

Auteur


Propensity modeling kan worden gebruikt om de impact van uw communicatie met klanten te vergroten en de uitgaven van uw reclamebudget te optimaliseren.
Google Analytics data is een goed gestructureerde data bron die gemakkelijk kan worden omgezet in een machine learning-ready dataset.
Backtests op historische data en technische statistieken kunnen u een eerste indruk geven van de prestaties van uw model, terwijl u met live tests en zakelijke statistieken de impact van uw model kunt bevestigen.
Ons aangepaste machine learning-model presteerde beter dan bestaande baselines: tijdens live tests in termen van ROAS (Return on advertising spend): +221% vs op regels gebaseerd model en +73% vs off-the-shelf machine learning (Google Analytics sessie kwaliteitsscore).
Dit artikel gaat uit van basisprincipes in machine learning en marketing.
Wat is propensity modeling?
Proportionaliteitsmodellering is inschatten hoe waarschijnlijk het is dat een klant een bepaalde actie zal uitvoeren. Er zijn verschillende acties die nuttig kunnen zijn om in te schatten:
In dit artikel richten we ons op het schatten van de geneigdheid om een artikel op een e-commercewebsite te kopen.
Maar waarom koopbereidheid schatten? Omdat het toelaat omaanpassen hoe we met een klant willen communiceren. Stel bijvoorbeeld dat we een heel eenvoudig propensity-model hebben dat de klanten voor een bepaald product indeelt in “Cold” (koud), “Warm” (warm) en “Hot” (heet) (“Hot” zijn klanten met de grootste kans om te kopen en “Cold” de minste):
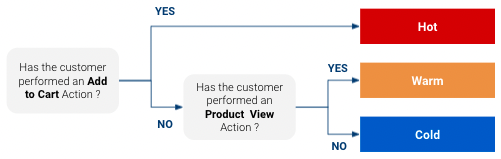
Nou, op basis van deze classificatieu kunt voor elke klasse een specifieke gerichte reactie geven. U wilt misschien een andere marketingaanpak hanteren bij een klant die op het punt staat om te kopen dan bij een klant die misschien nog niet eens van uw product heeft gehoord. Ook als u een beperkt mediabudget hebt, kunt u dit richten op klanten met een hoge waarschijnlijkheid om te kopen en niet te veel uitgeven aan klanten met een kleine kans.
Dit eenvoudige type classificatie op basis van regels kan goede resultaten opleveren en is meestal beter dan geen classificatie, maar het heeft verschillende beperkingen:
Om met deze beperkingen om te gaan, kunnen we een meer data-gedreven aanpak gebruiken: gebruik machinaal leren op onze data naar een waarschijnlijkheid van aankoop voorspellen voor elke klant.
Google Analytics begrijpen data
Google Analytics is een analytische webservice die het gebruik data en verkeer op websites en applicaties bijhoudt.
Google Analytics data kan gemakkelijk geëxporteerd naar Big Query (Google Cloud Platform volledig beheerd data magazijn service) waar het toegankelijk is via een SQL-achtige syntaxis:
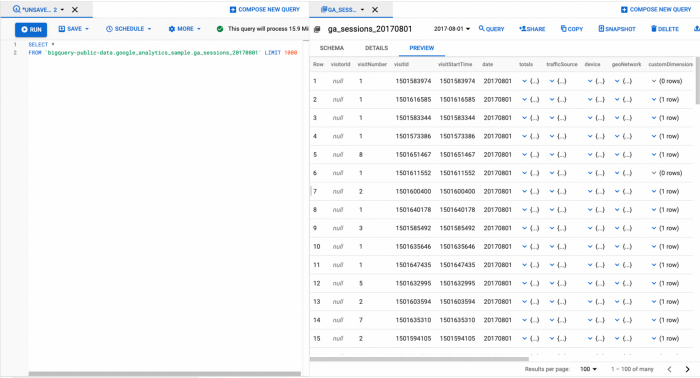
Merk op dat de Big Query-exporttabel met Google Analytics data een geneste tabel op sessieniveau:
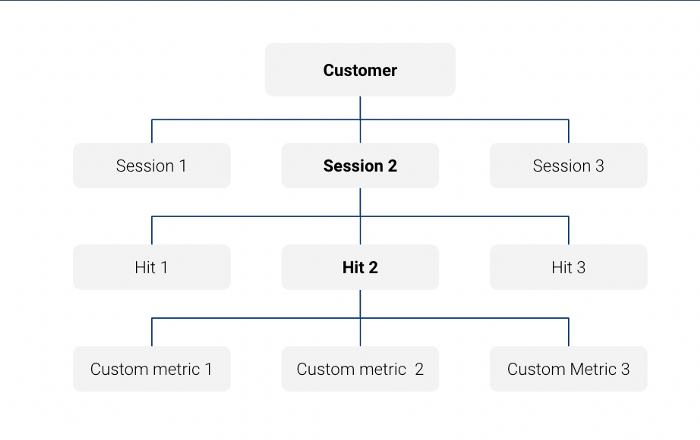
In deze query kijken we bijvoorbeeld alleen naar Functies op sessieniveau:
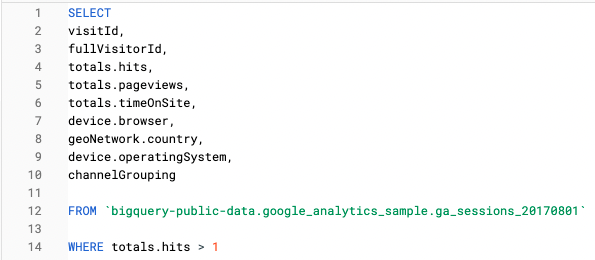
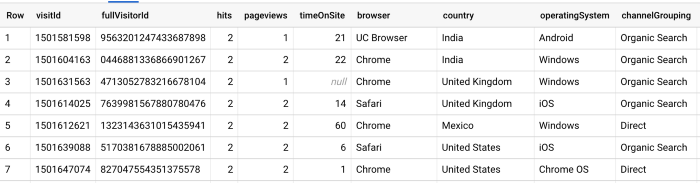
En in deze query hebben we een Unnest-functie gebruikt om dezelfde informatie op te vragen op trefniveau:


Raadpleeg voor meer informatie over GA data de documentatie. Merk op dat ons project ontwikkeld is op GA360, dus als u de nieuwste versie, GA4, gebruikt, zullen er enkele kleine verschillen zijn in het data model, vooral de tabel op gebeurtenisniveau. Er zijn openbare voorbeeldtabellen van GA360 en GA4 data beschikbaar op Big Query.
Nu we toegang hebben tot onze ruwe data bron, moeten we feature engineering uitvoeren voordat we onze tabel kunnen voeden aan een machine-learning algoritme
De juiste functies creëren
Het doel van de feature engineering-stap is om de ruwe Google Analytics data (geëxtraheerd uit Big Query) om te zetten in een tafel klaar te gebruiken voorMachinaal leren.
GA data is zeer goed gestructureerd en vereist minimale data opruimstappen. Er is echter nog steeds veel informatie aanwezig in de tabel, waarvan er veel niet bruikbaar zijn voor machinaal leren of niet zo gebruikt kunnen worden, dus het selecteren en maken van de juiste kenmerken is belangrijk. Hiervoor hebben we kenmerken ontwikkeld die het meest gecorreleerd leken te zijn met het kopen van een product.
We hebben 4 soorten functies gemaakt:
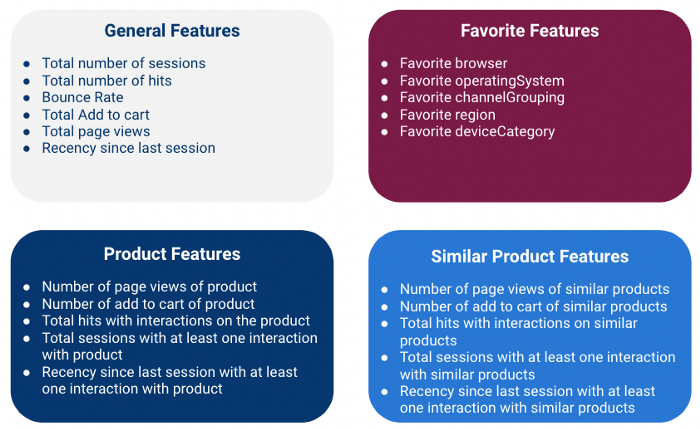
Merk op dat we al deze kenmerken op klantniveau berekenen, wat betekent dat we informatie van meerdere sessies voor elke klant samenvoegen (met het veld fullVisitorId als sleutel)
Algemene kenmerken
Globale functies zijn numerieke kenmerken die algemene informatie over de sessie geven.

Merk op dat bounce rate gedefinieerd is als % van het aantal keren dat de klant slechts één webpagina bezocht tijdens een sessie.
Het was ook belangrijk om informatie op te nemen over de frequentie van gebeurtenissenEen klant die bijvoorbeeld net uw website heeft bezocht, is waarschijnlijk eerder geneigd om iets te kopen dan een klant die uw website 3 maanden geleden heeft bezocht. Voor meer informatie over dit onderwerp kunt u de theorie op RFM (recency, frequency monetary value).
Dus hebben we een functie toegevoegd Frequentie sinds laatste sessie = 1 / Aantal dagen sinds laatste sessie waarmee de waarde kan worden genormaliseerd tussen 0 en 1
Favoriete functies
We wilden ook wat informatie toevoegen over de belangrijkste categoriale data beschikbaar zoals browser of apparaat. Aangezien die informatie op sessieniveau is, kunnen er verschillende waarden zijn voor een enkele klant, dus nemen we alleen de waarde die het meest voorkomt per klant (d.w.z. de favoriet). Om categorische kenmerken met een te hoge kardinaliteit te vermijden, houden we alleen de 5 meest voorkomende waarden voor elk kenmerk en vervangen we alle andere waarden door een “Andere” waarde.

Productkenmerken
Hoewel de eerste twee soorten kenmerken zeker nuttig zijn om ons te helpen de vraag te beantwoorden “Gaat een klant op mijn website kopen?”, zijn ze niet specifiek genoeg als we het volgende moeten weten “Gaat de klant een specifiek product kopen?”. Om deze vraag te helpen beantwoorden, hebben we productspecifieke functies gebouwd die alleen het product bevatten waarvoor we de aankoop proberen te voorspellen:

Voor Frequentie sinds laatste sessie met minstens één interactie met dit product, gebruiken we dezelfde formule als voor de Frequentie van sessies in de Algemene kenmerken. We kunnen echter gevallen hebben waarin er 0 sessies zijn met minstens één interactie met het product, in welk geval we vullen met 0. Dit is logisch vanuit zakelijk oogpunt omdat onze hoogst mogelijke waarde 1 is (als de klant sinds gisteren een sessie heeft gehad).
Vergelijkbare producteigenschappen
Naast het kijken naar de interactie van de klant met het product waarvoor we de waarschijnlijkheid van aankoop proberen te voorspellen, is het ook belangrijk om te weten dat de klant interactie had met andere producten met vergelijkbare functie en prijsklasse kan zeker nuttig zijn (d.w.z. vervangend product). Om deze reden hebben we een reeks Similar Product-functies toegevoegd die identiek zijn aan de Product-functies, behalve dat we ook gelijksoortige producten opnemen in de variabele reikwijdte. De vergelijkbare producten voor een bepaald product werden gedefinieerd met behulp van bedrijfsinvoer.

We hebben nu onze kenmerk ontworpen dataset waarop we ons machine-learningmodel kunnen trainen.
Het model trainen
Aangezien we willen weten of een klant een bepaald product gaat kopen of niet, is dit een binair classificatieprobleem.
Voor onze eerste iteratie deden we het volgende om onze machine learning dataset (1 rij per klant) te maken:
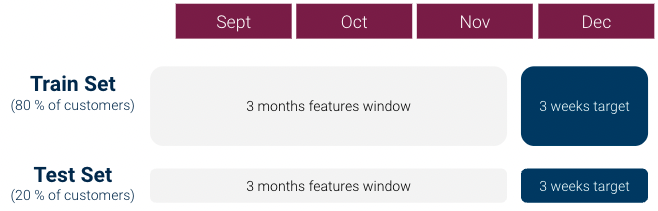
Uit wat eerste data verkenning bleek echter al snel dat er een sterk onevenwicht tussen klassen: Klasse 1 / Klasse 0 verhouding was meer dan 1:1000 en we hadden niet genoeg Klasse 1 klanten. Dit kan zeer problematisch zijn voor machine-learningmodellen.
Om deze problemen op te lossen, hebben we onze aanpak op een aantal punten aangepast:
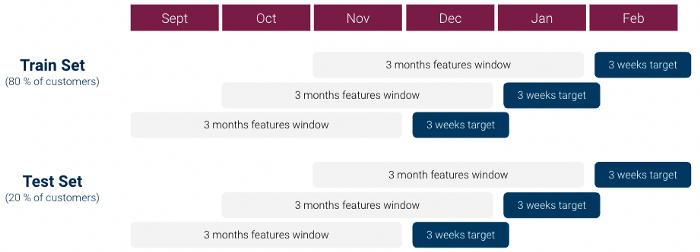
Met behulp van deze dataset hebben we met verschillende classificatiemodellen getest: Lineair model, Random Forest en XGboost, waarbij we de hyperparameters verfijnden met behulp van rasterzoeken, en uiteindelijk een XGboost-model.
Ons model evalueren
Bij het evalueren van een propensity model zijn er twee hoofdtypen evaluaties die kunnen worden uitgevoerd:
Backtest Evaluatie
Eerst hebben we backtest evaluatie: hebben we ons model toegepast op verleden historisch data en controleerde of ons model correct klanten identificeert die gaan toevoegen aan hun winkelwagentje. Aangezien we een binaire classificator gebruiken, produceert het model een waarschijnlijkheidsscore tussen 0 en 1 om klasse 1 (Toevoegen aan winkelwagentje) te zijn.
verwarringmatrix en bereken de precisie / terughalen (of hun gecombineerde vorm in def1 score). Er zijn echter twee problemen met deze eenvoudige metriek:
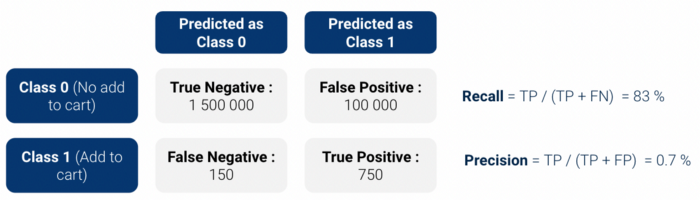
Dus besloten we om twee meetgegevens te gebruiken die meer interpreteerbaar:
Vooral de resultaten op deze punten waren erg positief, Uplift was rond 13.5.
Backtest-evaluatie is een risicovrije methode voor een eerste beoordeling van een propensity model, maar het heeft verschillende beperkingen:
Evaluatie Livetest
Dus om een beter idee te krijgen van de zakelijke waarde van ons model, moeten we het volgende doen evaluatie van live testen. Hier activeren we ons model en gebruiken we het om prioriteit te geven aan uitgaven voor reclamebudgetten:
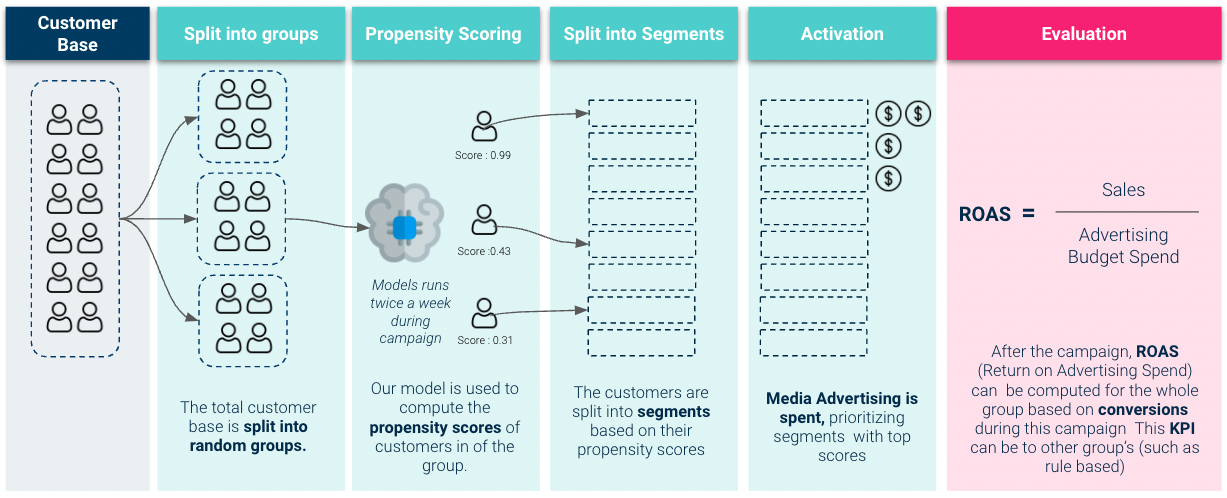
De resultaten die we tijdens de livetest hebben behaald, waren zeer solide:
Conclusie
Naast het behalen van solide prestaties, is een sterk bijkomend voordeel van onze aanpak dat onze feature engineering zeer generiek is. Bijna geen van de feature engineering-stappen hoeft te worden aangepast om ons model toe te passen op een verschillend landbereik of productbereik. Na ons eerste succes in de livetest konden we zelfs ons model op een zeer efficiënte manier uitrollen naar meerdere landen en producten.
Bedankt voor het lezen. Ik hoor graag uw opmerkingen over deze aanpak. Hebt u ooit propensity modellen gebouwd? Zo ja, wat deed u anders?
Met dank aan Bruce Delattre, Rafaëlle Aygalenq en Cédric Ly.
