

Autor


Mit Hilfe der Propensity-Modellierung können Sie die Wirkung Ihrer Kundenkommunikation erhöhen und die Ausgaben für Ihr Werbebudget optimieren.
Google Analytics data ist eine gut strukturierte data-Quelle, die leicht in ein für maschinelles Lernen geeignetes data-Set umgewandelt werden kann.
Backtests mit historischen data- und technischen Metriken können Ihnen einen ersten Eindruck von der Leistung Ihres Modells vermitteln, während Live-Tests und Geschäftsmetriken es Ihnen ermöglichen, die Auswirkungen Ihres Modells zu bestätigen.
Unser benutzerdefiniertes Modell für maschinelles Lernen übertraf die bestehenden Basiswerte: bei Live-Tests in Bezug auf den ROAS (Return on advertising spend): +221% gegenüber dem regelbasierten Modell und +73% gegenüber dem maschinellen Lernen von der Stange (Google Analytics Session Quality Score).
Dieser Artikel geht von grundlegenden Kenntnissen über maschinelles Lernen und Marketing aus.
Was ist Propensity Modeling?
Die Propensity-Modellierung ist Einschätzung der Wahrscheinlichkeit, mit der ein Kunde eine bestimmte Aktion durchführen wird. Es gibt mehrere Aktionen, die bei der Einschätzung nützlich sein können:
In diesem Artikel konzentrieren wir uns auf die Schätzung der Neigung, einen Artikel auf einer E-Commerce-Website zu kaufen.
Aber warum sollte man die Anschaffungsneigung schätzen? Weil sie es erlaubtanpassen, wie wir mit einem Kunden interagieren möchten. Nehmen wir zum Beispiel an, wir haben ein sehr einfaches Neigungsmodell, das die Kunden für ein bestimmtes Produkt in “kalt”, “warm” und “heiß” einteilt (“heiß” sind Kunden mit der höchsten Kaufwahrscheinlichkeit und “kalt” die geringste):
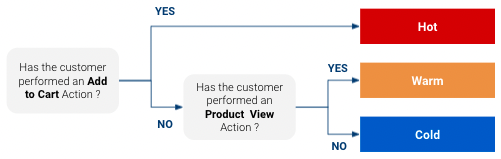
Nun, basierend auf dieser KlassifizierungSie können eine gezielte Antwort für jede Klasse haben. Bei einem Kunden, der kurz vor dem Kauf steht, sollten Sie einen anderen Marketingansatz verfolgen als bei einem Kunden, der vielleicht noch nicht einmal von Ihrem Produkt gehört hat. Auch wenn Sie nur ein begrenztes Medienbudget haben, können Sie es auf Kunden konzentrieren, die mit hoher Wahrscheinlichkeit kaufen werden, und nicht zu viel für diejenigen ausgeben, die noch nicht so weit sind.
Diese einfache Art der regelbasierten Klassifizierung kann gute Ergebnisse liefern und ist in der Regel besser als gar keine, aber sie hat mehrere Einschränkungen:
Um diese Einschränkungen zu umgehen, können wir einen eher data-gesteuerten Ansatz verwenden: Verwenden Sie maschinelles Lernen auf unserer data zu eine Kaufwahrscheinlichkeit vorhersagen für jeden Kunden.
Google Analytics verstehen data
Google Analytics ist ein Analytik-Webdienst das die Nutzung von data und den Verkehr auf Websites und Anwendungen verfolgt.
Google Analytics data kann sein leicht in Big Query exportiert werden (Google Cloud Platform vollständig verwaltet data Lagerdienst), wo Sie über eine SQL-ähnliche Syntax auf sie zugreifen können:
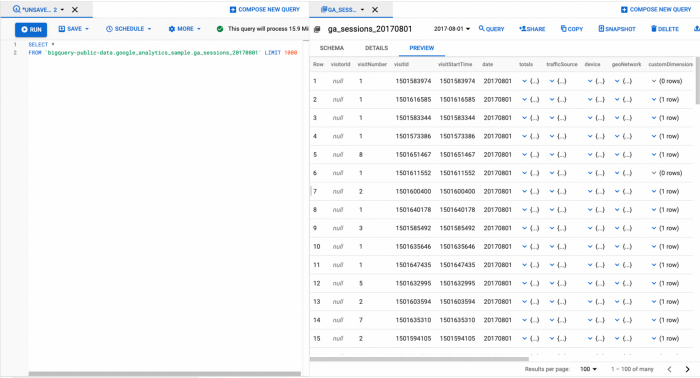
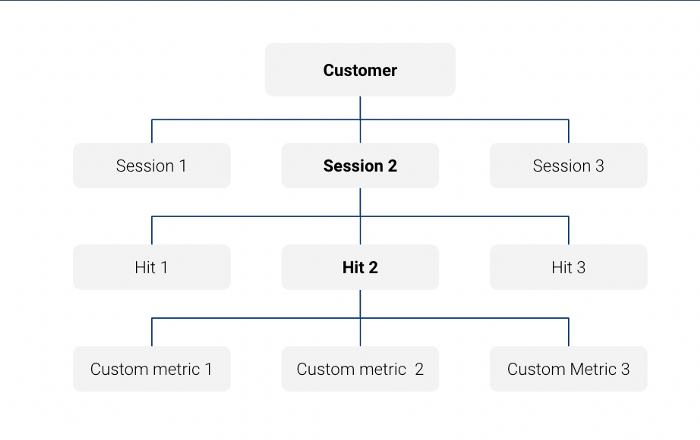
Beachten Sie, dass die Big Query Exporttabelle mit Google Analytics data eine verschachtelte Tabelle auf Sitzungsebene:
In dieser Abfrage suchen wir zum Beispiel nur nach Funktionen auf Sitzungsebene:
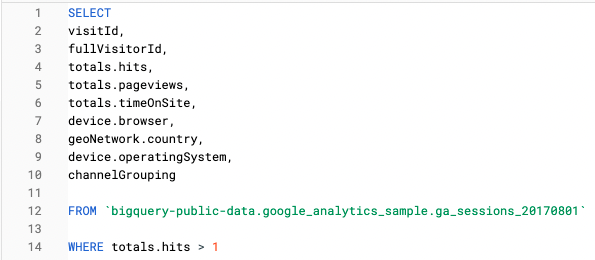
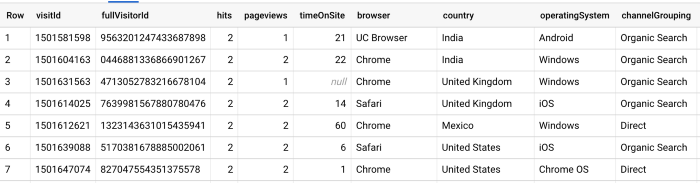
Und in dieser Abfrage haben wir eine Unnest-Funktion verwendet, um die gleichen Informationen unter Trefferquote:


Weitere Informationen über GA data finden Sie auf der Dokumentation. Beachten Sie, dass unser Projekt auf GA360 entwickelt wurde. Wenn Sie also die neueste Version, GA4, verwenden, wird es einige leichte Unterschiede im data-Modell geben, insbesondere wird die Tabelle auf Ereignisebene sein. Es gibt öffentliche Beispieltabellen von GA360 und GA4 data verfügbar auf Big Query.
Da wir nun Zugriff auf unsere data-Rohdaten haben, müssen wir ein Feature-Engineering durchführen, bevor wir unsere Tabelle in einen Algorithmus für maschinelles Lernen einspeisen können
Die richtigen Funktionen entwickeln
Das Ziel des Feature-Engineering-Schrittes ist die Umwandlung der rohen Google Analytics data (extrahiert aus Big Query) in eine Tisch bereit zu verwenden fürMaschinelles Lernen.
GA data ist sehr gut strukturiert und erfordert nur minimale data Bereinigungsschritte. Allerdings enthält die Tabelle immer noch viele Informationen, von denen viele für das maschinelle Lernen nicht nützlich sind oder nicht verwendet werden können, so dass es wichtig ist, die richtigen Merkmale auszuwählen und zu erstellen. Zu diesem Zweck haben wir Merkmale erstellt, die am stärksten mit dem Kauf eines Produkts korreliert sind.
Wir haben 4 Arten von Funktionen entwickelt:
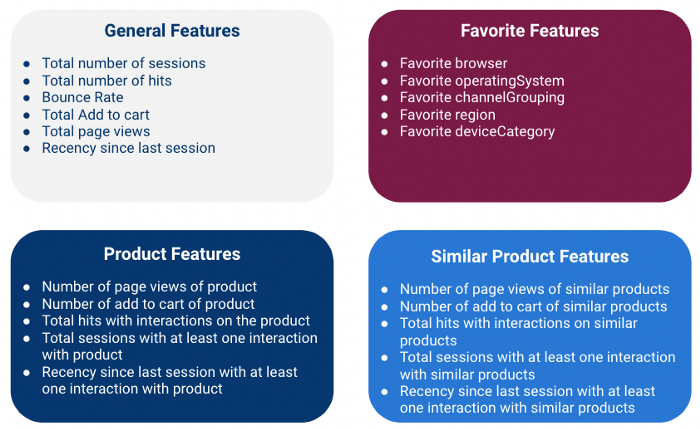
Beachten Sie, dass wir all diese Merkmale auf Kundenebene berechnen, was bedeutet, dass wir Informationen aus mehreren Sitzungen für jeden Kunden aggregieren (unter Verwendung des Feldes fullVisitorId als Schlüssel)
Allgemeine Merkmale
Globale Merkmale sind Numerische Merkmale die allgemeine Informationen über die Sitzung enthalten.

Beachten Sie, dass die Absprungrate definiert ist als % der Male, die ein Kunde während einer Sitzung nur eine Webseite besucht hat.
Es war auch wichtig, Informationen über die Aktualität der Ereignisse: Ein Kunde, der Ihre Website gerade erst besucht hat, ist wahrscheinlich kauffreudiger als ein Kunde, der sie vor 3 Monaten besucht hat. Weitere Informationen zu diesem Thema finden Sie in der Theorie auf RFM (Häufigkeit, Häufigkeit, monetärer Wert).
Also haben wir eine Funktion hinzugefügt Aktualität seit der letzten Sitzung = 1 / Anzahl der Tage seit der letzten Sitzung mit dem der Wert zwischen 0 und 1 normalisiert werden kann
Bevorzugte Eigenschaften
Wir wollten auch einige Informationen über die wichtige kategorische data verfügbar, wie zum Beispiel Browser oder Gerät. Da diese Informationen auf Sitzungsebene vorliegen, kann es für einen einzelnen Kunden mehrere verschiedene Werte geben, so dass wir nur den Wert nehmen, der pro Kunde am häufigsten vorkommt (d.h. den Favoriten). Um zu vermeiden, dass wir kategorische Merkmale mit einer zu hohen Kardinalität haben, behalten wir außerdem nur die 5 häufigsten Werte für jedes Merkmal bei und ersetzen alle anderen Werte durch den Wert “Andere”.

Produktmerkmale
Während die ersten beiden Arten von Merkmalen definitiv nützlich sind, um die Frage “Wird ein Kunde auf meiner Website kaufen?” zu beantworten, sind sie nicht spezifisch genug, wenn wir wissen müssen “Möchte der Kunde ein bestimmtes Produkt kaufen?”. Um diese Frage zu beantworten, haben wir produktspezifische Funktionen entwickelt, die nur das Produkt umfassen, für das wir den Kauf vorhersagen möchten:

Für Häufigkeit seit der letzten Sitzung mit mindestens einer Interaktion mit diesem Produkt, verwenden wir die gleiche Formel wie für die Sitzungshäufigkeit in den Allgemeinen Eigenschaften. Es kann jedoch Fälle geben, in denen es 0 Sitzungen mit mindestens einer Interaktion mit dem Produkt gibt. In diesem Fall geben wir 0 ein. Dies ist aus geschäftlicher Sicht sinnvoll, da unser höchstmöglicher Wert 1 ist (wenn der Kunde seit gestern eine Sitzung hatte).
Ähnliche Produkteigenschaften
Zusätzlich zur Betrachtung der Interaktion des Kunden mit dem Produkt, für das wir versuchen, die Kaufwahrscheinlichkeit vorherzusagen, ist das Wissen, dass der Kunde mit andere Produkte mit ähnlicher Funktion und Preisklasse kann definitiv nützlich sein (d.h. Ersatzprodukt). Aus diesem Grund haben wir eine Reihe von ähnlichen Produktmerkmalen hinzugefügt, die mit den Produktmerkmalen identisch sind, mit der Ausnahme, dass wir auch ähnliche Produkte in den variablen Umfang aufnehmen. Die ähnlichen Produkte für ein bestimmtes Produkt wurden mit Hilfe von Business-Inputs definiert.

Wir haben jetzt unser Merkmal entwickelt dataset mit denen wir unser maschinelles Lernmodell trainieren können.
Das Modell trainieren
Da wir wissen wollen, ob ein Kunde ein bestimmtes Produkt kaufen wird oder nicht, ist dies ein binäres Klassifizierungsproblem.
Für unsere erste Iteration haben wir unser dataset für maschinelles Lernen (1 Zeile pro Kunde) wie folgt erstellt:
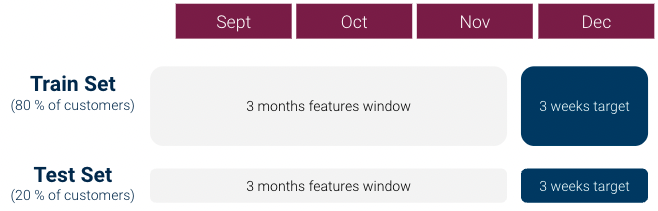
Eine erste Erkundung der data zeigte jedoch schnell, dass es eine starkes Ungleichgewicht zwischen den Klassen: Das Verhältnis Klasse 1 / Klasse 0 lag bei über 1:1000 und wir hatten nicht genügend Kunden der Klasse 1. Das kann für maschinelle Lernmodelle sehr problematisch sein.
Um mit diesen Problemen fertig zu werden, haben wir einige Änderungen an unserem Ansatz vorgenommen:
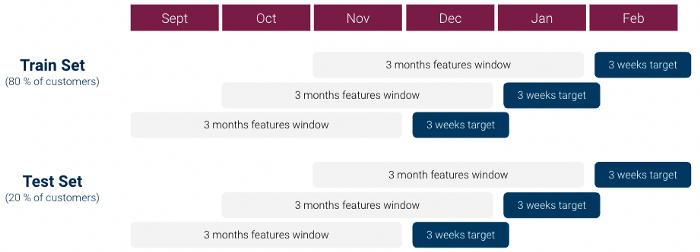
Mit diesem dataset haben wir verschiedene Klassifizierungsmodelle getestet: Lineares Modell, Random Forest und XGboost, wobei wir die Hyperparameter mit Hilfe der Gittersuche feinabgestimmt haben, und schließlich ein XGboost Modell.
Unser Modell auswerten
Bei der Auswertung eines Propensity-Modells gibt es zwei Haupttypen von Auswertungen, die durchgeführt werden können:
Backtest-Auswertung
Zuerst haben wir Backtest-Auswertung: haben wir unser Modell auf Vergangenheit historisch data und überprüft, ob unser Modell die Kunden, die in den Warenkorb gelegt werden, korrekt identifiziert. Da wir einen binären Klassifikator verwenden, erzeugt das Modell einen Wahrscheinlichkeitswert zwischen 0 und 1 für die Klasse 1 (In den Warenkorb).
Verwirrungsmatrix und berechnen Sie die Genauigkeit / Rückruf (oder ihre kombinierte Form in derf1 Ergebnis). Allerdings gibt es zwei Probleme mit diesen einfachen Metriken:
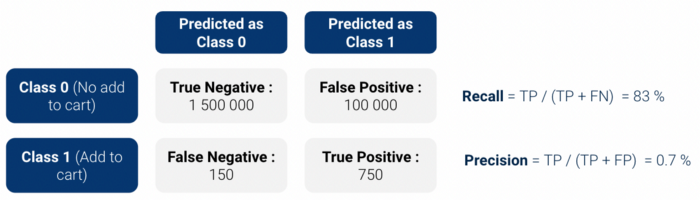
Deshalb haben wir beschlossen, zwei Metriken zu verwenden, die besser geeignet sind interpretierbar:
Die Ergebnisse waren vor allem bei diesen Kennzahlen recht positiv, Uplift war ungefähr 13.5.
Die Backtest-Evaluierung ist eine risikofreie Methode für eine erste Bewertung eines Propensity-Modells, hat jedoch einige Einschränkungen:
Livetest Auswertung
Um also eine bessere Vorstellung vom Geschäftswert unseres Modells zu bekommen, müssen wir Folgendes tun Live-Test-Auswertung. Hier aktivieren wir unser Modell und verwenden es, um die Ausgaben für Werbebudgets zu priorisieren:
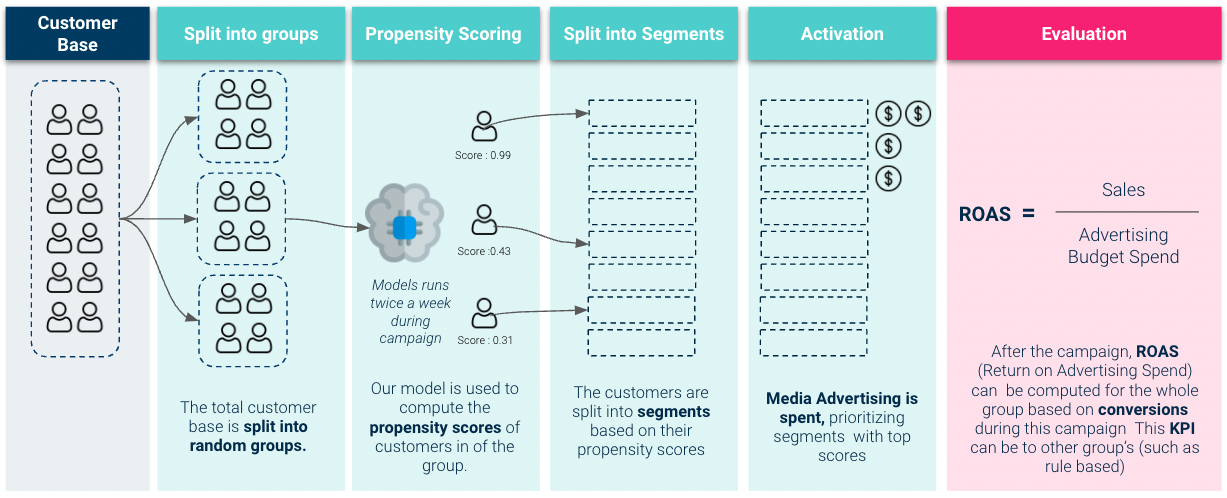
Die Ergebnisse, die wir im Livetest erzielt haben, waren sehr solide:
Fazit
Neben der soliden Leistung ist ein starker Nebeneffekt unseres Ansatzes, dass unser Feature Engineering sehr generisch ist. Fast Keiner der Schritte der Feature-Entwicklung muss angepasst werden um unser Modell auf ein Unterschiedlicher Geltungsbereich für Länder oder Produkte. Nach unserem ersten Erfolg im Livetest konnten wir sogar unser Modell auf mehrere Länder und Produkte auf sehr effiziente Weise ausweiten.
Vielen Dank für Ihre Lektüre. Ich würde mich freuen, Ihre Kommentare zu diesem Ansatz zu hören. Haben Sie jemals Propensity-Modelle erstellt? Wenn ja, was haben Sie anders gemacht?
Dank an Bruce Delattre, Rafaëlle Aygalenq und Cédric Ly.
