


Die Preise pro Token sind innerhalb eines Jahres um 75% gefallen, aber die meisten Unternehmen geben mehr für KI aus, nicht weniger. Die Kostenillusion liegt im Verborgenen.
Die Rechnung, die nicht schrumpfte
Stellen Sie sich vor, ein Finanzvorstand prüft die Ausgaben für das Quartal cloud. Das AI-Team legt ein überzeugendes Diagramm vor: Die Inferenzkosten pro Token sind im Vergleich zum Vorjahr um 75% gesunken. Die Modelle sind schneller, die APIs sind günstiger, und der Anbieter gewährt Mengenrabatte. Alles deutet auf Einsparungen hin. Dann trifft die eigentliche Rechnung ein, und der Gesamtbetrag ist höher als im letzten Quartal.
Dies ist kein hypothetisches Szenario. Es spielt sich gerade jetzt in vielen Unternehmen ab und offenbart eine Kluft zwischen dem Narrativ über KI-Kosten und der betrieblichen Realität. Die Branche feiert den Verfall der Token-Preise, als ob billigere Inputs automatisch billigere Ergebnisse bedeuten. Aber in der Praxis hat sich die Art und Weise, wie Unternehmen KI nutzen, so dramatisch verändert, dass sinkende Stückpreise nur die Hälfte der Geschichte erzählen.
Die Frage, die es zu untersuchen gilt, ist nicht, ob Token billiger werden. Sie werden es. Die aufschlussreichere Frage ist, ob sich diese Billigkeit in niedrigeren KI-Rechnungen niederschlägt oder ob sie im Stillen Konsummuster ermöglicht, die die Gesamtkosten in die entgegengesetzte Richtung treiben.
Der Preisverfall ist real
Um es klar zu sagen: Der Rückgang der Preise pro Token ist echt und signifikant. Laut Ramp's Enterprise Spending data fielen die durchschnittlichen Kosten pro Million Token bei den großen Anbietern innerhalb eines Jahres von etwa $10 auf $2,50. Die Untersuchungen von Epoch AI legen nahe, dass die Kosten für Inferenzen um das 200-fache pro Jahr sinken, wenn man sowohl die Preisgestaltung als auch Effizienzsteigerungen berücksichtigt. Andreessen Horowitz hat den Begriff “ " geprägt.“LLMflation”, um diese deflationäre Kurve zu beschreiben und eine Parallele zum Mooreschen Gesetz bei Halbleitern zu ziehen.
Die Triebkräfte sind gut bekannt. Der Wettbewerb unter den Anbietern von Frontier-Modellen (OpenAI, Anthropic, Google, Meta) hat zu einem aggressiven Preisdruck geführt. Offene Modelle wie Llama und Mistral haben eine Preisuntergrenze geschaffen, die proprietäre Anbieter nicht ignorieren können. Hardwareverbesserungen, darunter die Blackwell-Architektur von NVIDIA und kundenspezifisches Silizium von Google (TPU v6) und Amazon (Trainium), haben den Inferenzdurchsatz pro Dollar stetig verbessert. Quantisierung, spekulative Dekodierung und Destillationstechniken haben die pro Token erforderliche Rechenleistung weiter reduziert.
Für einfache, begrenzte Anwendungsfälle (ein Chatbot, der FAQs beantwortet, ein Zusammenfassungs-Tool, das Dokumente verarbeitet) führt dieser Preisverfall zu echten Einsparungen. Unternehmen, die ihre KI-Nutzungsmuster frühzeitig festgelegt haben, geben in vielen Fällen tatsächlich weniger aus.
Das Problem beginnt, wenn die Nutzungsmuster nicht beibehalten werden.
Die Verbrauchsexplosion
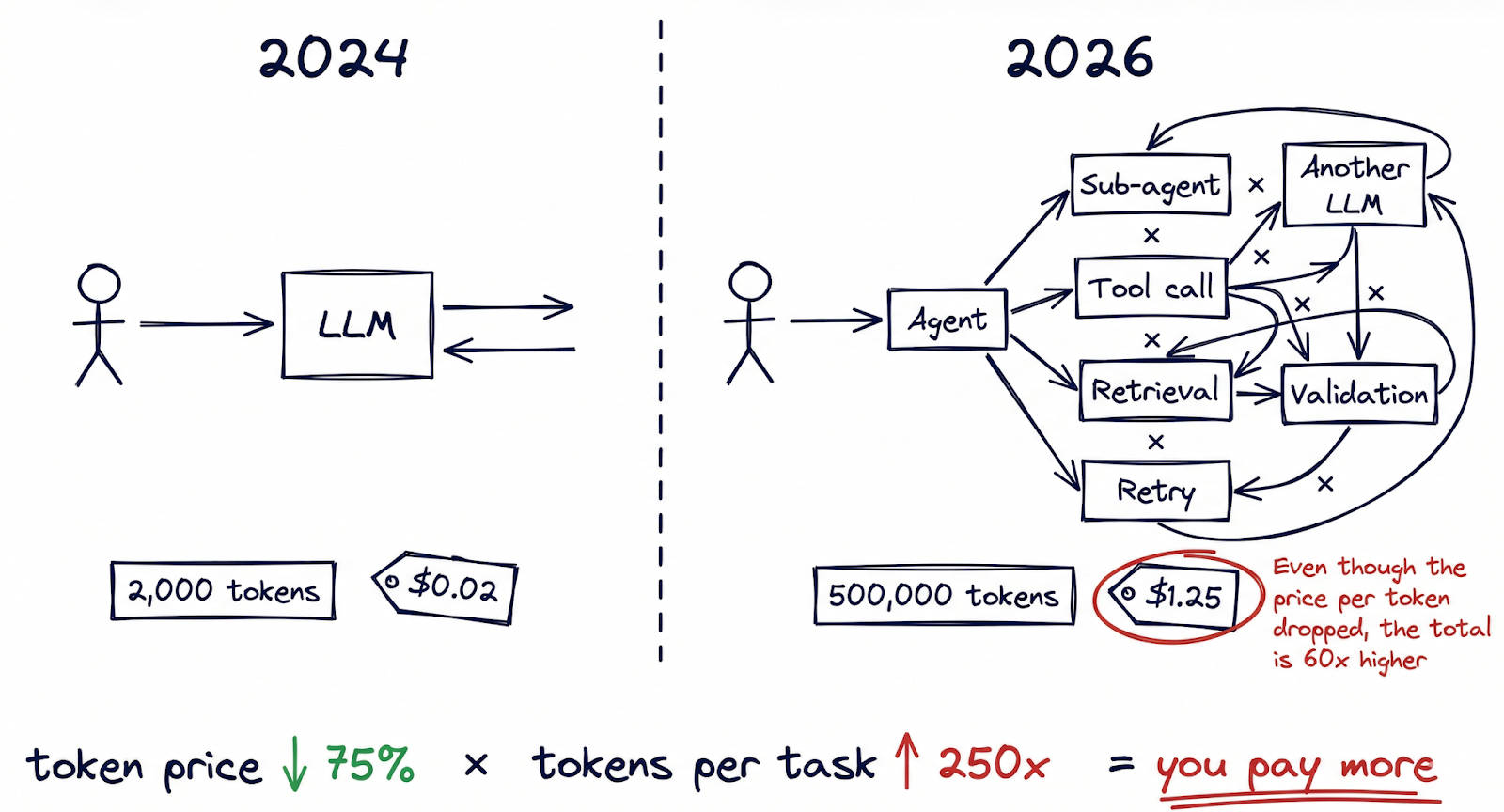
Hier ist der Teil der Gleichung, der nur selten Schlagzeilen macht: Die Anzahl der Token, die pro Aufgabe verbraucht werden, ist um Größenordnungen gestiegen, und das mit steigender Tendenz.
Vor einem Jahr bestand eine typische KI-Interaktion vielleicht aus einer einzigen Eingabeaufforderung und einer Antwort, insgesamt vielleicht 2.000 Token. Heute, Agentische KI-Workflows haben diese Arithmetik grundlegend verändert. Eine einzige Aufgabe, die von einem Multi-Agenten-System ausgeführt wird (Recherchieren eines Themas, Verfassen eines Dokuments, Validierung anhand interner Richtlinien und anschließende Iteration auf der Grundlage von Rückmeldungen), kann 50.000 bis 500.000 Token verbrauchen, bevor das endgültige Ergebnis vorliegt. Ständig aktive Programmierassistenten verarbeiten routinemäßig Millionen von Token pro Entwickler und Tag. Orchestrierungs-Frameworks für mehrere Agenten wie OpenClaw ermöglichen Workflows, bei denen Agenten andere Agenten aufrufen, wobei jede Interaktion die Anzahl der Token erhöht.
Der Beweis für diese Verschiebung ist im data sichtbar. TechCrunch berichtete über ein Phänomen, das es “tokenmaxxing”, in dem Power-User mit pauschalen KI-Abonnements beschrieben werden, die außerordentliche Mengen an Rechenleistung verbrauchen. Einige dieser “Schlussfolgerung Wale” hat über $35.000 an Rechenkosten generiert und zahlt dafür $200 pro Monat. Bei diesem Verhältnis nimmt der Anbieter eine 175-fache Subvention für seine stärksten Nutzer in Kauf.
Die finanziellen Auswirkungen zeigen sich bereits in den Ergebnissen reports. Notion gab einen Rückgang der Bruttomargen um 10 Prozentpunkte bekannt, der direkt mit den Kosten für die Einbettung von KI-Funktionen in sein Produkt zusammenhängt. Die von OpsLyft durchgeführte Analyse von KI-Implementierungen in Unternehmen ergab, dass die versteckten Kosten (Abfrageerweiterung, Einbettungsgenerierung, Verwaltung von Kontextfenstern, Wiederholungslogik) routinemäßig 40-60% zusätzlich zu den reinen Inferenzkosten ausmachten, die die meisten Teams verfolgten.
Das mentale Modell, das die meisten Unternehmen für KI-Kosten verwenden, ist in einer Welt pro Abfrage verankert. Wir sind jedoch zu einer Welt pro Workflow übergegangen, in der eine einzige Benutzeraktion Dutzende von Inferenzaufrufen über mehrere Modelle hinweg auslösen kann. Günstigere Token, multipliziert mit dramatisch mehr Token pro Aufgabe, bedeuten nicht immer geringere Ausgaben.
Big Tech rekalibriert sich neu
Wäre das Problem des Verbrauchs lediglich eine Herausforderung für die Budgetierung von Unternehmen, wäre es vielleicht zu bewältigen. Aber es gibt Anzeichen dafür, dass selbst die größten Technologieunternehmen die Grenzen der subventionierten KI-Nutzung erkennen.
Die jüngste Umstrukturierung des KI-Abonnementmodells von Google ist aufschlussreich. Das Unternehmen hat ein abgestuftes System eingeführt: AI Pro für $19.99 pro Monat und AI Ultra zu $249.99 pro Monat, mit einem neuen AI Kredite Mechanismus, der die Nutzung misst, anstatt unbegrenzten Zugang zu bieten. Die Umstellung von “all you can eat” auf einen gemessenen Verbrauch ist ein wichtiges Signal. Es deutet darauf hin, dass selbst ein Unternehmen mit der Infrastruktur und den Gewinnspannen von Google nicht in der Lage ist, unbegrenzten Token-Konsum zu Pauschalpreisen für Hunderte von Millionen von Nutzern aufrechtzuerhalten.
Die Zahlen zu den Investitionsausgaben untermauern diese Einschätzung. Alphabet hat für 2025 Investitionen in Höhe von $75 Mrd. prognostiziert, und es wird nun erwartet, dass diese Zahl im Jahr 2026 $175 bis $185 Mrd. erreichen wird, also fast eine Verdoppelung in einem einzigen Jahr. Der größte Teil dieses Anstiegs ist für die KI-Infrastruktur bestimmt: data Zentren, kundenspezifische Chips und Netzwerkkapazitäten, um den Bedarf an Inferenzen zu decken. Microsoft, Amazon und Meta machen jeweils Zusagen in ähnlichem Umfang.
Dies sind nicht die Ausgaben von Unternehmen, die die Gleichung der KI-Ökonomie gelöst haben. Es sind die Ausgaben von Unternehmen, die darum ringen, Kapazitäten für eine Nachfragekurve aufzubauen, die sie kommen sehen, aber noch nicht profitabel bedienen können. Das Subventionsmodell (das großzügige KI-Funktionen zu verbraucherfreundlichen Preisen anbietet, um die Akzeptanz zu fördern) hat sich beim Aufbau einer Benutzerbasis bewährt. Die Frage ist, wie lange es weitergehen kann, bevor die Preise die tatsächlichen Rechenkosten widerspiegeln müssen.
Das Muster erinnert an die Anfänge des cloud-Computings, als Anbieter aggressiv niedrige Preise anboten, um Marktanteile zu erobern, und dann nach und nach reservierte Instanzen, gestaffelte Preise und verbrauchsabhängige Abrechnung einführten, als die Nutzung reifer wurde. Der KI-Preiszyklus scheint die gleiche Entwicklung in einem viel kürzeren Zeitrahmen zu vollziehen.
Die On-Premise-Renaissance
Für Unternehmen, die diese Dynamik beobachten, gewinnt eine vertraute Alternative wieder an Aufmerksamkeit: der lokale Betrieb von KI-Infrastrukturen.
NVIDIAs Ankündigung von NemoClaw auf der GTC im März 2026 vorstellt, lohnt es sich, aufmerksam zu sein. NemoClaw erweitert OpenClaw (das Open-Source-Framework für agentenbasierte KI, das sich schnell zum Standard für den Aufbau von Multi-Agenten-Systemen entwickelt hat) um Funktionen auf Unternehmensniveau: Sicherheitskontrollen, Datenschutz-Routing, Audit-Protokollierung und native Unterstützung für NVIDIAs eigene Nemotron Familie von Modellen, die auf lokaler Hardware laufen. Es handelt sich dabei um eine Unternehmensdistribution des Agentic AI Stacks, die für den Einsatz vor Ort oder in privaten cloud-Umgebungen konzipiert ist.
Jensen Huang brachte die Bedeutung direkt auf den Punkt: “Was ist Ihre OpenClaw-Strategie?” ist jetzt eine Frage für die Vorstandsetage, sagte er auf der GTC audience. Das bedeutet, dass die KI-Agenteninfrastruktur für die Technologiestrategie von Unternehmen genauso wichtig wird wie die cloud-Infrastruktur vor einem Jahrzehnt, und dass Unternehmen eine bewusste Entscheidung darüber treffen müssen, wo und wie sie sie einsetzen.
Die Attraktivität von KI vor Ort geht über die Vorhersehbarkeit der Kosten hinaus, auch wenn dies wichtig ist. Sie adressiert data Souveränität (das sensible data verlässt nie das Netzwerk des Unternehmens), Einhaltung von Vorschriften (besonders wichtig, da die operativen Bestimmungen des EU AI Acts in Kraft treten), und Token-Governance (die Fähigkeit, genau zu überwachen, zu messen und zu kontrollieren, wie viel Inferenz verbraucht wird, von wem und zu welchem Zweck). In einer Welt, in der ein einziger aus dem Ruder gelaufener Agenten-Workflow über Nacht Tausende von Dollars an Token verbrauchen kann, ist eine Kontrolle auf Infrastrukturebene kein Luxus.
Das bedeutet nicht, dass jedes Unternehmen überstürzt GPU-Cluster kaufen sollte. Der Kapitalbedarf ist beträchtlich, die betriebliche Komplexität ist real und die Geschwindigkeit der Modellverbesserung bedeutet, dass die heutige On-Premise-Hardware innerhalb von achtzehn Monaten suboptimal sein kann. Aber für Unternehmen mit großen Inferenzvolumina, gesetzlichen Auflagen oder data-Sensitivitätsanforderungen wird die Wirtschaftlichkeit des Besitzes zunehmend wettbewerbsfähig mit cloud-API-Preisen.
Das Paradoxon der Demokratisierung
Hinter der Kostendynamik verbirgt sich ein tieferes Spannungsverhältnis, das es wert ist, benannt zu werden: Die Kräfte, die KI zugänglicher machen, führen auch dazu, dass ihre Wirtschaftlichkeit im großen Maßstab weniger nachhaltig ist.
OpenClaw ist vielleicht die deutlichste Illustration. Als Open-Source-Framework für den Aufbau agentenbasierter KI-Systeme hat es die Hürde für die Entwicklung anspruchsvoller Multi-Agenten-Workflows drastisch gesenkt. Ein kleines Team kann jetzt ein KI-gestütztes Produkt entwickeln, für das noch vor zwei Jahren ein eigenes Infrastrukturteam erforderlich gewesen wäre. Das ist ein echter Wandel, und das Ökosystem, das es geschaffen hat, positioniert es als so etwas wie ein Betriebssystem für persönliche und Unternehmens-KI.
Aber die Demokratisierung hat ihre eigene Kostenkurve, und ich glaube, die Branche hat das nur langsam erkannt. Wenn es trivial einfach wird, Agenten zu gründen, neigen Unternehmen dazu, viele von ihnen zu gründen. Jeder Agent verbraucht Token. Jede Interaktion zwischen mehreren Agenten vervielfacht den Verbrauch. Der Effekt ist, dass die gleiche Zugänglichkeit, die KI leistungsfähig macht, sie auch teuer macht, nicht weil jeder einzelne Anruf teuer ist, sondern weil das Gesamtvolumen der Anrufe schneller wächst, als man es einkalkuliert hat.
Dies ist die Token Kosten Illusion in seiner reinsten Form: Der Stückpreis der Intelligenz sinkt, aber die pro Ergebnis verbrauchten Einheiten steigen noch schneller.
Das Unternehmen an der Weggabelung
Diese Kräfte ziehen in dieselbe Richtung: steigender Verbrauch, Neukalibrierung der Subventionen, ausgereifte On-Premise-Optionen und wachsender regulatorischer Druck. Gemeinsam zwingen sie die Unternehmen zu einer strategischen Entscheidung, die ihre KI-Wirtschaft für die nächsten Jahre prägen wird. Es zeichnen sich drei breite Wege ab.
Weg A: Vor-Ort-Souveränität. Bauen oder leasen Sie eine dedizierte KI-Infrastruktur für Kostenkontrolle, data-Souveränität und Einhaltung von Vorschriften. NemoClaw und ähnliche Unternehmensdistributionen machen dies zunehmend realisierbar. Am besten geeignet für Unternehmen mit hohem Inferenzvolumen, sensiblen data oder Tätigkeiten in regulierten Branchen. Der Kompromiss ist die Kapitalintensität und die betriebliche Komplexität.
Weg B: Neo-Cloud-Spezialisierung. Es entsteht eine neue Kategorie von cloud-Anbietern, die sich speziell auf KI-Rechenleistung und nicht auf allgemeine cloud-Dienste konzentrieren. Diese Anbieter (CoreWeave, Lambda, Together AI und andere) bieten eine GPU-optimierte Infrastruktur mit Preismodellen, die auf inferenzlastige Arbeitslasten ausgelegt sind. Sie stellen einen Mittelweg dar: cloud-Flexibilität ohne vollständige Abhängigkeit vom Hyperscaler-Preismodell.
Pfad C: Hyperscaler-Abhängigkeit. Bauen Sie weiter auf den KI-Diensten der großen cloud-Anbieter auf und akzeptieren Sie deren Preisentwicklung im Austausch für die Integrationstiefe, die Breite des Ökosystems und die operative Einfachheit. Dieser Weg ist der einfachste für den Anfang, birgt aber das größte Risiko für Preisänderungen, wenn die Subventionen abgebaut werden.
In der Praxis werden die meisten großen Unternehmen einen hybriden Ansatz verfolgen, bei dem sie Elemente aus allen drei Bereichen mischen, je nachdem, wie empfindlich die Arbeitsbelastung, die gesetzlichen Anforderungen und die Kostenprofile sind. Der entscheidende Punkt ist, dass dies immer mehr zu einer bewussten strategischen Entscheidung wird und nicht zu einer Standardentscheidung. Angesichts zunehmender geopolitischer Spannungen, data-Lokalisierungsanforderungen und gesetzlicher Rahmenbedingungen wie dem KI-Gesetz der EU, die alle in dieselbe Richtung zielen, ist die Frage, wo Ihre KI-Inferenzen ausgeführt werden, nicht länger eine reine Technologieentscheidung. Es ist eine Governance-Entscheidung.
Verantwortungsvoller Umgang mit der KI-Wirtschaft
Wir nähern uns einem Wendepunkt in der Diskussion über KI-Kosten. In den letzten zwei Jahren war die vorherrschende Erzählung die einer unerbittlichen Deflation: Modelle werden billiger, Schlussfolgerungen werden schneller, die Hürden werden niedriger. Dieses Narrativ ist nicht falsch, aber es ist unvollständig. Sie beschreibt den Preis eines einzelnen Tokens, ohne zu berücksichtigen, wie viele Token ein Unternehmen tatsächlich verbraucht oder wie schnell diese Zahl wächst.
Die entstehende Disziplin könnte man als Token-Governance: die organisatorische Fähigkeit, die Kosten für KI-Inferenzen mit der gleichen Strenge zu überwachen, zu prognostizieren und zu verwalten, die Unternehmen bei cloud-Ausgaben, Personalbestand oder Kapitalzuweisung anwenden. Dazu gehört die Beobachtung der Kosten (in Echtzeit zu wissen, was die einzelnen Workflows, Agenten und Teams verbrauchen), die Festlegung von Verbrauchsrichtlinien (Festlegung von Grenzen für Agenten-Workflows, um einen unkontrollierten Token-Burn zu verhindern) und eine Infrastrukturstrategie (bewusste Entscheidungen darüber, wo und zu welchen Kosten Inferenzen durchgeführt werden).
Die Unternehmen, die diesen Übergang gut bewältigen, werden nicht unbedingt diejenigen sein, die am wenigsten für KI ausgeben. Sie werden diejenigen sein, die genau verstehen, was sie ausgeben und warum. In einer Welt, in der Intelligenz zu einem Gebrauchsgegenstand wird, könnte sich eine durchdachte Verwaltung ihrer Kosten als ebenso wichtig erweisen wie die Nutzung ihrer Fähigkeiten.
