

Sehen Sie sich die replay des Workshops an (auf Französisch) | Um die englischen Untertitel zu aktivieren, klicken Sie auf das Symbol "CC" und dann auf "Einstellungen". Wählen Sie anschließend die Option "Untertitel" und dann "Automatisch übersetzen" auf Englisch oder die Sprache Ihrer Wahl.
Am 27. September haben Justine Nerce, Data Consulting Partner bei Artefact, und Killian Gaumont, Data Consulting Manager bei Artefact, zusammen mit Amine Mokhtari, Data Analytics Specialist bei Google Cloud, auf der Big Data & AI Paris 2022 Conference einen Data Mesh Workshop durchgeführt. Data Mesh ist heute eines der heißesten Themen in der data-Branche. Aber was ist es? Was sind seine geschäftlichen Vorteile? Und vor allem, wie können Unternehmen es erfolgreich in ihrem Unternehmen einsetzen?
Data Mesh ist ein neues organisatorisches und technologisches Modell zur dezentralen data-Verwaltung. Es handelt sich um eine verteilte Architektur für die Verwaltung von analytischen data, die es den Benutzern ermöglicht, auf data zuzugreifen und es dort abzufragen, wo es sich befindet, ohne es zunächst in einen data-See oder ein Lager zu transportieren. Data mesh basiert auf vier Grundprinzipien:
Der Workshop wurde in drei Teile aufgeteilt:
- Geschäftswert: Warum ein Produkt/Mesh-Ansatz? Wie dient er den Geschäftszielen des Unternehmens?
- Ansatz für die Bereitstellung: Wie kann man Erfolg haben? Welche Schritte sollten unternommen werden und welches Organisationsmodell sollte verwendet werden?
- Technologie-Stapel: Warum Google als Technologielösung wählen?
Zum Auftakt der Diskussion über den Geschäftswert erklärte Justine Nerce: “Einer der besten Gründe für die Einführung eines Produkt-/Mesh-Ansatzes ist, dass er zwei Teufelskreise beseitigt. Der erste besteht darin, das Rad jedes Mal neu zu erfinden, wenn eine neue Anwendung für data auftaucht: Ein neues Team wird gebildet, das seine eigene data-Pipeline erstellt, um seine spezifischen Bedürfnisse zu erfüllen. Das Ergebnis? Keine gemeinsame Nutzung, keine Wiederverwendbarkeit für die gewählten Technologien. Das zweite ist der ‘Aufbau eines Monolithen’, wenn eine neue Anwendung für data im Backlog eines zentralen data-Teams landet und dann an nicht auf data spezialisierte Teams weitergereicht wird, die massive data-Sammlungen, generische Transformationen und die Entwicklung von Anwendungsfällen durchführen, mit dem Risiko, nicht auf die Bedürfnisse der Benutzer einzugehen.‘
Aber mit einem Produktansatz wird aus dem Teufelskreis ein Tugendkreis. Wenn eine neue Anwendung für data auftaucht, sucht data mesh nach dem, was bereits existiert und wiederverwendet werden kann, anstatt etwas Neues zu entwickeln. Es identifiziert Bereiche, die bereits für die Bearbeitung bestimmter Themen zuständig sind, und sucht nach bestehenden data-Produkten, die die Erstellung und Entwicklung neuer Bedürfnisse beschleunigen können, entweder so wie sie sind oder in iterativen Prozessen zur Erstellung neuer, maßgeschneiderter Produkte. Und alle diese Produkte können im Katalog des Unternehmens veröffentlicht werden.
Wie data-Produkte geschäftlichen Mehrwert schaffen
Data-Produkte gibt es in Unternehmen schon seit langem, aber bei data-Gewebe sind die Verwendungszwecke und Qualifikationen von data grundsätzlich anders, erklärt Killian Gaumont:
“Das heutige data-Produkt ist eine Kombination aus data, das dem Unternehmen für die geschäftliche Nutzung zur Verfügung gestellt wird, und spezifischen Funktionen, die die Nutzung und Wiederverwendbarkeit von data erleichtern”.
Um in das data-Netz aufgenommen zu werden, muss ein data-Produkt sein:
- Geführt von einem Team von engagierten Eigentümern;
- Endbenutzerorientiert und weit verbreitet;
- Von Qualität während des gesamten Lebenszyklus;
- Wiederverwendbar als solches oder zum Bau anderer Produkte;
- Zugänglich für alle Benutzer;
- Standardisiert, damit alle die gleiche Sprache sprechen.
Bei Artefact werden die data-Produkte in drei verschiedene Produktfamilien eingeteilt. “Es gibt Rohprodukte wie databases, die für Geschäftsprozesse verwendet werden - die dennoch data-Produkte sind”, versichert Killian. “Als nächstes gibt es data-Produkte, die mit kundenspezifischen Algorithmen oder Produktempfehlungen angereichert sind, wie z.B. Interaction 360°. An der Spitze stehen fertige Produkte, die auf die Nutzung ausgerichtet sind, wie z.B. Dashboards. Das sind Produkte für den Endverbraucher, die einen Mehrwert schaffen, indem sie die Produktentwicklung mit der Geschäftsstrategie verbinden.”
Einsatz von data Mesh im gesamten Unternehmen
Artefact’Der Ansatz von data Mesh Deployment beginnt im Kleinen, indem die Anwendungsfälle und Probleme des Unternehmens priorisiert werden. Anschließend werden alle Bereiche und data-Produkte identifiziert, die für jeden priorisierten Anwendungsfall benötigt werden (von data-Rohmaterial bis zu fertigen Produkten). Ein zukünftiges Team wird zusammengestellt, um die ersten Produkte zu entwickeln und Standards festzulegen. Dann können verwandte Produkte, die in der Zukunft entwickelt werden sollen, identifiziert werden.
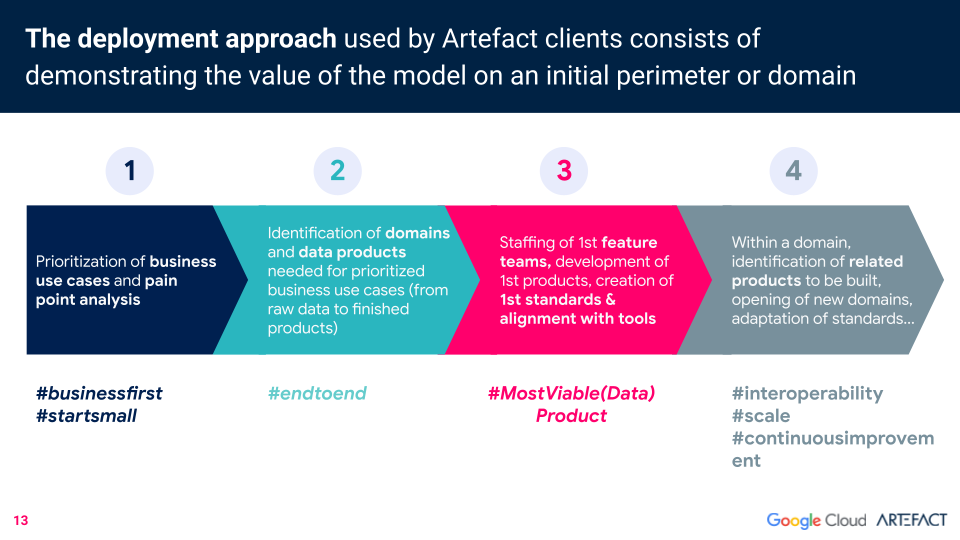
Für den Einsatz von data Mesh gibt es drei Voraussetzungen. Die erste: das Aufbrechen von Silos.
“Wenn data Mesh ein Erfolg werden soll, müssen wir zu einem Organisationsmodell übergehen, das die Silos zwischen IT, data und Business aufbricht, um Plattformteams zu haben, die sich aus bereichs- und produktübergreifenden Teams zusammensetzen, und zwar über alle Einheiten hinweg”, sagt Killian. “Das wird natürlich nicht über Nacht geschehen. Aber wir haben bereits damit begonnen, die Silos aufzubrechen, indem wir die Business-Teams in die IT data-Teams integriert haben, damit die Produktteams, die data-Produkte entwickeln, effizienter arbeiten können.”
Die zweite Voraussetzung ist der Data Product Owner, der eine Schlüsselrolle bei der Koordinierung der Implementierung des data-Netzes spielt. Der data-Produktverantwortliche hat drei Aufgaben: data-Produkte zu entwerfen, zu entwickeln und zu fördern. Die ersten beiden Aufgaben sind selbsterklärend; die dritte ist ebenso wichtig, denn die Stärke eines data-Produkts liegt darin, dass es vom Unternehmen angenommen und genutzt wird. “Der data-Produktverantwortliche ist dafür verantwortlich, dass das data-Produkt dokumentiert, für die Benutzer verständlich und zugänglich ist und sich an den Geschäftsanforderungen orientiert. Die Kriterien für seinen Erfolg sind seine KPIs: Nutzung, technische Leistung, data-Qualität”, fügt Killian hinzu.
Die letzte Voraussetzung ist, dass das Unternehmen in der Lage ist, seine data-Domänen klar und kontinuierlich zu definieren, und dass es, sobald sich das Modell bewährt hat, in der Lage ist, es zu skalieren.
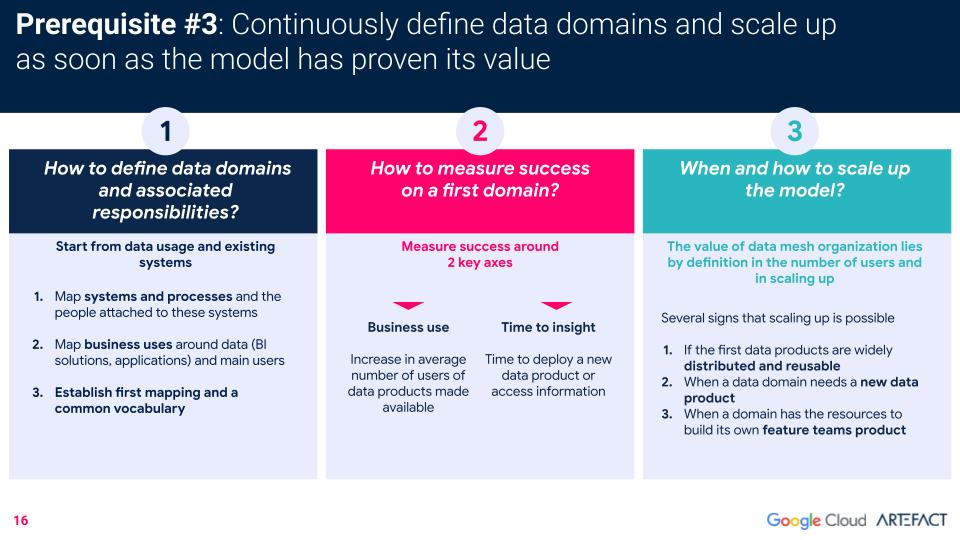
Dies sind die drei am häufigsten gestellten Fragen von Kunden, die das data-Netz implementieren, zusammen mit den Empfehlungen von Artefact zur erfolgreichen Definition von Bereichen, zur Messung des Erfolgs und zum Erkennen des richtigen Zeitpunkts für eine Erweiterung.
Der technische Stack: Verwaltung des data Mesh mit Google Cloud
“Das erste, was data- und IT-Teams brauchen, um data mesh zu implementieren, ist die Möglichkeit, ihre data auffindbar und zugänglich zu machen, indem sie sie in einem data-Katalog veröffentlichen”, beginnt Amine Mohktari. “Um dies zu erreichen, hat Google eine erste Säule, Big Query, die die Erstellung von gemeinsam nutzbaren data-Sets ermöglicht. Die zweite Säule, der Katalog selbst, wird durch Analytics Hub ermöglicht, der Links zu allen datasets erstellt, die von verschiedenen Mitgliedern der Organisation oder ihren Partnern erstellt wurden, so dass die Abonnenten leicht darauf zugreifen können.”
“Es ist wichtig zu verstehen, dass nur Links zu data erstellt werden - niemals Kopien. Dank dieses Systems können Abonnenten data so nutzen, als ob es ihnen gehören würde, auch wenn es an seinem ursprünglichen physischen Ort verbleibt. Das gilt auch dann, wenn Sie data-Sets in einem anderen cloud gespeichert haben”, versichert Amine.
Die Benutzerfreundlichkeit ist ein wichtiger Grundsatz des Systems und spiegelt sich in allen Aspekten des data-Netzes wider, nicht nur in der Erleichterung der gemeinsamen Nutzung von data und der Komposition von data, sondern auch in der ständigen Verfügbarkeit von data, unabhängig davon, wie viele Benutzer aktiv sind.
Was die data-Sicherheit und -Governance betrifft, so hat Google mit Dataplex eine intelligente data-Struktur entwickelt, die dabei hilft, verteilte data zu vereinheitlichen und die data-Verwaltung und -Governance über diese data zu automatisieren, um Analysen im großen Maßstab zu ermöglichen. Zusammen mit einem Identitäts- und Zugriffsmanagement-Framework (IAM), das jedem data-Konsumenten eine eindeutige Identität zuweist, “bietet Dataplex Unternehmen eine Reihe von technischen Säulen, die es ihnen ermöglichen, jede Art von Governance auf die einfachste Weise zu implementieren”, erklärt Amine.
“Unser Ziel bei Google Cloud ist es, Ihnen ein serverloses data platform zur Verfügung zu stellen, das es Ihren data-Teams ermöglicht, sich auf Bereiche wie Prozesse und geschäftliche Anwendungsfälle zu konzentrieren, in denen sie einen Mehrwert haben, den niemand sonst erzeugen kann.”
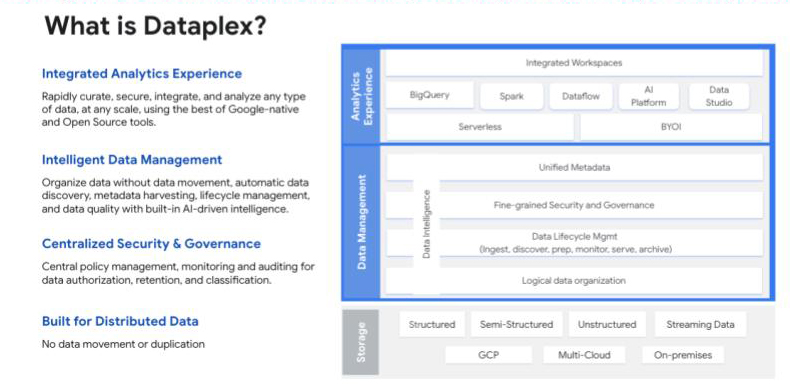
Der Dataplex von Google bietet Nutzern eine 360°-Ansicht der veröffentlichten data-Produkte und ihrer Qualität
Fazit: Drei Fallstricke, die Sie bei der Implementierung des data-Netzes vermeiden sollten
NICHT > Bleiben Sie in einer Projektvision statt einer Produktvision stecken
DO > Legen Sie die Prioritäten der data-Produkte nach den verschiedenen Verwendungszwecken fest;
NICHT > Das neue Modell zu schnell ausweiten
DO > Testen Sie das Modell mit einem gut definierten Betriebsmodell;
NICHT > Ein übermäßig komplexes technisches Ökosystem einsetzen
DO > Halten Sie den Technologiestapel klein, um möglichst viele Spieler zu haben.
