

Pour activer les sous-titres en anglais, cliquez sur l'icône "CC" puis sur "Paramètres". Ensuite, choisissez l'option "Subtiles" puis "Traduire automatiquement" en anglais ou dans la langue de votre choix.
Le 27 septembre, lors de la conférence Big Data & AI Paris 2022, Justine Nerce, partenaire conseil Data chez Artefact et Killian Gaumont, responsable conseil Data chez Artefact, ainsi qu'Amine Mokhtari, spécialiste de l'analyse Data chez Google Cloud, ont animé un atelier sur le maillage Data. Le maillage Data est l'un des sujets les plus brûlants de l'industrie data aujourd'hui. Mais qu'est-ce que c'est ? Quels sont ses avantages pour les entreprises ? Et surtout, comment les entreprises peuvent-elles le déployer avec succès dans leurs organisations ?
Data mesh est un nouveau modèle organisationnel et technologique pour la gestion décentralisée de data. Il s'agit d'une approche d'architecture distribuée pour la gestion de data analytique, qui permet aux utilisateurs d'accéder facilement à data et de l'interroger là où elle se trouve, sans la transporter d'abord vers un lac ou un entrepôt de data. Data mesh repose sur quatre principes fondamentaux :
L'atelier a été divisé en trois parties :
- Valeur commerciale : Pourquoi adopter une approche produit/maille ? Comment sert-elle les objectifs commerciaux de l'entreprise ?
- Approche de déploiement : Comment réussir ? Quelles sont les étapes à suivre et le modèle d'organisation à utiliser ?
- Pile technologique : Pourquoi choisir Google comme solution technologique ?
Pour lancer la discussion sur la valeur commerciale, Justine Nerce a expliqué : “L'une des meilleures raisons d'adopter une approche produit/maillage est qu'elle élimine deux cercles vicieux. Le premier consiste à ‘réinventer la roue’ chaque fois qu'une nouvelle utilisation de data apparaît : une nouvelle équipe est formée et crée son propre pipeline data pour répondre à ses besoins spécifiques. Le résultat ? Aucune possibilité de partage, aucune possibilité de réutilisation des technologies choisies. La seconde est la ‘construction d'un monolithe’ lorsqu'une nouvelle utilisation de data aboutit dans le carnet de commandes d'une équipe centrale de data, puis est confiée à des équipes non spécialisées dans data qui procèdent à une collecte massive de data, à une transformation générique et au développement de cas d'utilisation, avec le risque de ne pas répondre aux besoins des utilisateurs”.”
Mais avec une approche produit, le cercle vicieux se transforme en cercle vertueux. Lorsqu'une nouvelle utilisation de data émerge, au lieu de construire quelque chose de nouveau, data mesh recherche ce qui existe déjà et peut être réutilisé. Il identifie les domaines déjà chargés de traiter des sujets donnés et recherche les produits data existants qui peuvent accélérer la création et le développement de nouveaux besoins, soit tels quels, soit dans le cadre de processus itératifs visant à créer de nouveaux produits personnalisés. Tous ces produits peuvent être publiés dans le catalogue de l'entreprise.
Comment les produits data créent de la valeur pour l'entreprise
Les produits Data existent depuis longtemps dans les entreprises, mais dans le maillage data, les utilisations et les qualifications de data sont essentiellement différentes, explique Killian Gaumont :
“Le produit data d'aujourd'hui est une combinaison de data mis à la disposition de l'entreprise pour un usage professionnel et de caractéristiques spécifiques qui facilitent l'utilisation et la réutilisation de data”.
Pour être inclus dans le maillage data, un produit data doit être :
- Dirigé par une équipe de propriétaires dévoués ;
- Orienté vers l'utilisateur final et largement adopté ;
- De qualité tout au long de son cycle de vie ;
- Réutilisable tel quel ou pour construire d'autres produits ;
- Accessible à tous les utilisateurs ;
- Normalisé pour que tout le monde parle la même langue.
Chez Artefact, les produits data sont classés en trois familles de produits différentes. “Il y a des produits bruts tels que les databases utilisées pour les processus d'entreprise - qui sont néanmoins des produits data”, assure Killian. “Ensuite, il y a les produits data enrichis d'algorithmes personnalisés ou de recommandations de produits, comme Interaction 360°. Au sommet, on trouve des produits finis alignés sur l'utilisation, tels que les tableaux de bord. Il s'agit de produits grand public, conçus pour créer de la valeur en liant le développement du produit à la stratégie de l'entreprise.”
Déploiement du maillage data dans l'entreprise
Artefact’L'approche de data pour le déploiement du maillage commence à petite échelle, en priorisant les cas d'utilisation et les points problématiques de l'entreprise. Tous les domaines et produits data nécessaires pour chaque cas d'utilisation prioritaire (du data brut aux produits finis) sont ensuite identifiés. Une future équipe est constituée pour développer les premiers produits et définir des normes. Il est ensuite possible d'identifier les produits connexes qui seront développés à l'avenir.
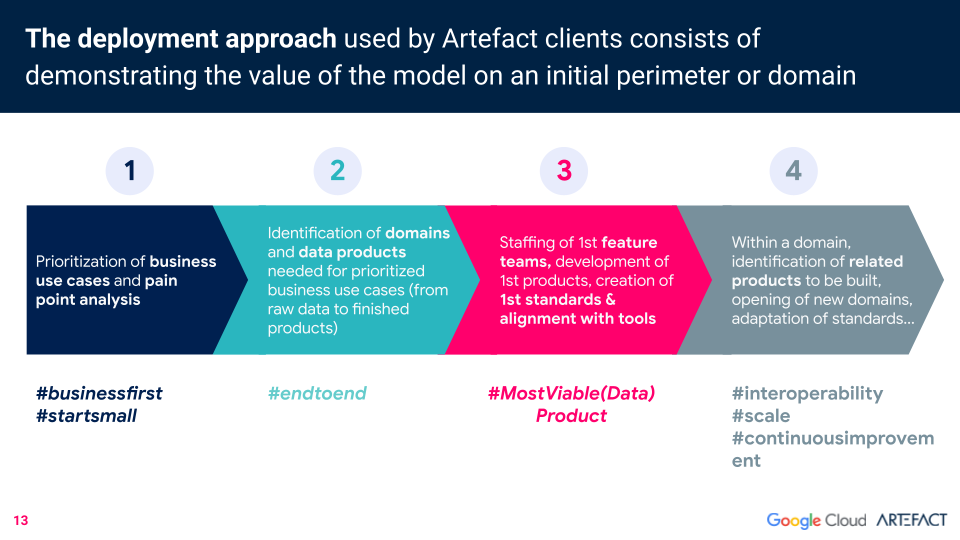
Il y a trois conditions préalables au déploiement d'un réseau maillé data. La première : l'élimination des silos.
“Pour que data mesh soit un succès, nous devons évoluer vers un modèle organisationnel qui brise les silos entre l'informatique, data et l'entreprise pour avoir des équipes de plate-forme composées d'équipes multi-domaines et multi-produits, dans toutes les entités”, déclare Killian. “Il est évident que cela ne se fera pas du jour au lendemain. Mais nous avons déjà commencé à briser les silos en intégrant les équipes commerciales dans les équipes informatiques data afin que les équipes de produits qui développent des produits data puissent travailler plus efficacement”.”
Le deuxième prérequis est le propriétaire du produit Data, qui joue un rôle clé dans la coordination de la mise en œuvre du maillage data. Le propriétaire du produit data a trois missions : concevoir, construire et promouvoir les produits data. Les deux premières missions sont explicites ; la troisième est tout aussi importante, car la force d'un produit data réside dans le fait qu'il est adopté et utilisé par les entreprises. “Le propriétaire du produit data est chargé de veiller à ce que le produit data soit documenté, compréhensible et accessible aux utilisateurs, et aligné sur les besoins de l'entreprise. Les critères de réussite sont ses indicateurs clés de performance : utilisation, performance technique, qualité de data”, ajoute Killian.
La dernière condition préalable est que l'entreprise soit en mesure de définir clairement et continuellement ses domaines data et, une fois que le modèle a prouvé sa valeur, qu'elle soit capable de passer à l'échelle supérieure.
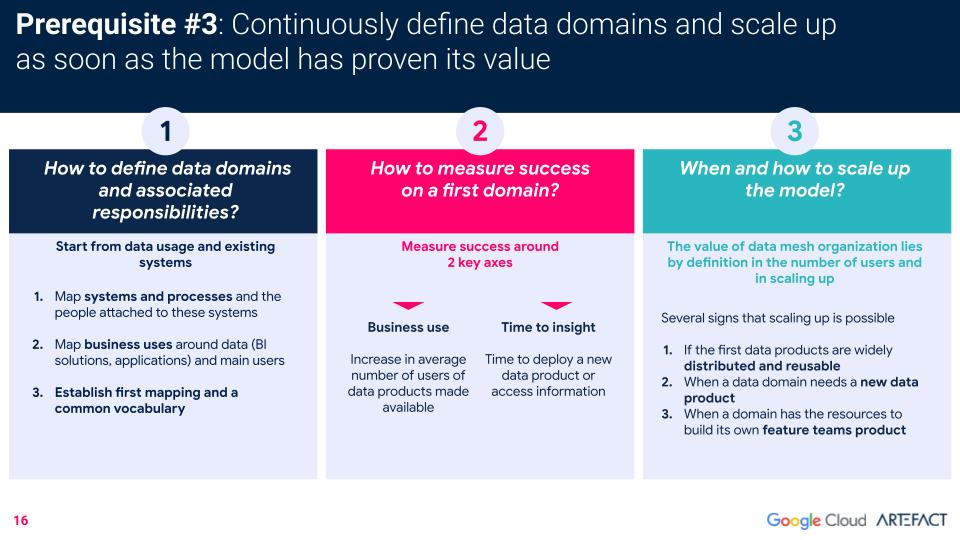
Voici les trois questions les plus fréquemment posées par les clients qui mettent en œuvre le maillage data, ainsi que les recommandations de Artefact pour définir avec succès les domaines, mesurer la réussite et savoir quand il est opportun de passer à l'échelle supérieure.
La pile technologique : gérer le maillage data avec Google Cloud
“ La première chose dont les équipes data et informatiques ont besoin pour mettre en œuvre data mesh est la capacité à rendre leur data découvrable et accessible en le publiant dans un catalogue data ”, commence Amine Mohktari. “Pour ce faire, Google dispose d'un premier pilier, Big Query, qui permet la création d'ensembles data partageables. Le deuxième pilier, le catalogue lui-même, est rendu possible par Analytics Hub, qui crée des liens vers tous les datasets créés par les différents membres de l'organisation ou ses partenaires afin que les abonnés puissent y accéder facilement.”
“Il est important de comprendre que seuls des liens vers data sont créés - jamais de copies. Grâce à ce système, les abonnés peuvent utiliser data comme s'il leur appartenait, même s'il reste dans son emplacement physique d'origine. Cela reste vrai même si vous avez des jeux de data stockés dans un autre cloud”, assure Amine.
L'expérience de l'utilisateur est un principe majeur du système et se reflète dans tous les aspects du maillage de data, non seulement en facilitant le partage et la composition de data, mais aussi en maintenant data disponible en permanence, quel que soit le nombre d'utilisateurs actifs.
En ce qui concerne la sécurité et la gouvernance de data, Google a tout prévu avec Dataplex, sa structure intelligente de data qui permet d'unifier data distribué et d'automatiser la gestion et la gouvernance de data à travers ce data afin d'alimenter l'analyse à l'échelle. Avec un cadre de gestion des identités et des accès (IAM) permettant d'attribuer une identité unique à chaque consommateur de data, “Dataplex offre aux entreprises un ensemble de piliers techniques qui leur permettent de réaliser n'importe quelle mise en œuvre de la gouvernance de la manière la plus simple possible”, explique M. Amine.
“Chez Google Cloud, notre objectif est de vous fournir un data platform sans serveur qui permettra à vos équipes data de se concentrer sur des domaines tels que les processus et les cas d'utilisation métier, où elles ont une valeur ajoutée que personne d'autre ne peut produire.”
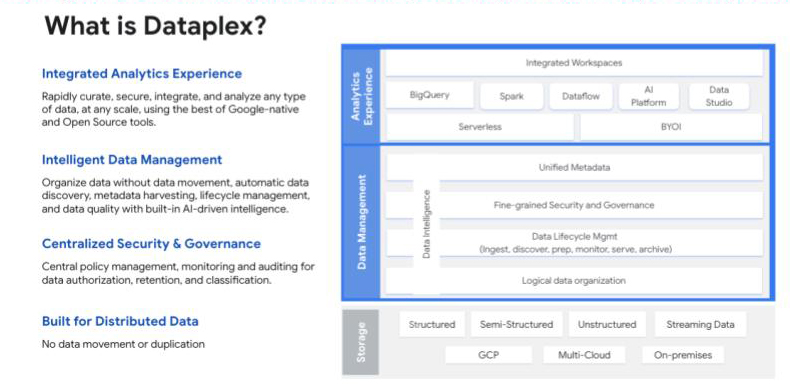
Le Dataplex de Google offre aux utilisateurs une vue à 360° des produits data publiés et de leur qualité.
Conclusion : trois pièges à éviter lors de la mise en œuvre du maillage data
NE LE FAITES PAS > Rester bloqué dans une vision de projet au lieu d'une vision de produit
DO > Définissez les produits prioritaires data en fonction des différentes utilisations ;
NE LE FAITES PAS > Développer le nouveau modèle trop rapidement
DO > Testez le modèle à l'aide d'un modèle opérationnel bien défini ;
NE LE FAITES PAS > Déployer un écosystème technique trop complexe
DO > Maintenez la pile technologique à un niveau peu élevé afin d'avoir le plus grand nombre de joueurs possible.
