varias limitaciones:
Evaluación en vivo
Así que para hacernos una mejor idea del valor comercial de nuestro modelo necesitamos realizar evaluación de la prueba en vivo. Aquí activamos nuestro modelo y lo utilizamos para priorizar los gastos del presupuesto publicitario :
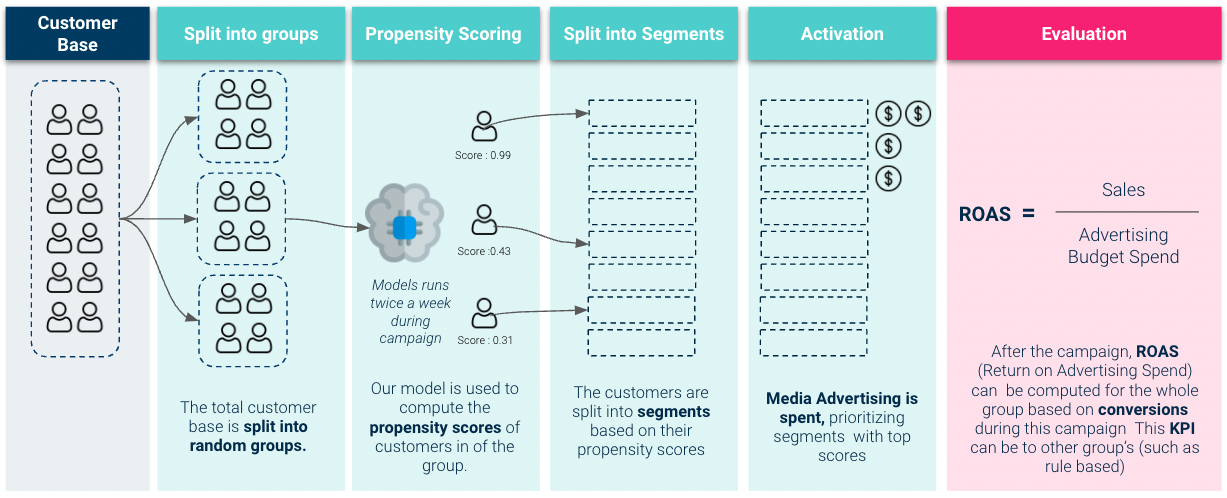
Los resultados que obtuvimos en la prueba en vivo fueron muy sólidos:
Conclusión
Además de alcanzar un sólido rendimiento, un gran beneficio secundario de nuestro enfoque es que nuestra ingeniería de funciones es muy genérica. Casi no es necesario adaptar ninguno de los pasos de ingeniería de características aplicar nuestro modelo a un diferente ámbito de países o productos. De hecho, tras nuestro primer éxito en la prueba en vivo, pudimos extender nuestro modelo a múltiples países y productos de una manera muy eficaz.
Gracias por su lectura. Me encantaría conocer sus comentarios sobre este enfoque. ¿Ha construido alguna vez modelos de propensión? Si es así, ¿qué hizo de forma diferente?
Gracias a Bruce Delattre, Rafaëlle Aygalenq y Cédric Ly.
