Défi : étendre le marketing de précision avancé à plus de 30 marchés
Sanofi est l'un des leaders mondiaux de l'industrie pharmaceutique. Au cours des trois dernières années, Artefact a aidé l'unité commerciale Sanofi CHC (Consumer Health Care) commercialise ses médicaments en vente libre par l'intermédiaire de des tactiques et des outils numériques pour atteindre les bons consommateurs au bon moment avec le bon message, sur plus de 30 marchés..
Pour sa catégorie de produits saisonniers, Sanofi CHC a développé une approche basée sur les prévisions afin d'ajuster les dépenses en médias numériques en fonction des pics de demande prévus. Grâce à plusieurs campagnes pilotes, l'équipe de transformation numérique mondiale a pu prouver la valeur ajoutée de cette approche avec un ROAS multiplié par 2 à 4 selon les zones géographiques.
Cependant, la mise en place d'une nouvelle campagne est restée fastidieuse: Les scientifiques de data devaient effectuer une série de tâches manuelles, répétitives et sujettes aux erreurs, ce qui les empêchait de se concentrer sur d'autres projets innovants. Afin de mettre à l'échelle ses pipelines ML innovants, l'équipe scientifique de Sanofi data a défini ses besoins pour industrialiser le cas d'utilisation et a fait appel au soutien de Artefact pour concevoir et mettre en œuvre conjointement une solution robuste.
Solution : un processus d'industrialisation co-conçu basé sur 6 solutions clés
“La clé de la réussite du projet a été l'étroite collaboration entre les experts commerciaux de Sanofi et les scientifiques de Sanofi data avec l'équipe Artefact.”
- Albert Pla Planas, chef de l'équipe scientifique Data, Sanofi
Grâce à une étroite collaboration entre Artefact, data et les équipes commerciales de Sanofi, un processus d'industrialisation complet s'appuyant sur le système unifié de gestion des déchets de Sanofi a été mis en place. Databricks a été conçue. Nos objectifs communs étaient les suivants
Simplifiez la mise en place de bout en bout d'une nouvelle campagne saisonnière
Automatiser les tâches d'ingestion et de traitement de data
Rendre la solution plus robuste pour éviter les erreurs et la maintenance manuelle
Améliorer la maintenabilité et l'évolutivité du projet
Après un audit rapide d'une semaine pour définir le processus actuel et les points faibles techniques, l'équipe s'est alignée sur la mise en œuvre d'une infrastructure à l'épreuve du temps basée sur 6 solutions clés :
Séparation des préoccupations:
Le fait d'avoir un pipeline ETL séparé du processus de modèle de prévision facilite la maintenance et la mise à l'échelle. Cela nous a permis de mettre en place des contrôles automatisés ainsi qu'un système de surveillance qui envoie des reports détaillées aux équipes concernées sur l'état de l'ingestion.
Utilisation de Lac Delta comme source d'or data:
Dans les équipes de DS où l'infrastructure peut être difficile à obtenir/maintenir, Delta Lake combine les caractéristiques clés des solutions data warehouse et data lakes, éliminant ainsi la complexité de l'administration de SQL database. Il dispose également de capacités de versionnement - importantes pour la reproductibilité des ML - et servira de source unique de vérité pour data.
Regrouper autant de code que possible dans une bibliothèque Python pour simplifier les processus:
Une partie du code initial a été dispersée dans plusieurs carnets de notes au sein de Databricks, ce qui a complexifié la gestion des dépendances et la réutilisation du code. Le développement sur ordinateur portable est pertinent pour le prototypage, mais peut poser des problèmes pour l'industrialisation des projets de ML. Le fait d'avoir des bibliothèques Python clairement définies et implémentées sur le notebook et de ne garder que Databricks comme point d'entrée pour Compute a facilité la généralisation des notebooks et l'organisation des campagnes entrantes.
Tirer parti de Spark et de Databricks:
L'entraînement du modèle à l'aide de méthodes de recherche d'hyperparamètres peut être long et exigeant. C'est là que l'infrastructure autoscaling de Databricks et le runtime ML géré avec Spark et HyperOpt s'avèrent utiles. L'utilisation de calculs en mémoire de manière distribuée sur un ensemble de travailleurs accélère les performances et améliore considérablement le temps de formation.
Utilisation du suivi des flux ML:
Avec Suivi des flux ML Sanofi dispose désormais d'une interface utilisateur où les scientifiques de Data peuvent comparer les exécutions du modèle et garder une trace de tous les paramètres utilisés (version de Data et paramètres du modèle) et des résultats obtenus.
Simplification des tests et de la mise en œuvre des nouveaux modèles ML:
Un cadre générique de fabrication de modèles a été mis en place, facilitant la mise en œuvre de nouveaux modèles d'apprentissage automatique et permettant de les tester au cours d'une campagne de marketing de précision avec très peu d'efforts.
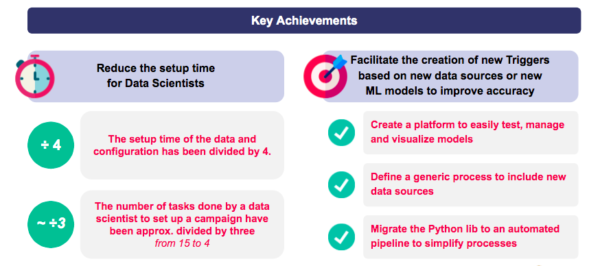
Résultats et enseignements : un temps d'installation divisé par quatre pour l'ingestion et la configuration de data
Grâce à ce projet, Sanofi CHC a pu simplifier considérablement son pipeline data et accélérer la mise à l'échelle de son cas d'utilisation Precision Marketing basé sur les prévisions.
Réduction du temps de mise en place des nouvelles campagnes:
- Le temps d'installation pour l'ingestion et la configuration de data est réduit d'un quart.
- Le nombre de tâches effectuées par les scientifiques de data pour mettre en place une nouvelle campagne a été réduit d'un tiers.
Simplification de la création de nouveaux modèles de prévision:
- Plate-forme accessible pour tester, gérer et visualiser facilement les modèles.
- Processus générique pour inclure les nouvelles sources data.
- Pipeline automatisé data.
Le projet a également permis aux équipes de tirer quatre enseignements importants pour les futurs projets axés sur la ML :
Intégrer l'ingénierie data dans les projets ML:
Impliquer les Data Engineer dès le début d'un projet afin d'accélérer l'industrialisation du pipeline, et découpler clairement les différentes étapes du pipeline (tout le traitement, la transformation et la curation des data doivent avoir lieu avant de passer aux étapes ML).
Exploiter les outils préétablis:
L'utilisation de Databricks avec Delta Lake et ML Flow a été cruciale pour le succès de l'industrialisation, garantissant une infrastructure en libre-service facile sans avoir besoin de DevOps.
Collaboration étroite entre les équipes de l'entreprise et celles du Data:
Le facteur de réussite le plus important a sans doute été l'étroite collaboration entre les experts commerciaux de Sanofi et les scientifiques du data, qui ont conçu et mené le projet, et l'équipe du Artefact, qui a apporté une expérience et un savoir-faire supplémentaires en matière d'industrialisation.
Utiliser les méthodologies agiles pour s'industrialiser:
La méthodologie agile (sprints, itérations rapides suivies de semaines de feedback et d'alignement) a été très efficace pour identifier et traiter tous les points problématiques de Sanofi et pour assurer la création de valeur pour les équipes de Sanofi.
Artefact souhaite remercier Ayaka Yanagisawa, Albert Pla Planas, Antoine Tran-Quan-Nam, Laurent Gautier et Sergio Villordo de Sanofi pour leur confiance et leur collaboration à ce projet, ainsi que l'équipe de Databricks pour son soutien réactif. Cet article a été coproduit par les équipes Sanofi CHC et Databricks avec Tristan Silhol, Maui Bar, Louise Morin et Eva Le Saux des bureaux Artefact US et France.