


Los precios por ficha han bajado 75% en un año, pero la mayoría de las organizaciones están gastando más en IA, no menos. La ilusión de los costes se esconde a plena vista.
El proyecto de ley que no se redujo
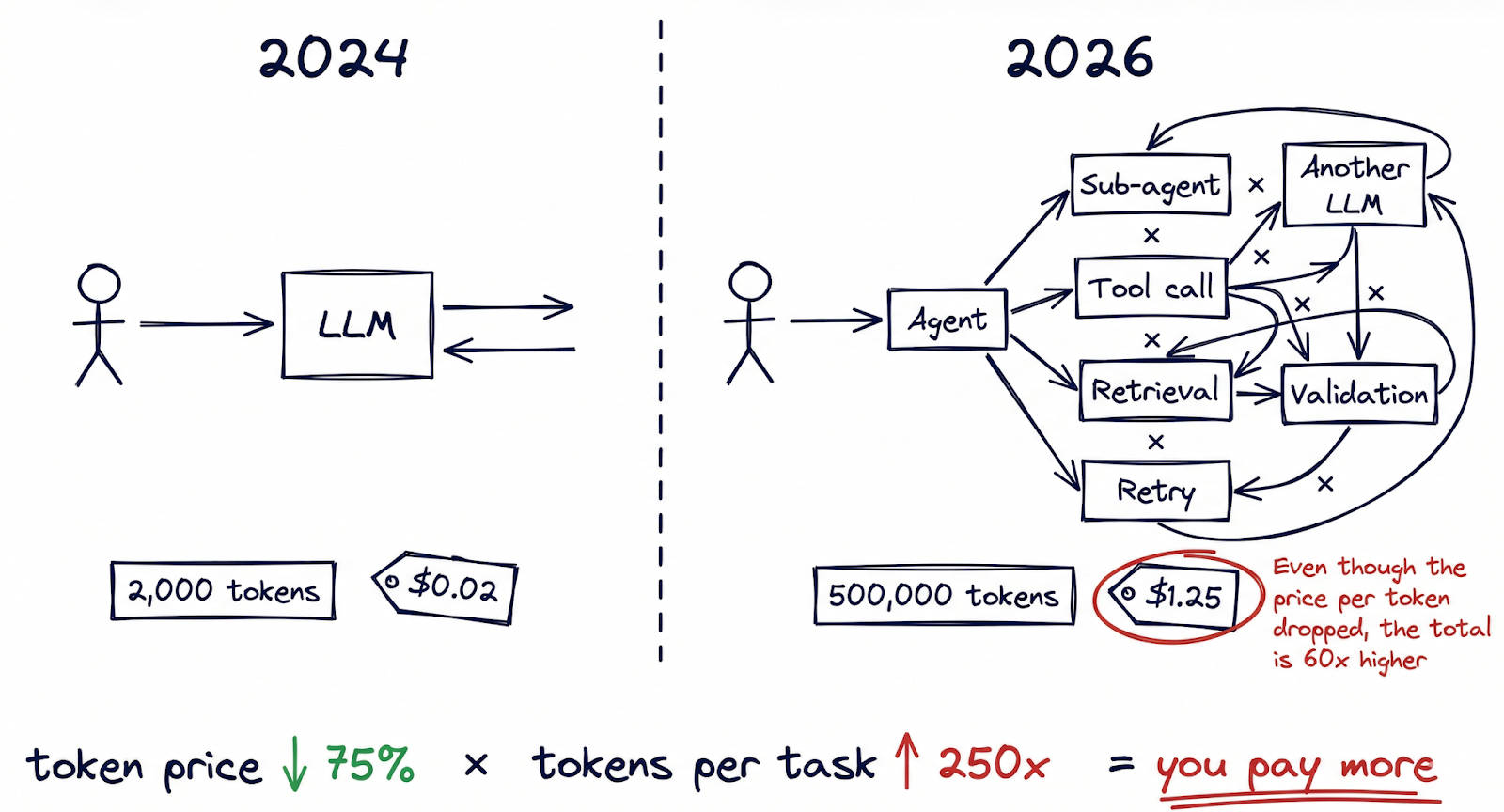
Imaginemos a un director financiero revisando el gasto trimestral de cloud. El equipo de AI presenta un gráfico convincente: los costes de inferencia por token han bajado un 75% con respecto al año anterior. Los modelos son más rápidos, las API son más baratas y el proveedor ofrece descuentos por volumen. Todo apunta a un ahorro. Entonces llega la factura real, y el total es más alto que el del trimestre anterior.
No se trata de un escenario hipotético. Se está produciendo en todas las empresas ahora mismo, y revela una brecha entre la narrativa en torno a los costes de la IA y la realidad operativa. El sector celebra el desplome de los precios de las fichas como si unos insumos más baratos significaran automáticamente unos resultados más baratos. Pero en la práctica, la forma en que las organizaciones consumen la IA ha cambiado tan drásticamente que la caída de los precios unitarios sólo cuenta la mitad de la historia.
La cuestión que merece la pena examinar no es si las fichas se están abaratando. Lo están. La cuestión más reveladora es si ese abaratamiento se está traduciendo en facturas de IA más bajas, o si está permitiendo silenciosamente patrones de consumo que empujan los costes totales en la dirección opuesta.
La bajada de precios es real
Para ser claros: el descenso de los precios por token es auténtico y significativo. Según el gasto empresarial data de Ramp, el coste medio por millón de tokens en los principales proveedores cayó de aproximadamente $10 a $2,50 en un solo año. La investigación de Epoch AI sugiere que los costes de inferencia están cayendo a un ritmo cercano a las 200 veces al año si se tienen en cuenta tanto las mejoras en los precios como en la eficiencia. Andreessen Horowitz ha acuñado el término “LLMflación” para describir esta curva deflacionista, estableciendo un paralelismo con la Ley de Moore en los semiconductores.
Los impulsores se entienden bien. La competencia entre los proveedores de modelos de frontera (OpenAI, Anthropic, Google, Meta) ha creado una agresiva presión sobre los precios. Los modelos de peso abierto como Llama y Mistral han establecido un suelo de precios que los proveedores propietarios no pueden ignorar. Las mejoras del hardware, incluida la arquitectura Blackwell de NVIDIA y el silicio personalizado de Google (TPU v6) y Amazon (Trainium), han mejorado constantemente el rendimiento de la inferencia por dólar. Las técnicas de cuantificación, descodificación especulativa y destilación han reducido aún más el cómputo requerido por token.
Para casos de uso sencillos y limitados (un chatbot que responda a las preguntas más frecuentes, una herramienta de resumen que procese documentos), esta bajada de precios está suponiendo un ahorro real. Las organizaciones que fijaron pronto sus pautas de uso de la IA están, en muchos casos, gastando realmente menos.
El problema comienza cuando los patrones de uso no se mantienen fijos.
La explosión del consumo
He aquí la parte de la ecuación que rara vez aparece en los titulares: el número de fichas consumidas por tarea ha crecido en órdenes de magnitud, y se está acelerando.
Hace un año, una interacción típica con la IA podría haber implicado una única pregunta y respuesta, quizás 2.000 tokens en total. Hoy en día, flujos de trabajo de IA agéntica han cambiado fundamentalmente esa aritmética. Una sola tarea ejecutada por un sistema multiagente (investigar un tema, redactar un documento, validarlo con respecto a las políticas internas y, a continuación, iterar basándose en la retroalimentación) puede quemar entre 50.000 y 500.000 tokens antes de producir un resultado final. Los asistentes de codificación siempre activos procesan de forma rutinaria millones de tokens por desarrollador al día. Los marcos de orquestación multiagente como OpenClaw permiten flujos de trabajo en los que los agentes llaman a otros agentes, y cada interacción agrava el recuento de tokens.
La prueba de este cambio es visible en el data. TechCrunch informó sobre un fenómeno que denominó “tokenmaxxing”, describiendo a usuarios avanzados con planes de suscripción de tarifa plana de IA que estaban consumiendo cantidades extraordinarias de computación. Algunos de estos “inferencia ballenas” generó más de $35.000 en costes de computación mientras pagaba $200 al mes. Con esa proporción, el proveedor está absorbiendo una subvención de 175x en sus usuarios más pesados.
El impacto financiero ya se está dejando notar en las ganancias reports. Notion reveló un descenso de 10 puntos porcentuales en los márgenes brutos vinculado directamente al coste de incrustar funciones de IA en todo su producto. El análisis de OpsLyft de las implantaciones de IA en las empresas descubrió que los costes ocultos (aumento de la recuperación, generación de incrustaciones, gestión de ventanas contextuales, lógica de reintentos) añadían rutinariamente entre 40 y 60% a la factura de la inferencia bruta que la mayoría de los equipos estaban rastreando.
El modelo mental que la mayoría de las organizaciones utilizan para los costes de la IA está anclado en un mundo por consulta. Pero hemos pasado a un mundo por flujo de trabajo, en el que una sola acción del usuario puede desencadenar docenas de llamadas a la inferencia a través de múltiples modelos. Unas fichas más baratas multiplicadas por un número drásticamente mayor de fichas por tarea no siempre equivalen a un menor gasto.
La gran tecnología se está recalibrando
Si el problema del consumo fuera simplemente un reto presupuestario de la empresa, podría ser manejable. Pero hay indicios de que incluso las mayores empresas tecnológicas están reconociendo los límites del uso subvencionado de la IA.
La reciente reestructuración por parte de Google de su modelo de suscripción a la IA es instructiva. La empresa introdujo un sistema escalonado: AI Pro a $19,99 al mes y AI Ultra a $249,99 al mes, con un nuevo Créditos AI mecanismo que mide el consumo en lugar de ofrecer un acceso ilimitado. El cambio del “todo lo que pueda comer” al consumo medido es una señal significativa. Sugiere que incluso una empresa con la infraestructura y los márgenes de Google no puede sostener un consumo ilimitado de tokens a un precio fijo a través de cientos de millones de usuarios.
Las cifras de gastos de capital refuerzan esta lectura. Alphabet proyectó $75 mil millones en capex para 2025, y ahora se espera que esa cifra alcance entre $175 y $185 mil millones en 2026, casi el doble en un solo año. La mayor parte de ese aumento se dirige a la infraestructura de la IA: centros de data, chips personalizados y capacidad de red para manejar la demanda de inferencia. Microsoft, Amazon y Meta están asumiendo compromisos de escala similar.
Estos no son los patrones de gasto de las empresas que han resuelto la ecuación económica de la IA. Son los patrones de gasto de empresas que se apresuran a crear capacidad para una curva de demanda que pueden ver venir, pero que aún no pueden atender de forma rentable. El modelo de subvención (ofrecer generosas capacidades de IA a precios asequibles para el consumidor para impulsar la adopción) ha sido eficaz para crear bases de usuarios. La cuestión es cuánto tiempo puede continuar antes de que los precios deban reflejar los costes reales de computación.
El patrón aquí se hace eco de los primeros días de la informática cloud, cuando los proveedores ofrecían precios agresivamente bajos para captar cuota de mercado, y luego introducían gradualmente instancias reservadas, precios escalonados y facturación basada en el consumo a medida que maduraba el uso. El ciclo de precios de la IA parece estar comprimiendo esa misma evolución en un plazo mucho más corto.
El renacimiento on-prem
Para las organizaciones que observan cómo se desarrolla esta dinámica, una alternativa conocida está ganando una atención renovada: ejecutar la infraestructura de IA localmente.
El anuncio de NVIDIA de NemoClaw en la GTC de marzo de 2026 merece la pena prestarle atención. NemoClaw amplía OpenClaw (el marco de IA agéntica de código abierto que se ha convertido rápidamente en el estándar para la construcción de sistemas multiagente) con funciones de nivel empresarial: controles de seguridad, enrutamiento de privacidad, registro de auditoría y soporte nativo para el propio software de NVIDIA Nemotron familia de modelos que se ejecutan en hardware local. Se trata, en efecto, de una distribución empresarial de la pila de IA agéntica, diseñada para funcionar in situ o en entornos privados cloud.
Jensen Huang enmarcó la importancia directamente: “¿Cuál es su estrategia OpenClaw?” es ahora una pregunta de sala de juntas, dijo en la GTC audience. La implicación es que la infraestructura de agentes de IA se está convirtiendo en tan fundacional para la estrategia tecnológica empresarial como lo fue la infraestructura cloud hace una década, y que las organizaciones necesitan una posición deliberada sobre dónde y cómo la ejecutan.
El atractivo de la IA in situ va más allá de la previsibilidad de los costes, aunque eso importa. Aborda data soberanía (el data sensible nunca abandona la red de la organización), cumplimiento de la normativa (especialmente relevante a medida que entran en vigor las disposiciones operativas de la Ley de AI de la UE), y gobernanza simbólica (la capacidad de supervisar, medir y controlar exactamente cuánta inferencia se está consumiendo, por quién y con qué propósito). En un mundo en el que un único flujo de trabajo agéntico desbocado puede quemar miles de dólares en fichas de la noche a la mañana, disponer de controles a nivel de infraestructura no es un lujo.
Esto no significa que todas las organizaciones deban apresurarse a comprar clusters de GPU. Los requisitos de capital son sustanciales, la complejidad operativa es real y el ritmo de mejora de los modelos significa que el hardware actual on-prem puede resultar subóptimo en un plazo de dieciocho meses. Pero para las organizaciones con volúmenes de inferencia significativos, restricciones normativas o requisitos de sensibilidad data, la economía de la propiedad es cada vez más competitiva con los precios de las API cloud.
La paradoja de la democratización
Hay una tensión más profunda bajo la dinámica de costes que merece la pena nombrar: las mismas fuerzas que hacen que la IA sea más accesible también están haciendo que su economía sea menos sostenible a escala.
OpenClaw es quizá el ejemplo más claro. Como marco de código abierto para construir sistemas de IA agéntica, ha reducido drásticamente la barrera para crear sofisticados flujos de trabajo multiagente. Un pequeño equipo puede ahora construir un producto impulsado por IA que hace dos años habría requerido un equipo de infraestructura dedicado. Se trata de un cambio real, y el ecosistema que ha creado lo posiciona como algo cercano a un sistema operativo para la IA personal y empresarial.
Pero la democratización tiene una curva de costes propia, y es una que creo que la industria ha tardado en reconocer. Cuando resulta trivialmente fácil crear agentes, las organizaciones tienden a crear muchos. Cada agente consume fichas. Cada interacción entre varios agentes multiplica el consumo. El efecto compuesto es que la misma accesibilidad que hace que la IA sea potente también hace que la IA sea cara, no porque cualquier llamada individual sea costosa, sino porque el volumen total de llamadas escala más rápido de lo que nadie había presupuestado.
Esta es la ficha coste ilusión en su forma más pura: el precio unitario de la inteligencia disminuye, pero las unidades consumidas por resultado aumentan aún más rápido.
La bifurcación empresarial
Estas fuerzas tiran en la misma dirección: el aumento del consumo, la recalibración de las subvenciones, la maduración de las opciones on-prem y la creciente presión reguladora. Juntas, están empujando a las empresas hacia una elección estratégica que dará forma a su economía de la IA en los próximos años. Están surgiendo tres grandes caminos.
Vía A: Soberanía in situ. Construya o alquile una infraestructura de IA dedicada para el control de costes, la soberanía data y el cumplimiento de la normativa. NemoClaw y distribuciones empresariales similares hacen que esto sea cada vez más viable. Más adecuado para organizaciones con grandes volúmenes de inferencia, data sensibles u operaciones en industrias reguladas. La contrapartida es la intensidad de capital y la complejidad operativa.
Trayectoria B: Especialización neo-nube. Está surgiendo una nueva categoría de proveedores de cloud, centrados específicamente en la computación de IA más que en los servicios de cloud de uso general. Estos proveedores (CoreWeave, Lambda, Together AI y otros) ofrecen infraestructuras optimizadas para GPU con modelos de precios diseñados para cargas de trabajo de gran inferencia. Representan un camino intermedio: Flexibilidad cloud sin dependencia total del modelo de precios del hiperescalador.
Ruta C: Hyperscaler Dependencia. Seguir basándose en los servicios de IA de los principales proveedores cloud, aceptando su evolución de precios a cambio de profundidad de integración, amplitud del ecosistema y simplicidad operativa. Este camino es el más fácil para empezar, pero conlleva la mayor exposición a los cambios de precios a medida que se deshacen las subvenciones.
En la práctica, la mayoría de las grandes organizaciones seguirán un enfoque híbrido, mezclando elementos de los tres en función de la sensibilidad de la carga de trabajo, los requisitos normativos y los perfiles de costes. El punto crítico es que esto se está convirtiendo en una decisión estratégica deliberada más que en una decisión por defecto. Con el aumento de las tensiones geopolíticas, los requisitos de localización data y los marcos normativos como la Ley de IA de la UE, todos tirando en la misma dirección, la cuestión de dónde se ejecuta su inferencia de IA ya no es puramente una decisión tecnológica. Es una decisión de gobernanza.
Gestionar responsablemente la economía de la IA
Nos acercamos a un punto de inflexión en la conversación sobre los costes de la IA. Durante los dos últimos años, la narrativa dominante ha sido la de la deflación implacable: modelos cada vez más baratos, inferencia cada vez más rápida, barreras cada vez más bajas. Esa narrativa no es errónea, pero es incompleta. Describe el precio de un único token sin tener en cuenta cuántos tokens consume realmente una organización, o lo rápido que crece ese número.
La disciplina emergente podría denominarse gobernanza simbólicaLa capacidad organizativa para supervisar, prever y gestionar los costes de inferencia de la IA con el mismo rigor que las empresas aplican al gasto cloud, la plantilla o la asignación de capital. Esto incluye la observabilidad de los costes (saber en tiempo real lo que consume cada flujo de trabajo, agente y equipo), las políticas de consumo (establecer límites en los flujos de trabajo de los agentes para evitar la quema descontrolada de fichas) y la estrategia de infraestructura (tomar decisiones deliberadas sobre dónde se ejecuta la inferencia y a qué coste).
Las organizaciones que gestionen bien esta transición no serán necesariamente las que menos gasten en IA. Serán las que entiendan, con precisión, lo que están gastando y por qué. En un mundo en el que la inteligencia se está convirtiendo en una utilidad, gestionar su economía de forma meditada puede resultar tan importante como aprovechar sus capacidades.
