

Vea el replay del taller (en francés) | Para activar los subtítulos en inglés, haga clic en el icono "CC" y después en "Configuración". Después, elija la opción "Subtítulos" y luego "Traducción automática" al inglés o al idioma de su elección.
El 27 de septiembre, en la Conferencia Big Data & AI París 2022, Justine Nerce, socia consultora de Data en Artefact y Killian Gaumont, director de consultoría de Data en Artefact, junto con Amine Mokhtari, especialista en análisis de Data en Google Cloud, impartieron un taller sobre malla Data. La malla Data es uno de los temas más candentes del sector data en la actualidad. Pero, ¿qué es? ¿Cuáles son sus ventajas empresariales? Y, sobre todo, ¿cómo pueden las empresas implantarla con éxito en sus organizaciones?
La malla Data es un nuevo modelo organizativo y tecnológico para la gestión descentralizada de data. Se trata de un enfoque de arquitectura distribuida para la gestión de data analíticos, que permite a los usuarios acceder y consultar fácilmente los data allí donde residen, sin necesidad de transportarlos primero a un lago o almacén de data. La malla Data se basa en cuatro principios fundamentales:
El taller se dividió en tres partes:
- Valor empresarial: ¿Por qué adoptar un enfoque de producto/malla? ¿Cómo sirve a los objetivos empresariales de la empresa?
- Enfoque del despliegue: ¿Cómo lograr el éxito? ¿Qué pasos hay que dar y qué modelo organizativo hay que utilizar?
- Pila tecnológica: ¿Por qué elegir Google como solución tecnológica?
Para iniciar el debate sobre el valor empresarial, Justine Nerce explicó: “Una de las mejores razones para adoptar un enfoque de producto/malla es que elimina dos círculos viciosos. El primero es ‘reinventar la rueda’ cada vez que surge un nuevo uso para el data: se forma un nuevo equipo que crea su propio pipeline data para atender sus necesidades específicas. ¿El resultado? Cero compartibilidad, cero reutilización de las tecnologías elegidas. La segunda es la ‘construcción de un monolito’, cuando un nuevo uso para data acaba en el backlog de un equipo central de data, y luego se traspasa a equipos no especializados en data que llevan a cabo una recopilación masiva de data, una transformación genérica y el desarrollo de casos de uso, con el riesgo de no responder a las necesidades de los usuarios.”
Pero con un enfoque de producto, el círculo vicioso se convierte en virtuoso. Cuando surge un nuevo uso para data, en lugar de construir algo nuevo, la malla data busca lo que ya existe y puede reutilizarse. Identifica los dominios que ya se encargan de tratar determinados temas y busca productos data existentes que puedan acelerar la creación y el desarrollo de nuevas necesidades, ya sea tal cual o en procesos iterativos para crear productos nuevos y personalizados. Y todos estos productos pueden publicarse en el catálogo de la empresa.
Cómo crean valor empresarial los productos data
Los productos Data existen en las empresas desde hace mucho tiempo, pero en la malla data, los usos y cualificaciones del data son esencialmente diferentes, explica Killian Gaumont:
“El producto data actual es una combinación de data puesto a disposición de la empresa para uso empresarial y características específicas que facilitan el uso y la reutilización de data”.
Para ser incluido en la malla data, un producto data debe ser:
- Dirigida por un equipo de propietarios dedicados;
- Orientado al usuario final y ampliamente adoptado;
- De calidad durante todo su ciclo de vida;
- Reutilizable tal cual o para construir otros productos;
- Accesible para todos los usuarios;
- Estandarizados para que todos hablen el mismo idioma.
En Artefact, los productos data se clasifican en tres familias de productos diferentes. “Hay productos brutos, como las bases data utilizadas para los procesos empresariales, que no dejan de ser productos data”, asegura Killian. “A continuación están los productos data enriquecidos con algoritmos personalizados o recomendaciones de productos, como Interaction 360°. En la parte superior están los productos acabados alineados con el uso, como los cuadros de mando. Se trata de productos de línea de consumo, diseñados para crear valor vinculando el desarrollo de productos a la estrategia empresarial.”
Despliegue de la malla data en toda la empresa
Artefact’s approach to data mesh deployment starts small, by prioritizing the business's use cases and pain points. A continuación se identifican todos los dominios y productos data necesarios para cada caso de uso empresarial priorizado (desde data en bruto hasta productos acabados). Se reúne un futuro equipo para desarrollar los primeros productos y establecer normas. A continuación, se pueden identificar los productos relacionados que se construirán en el futuro.
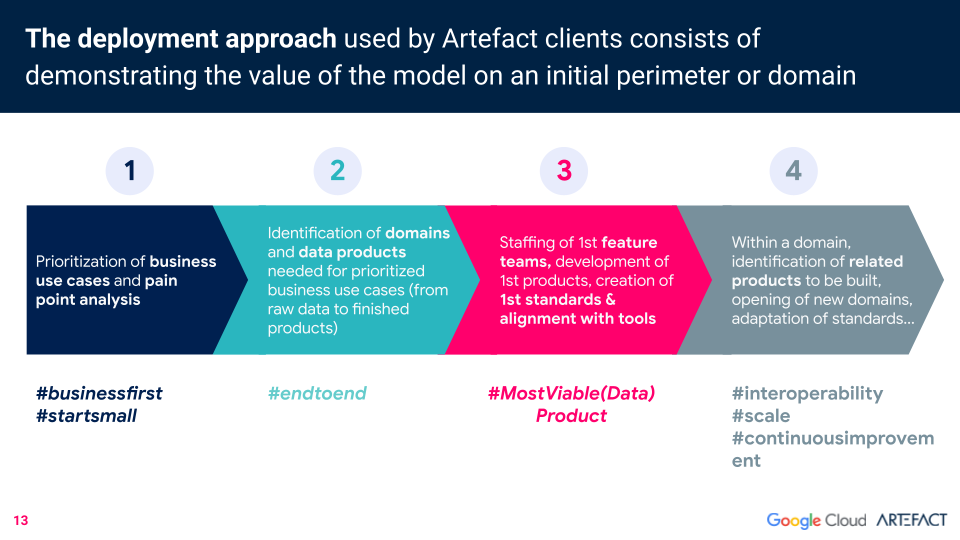
Hay tres requisitos previos para el despliegue de la malla data. El primero: acabar con los silos.
“Si queremos que la malla data sea un éxito, debemos avanzar hacia un modelo organizativo que rompa los silos entre TI, data y negocio para contar con equipos de plataforma compuestos por equipos multidisciplinares y multiproducto, en todas las entidades”, afirma Killian. “No ocurrirá de la noche a la mañana, obviamente. Pero ya hemos empezado a romper los silos integrando los equipos de negocio en los equipos data de TI para que los equipos de producto que desarrollan productos data puedan trabajar con mayor eficacia.”
El segundo requisito previo es el propietario del producto Data, que desempeña un papel clave en la coordinación de la implantación de la malla data. El propietario del producto data tiene tres misiones: diseñar, construir y promover los productos data. Las dos primeras misiones se explican por sí solas; la tercera es igualmente importante, ya que la fuerza de un producto data reside en que sea adoptado y utilizado por la empresa. “El propietario del producto data es responsable de garantizar que el producto data esté documentado, sea comprensible y accesible para los usuarios y se ajuste a las necesidades de la empresa. Los criterios de su éxito son sus KPI: utilización, rendimiento técnico, calidad data”, añade Killian.
El último requisito previo es que la empresa sea capaz de definir de forma clara y continua sus dominios data y, una vez que el modelo haya demostrado su valor, sea capaz de ampliarlo.
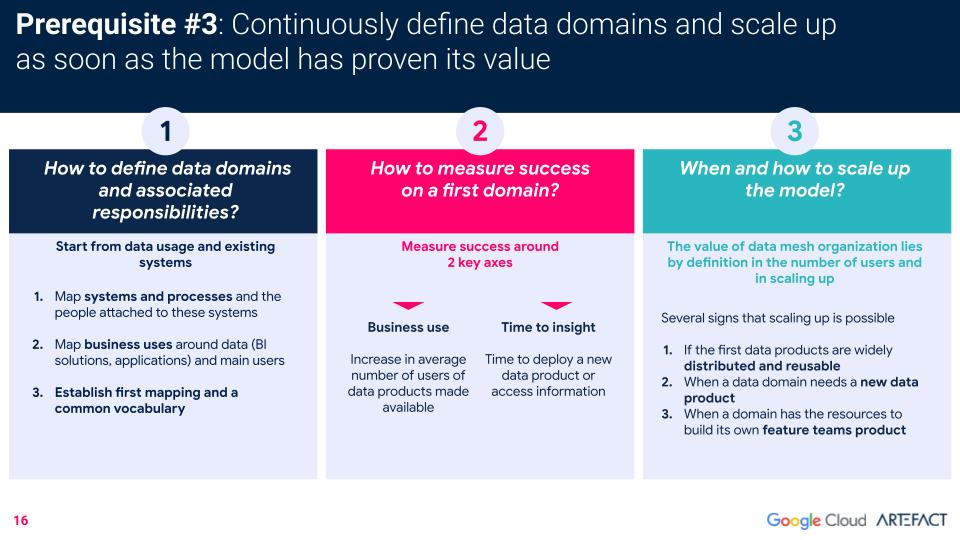
Estas son las tres preguntas más frecuentes de los clientes que implantan la malla data, junto con las recomendaciones de Artefact para definir con éxito los dominios, medir el éxito y saber cuándo es oportuno ampliar.
La pila tecnológica: gestión de la malla data con Google Cloud
“Lo primero que necesitan los equipos data e informáticos para implantar la malla data es la capacidad de hacer que sus data sean descubribles y accesibles publicándolos en un catálogo data”, comienza Amine Mohktari. “Para lograrlo, Google cuenta con un primer pilar, Big Query, que permite crear conjuntos data compartibles. El segundo pilar, el catálogo propiamente dicho, es posible gracias a Analytics Hub, que crea enlaces a todos los datasets creados por diversos miembros de la organización o sus socios para que los suscriptores puedan acceder a ellos fácilmente.”
“Es importante entender que sólo se hacen enlaces a data, nunca copias. Gracias a este sistema, los abonados pueden utilizar el data como si les perteneciera, aunque permanezca en su ubicación física original. Esto sigue siendo cierto incluso cuando se tienen conjuntos data almacenados en un cloud diferente”, asegura Amine.
La experiencia del usuario es un principio fundamental del sistema y se refleja en todos los aspectos de la malla data, no sólo al facilitar el uso compartido de data y la composición de data, sino al mantener data permanentemente disponible, independientemente del número de usuarios activos.
En cuanto a la seguridad y gobernanza data, Google lo tiene cubierto con Dataplex, su tejido inteligente data que ayuda a unificar la data distribuida y a automatizar la gestión y gobernanza data en toda esa data para potenciar la analítica a escala. Junto con un marco de Gestión de Identidades y Accesos (IAM) para asignar una identidad única a cada consumidor data, “Dataplex ofrece a las empresas un conjunto de pilares técnicos que les permiten llevar a cabo cualquier implementación de gobernanza de la forma más sencilla posible”, explica Amine.
“En Google Cloud, nuestro objetivo es proporcionarle un data platform sin servidor que permita a sus equipos data centrarse en áreas como los procesos y los casos de uso empresarial, donde tienen un valor añadido que nadie más puede producir”.”
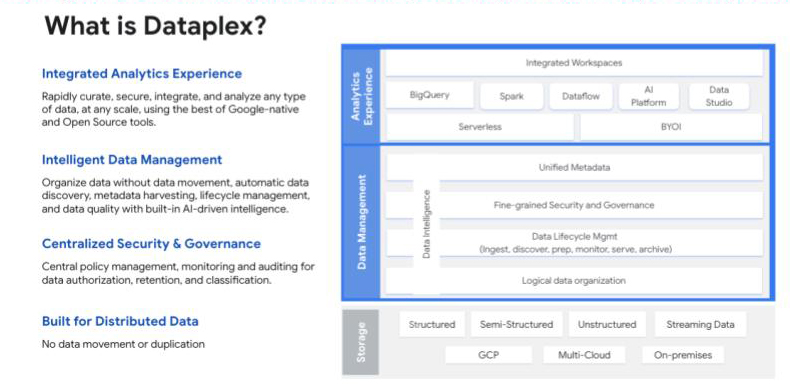
El Dataplex de Google ofrece a los usuarios una visión de 360° de los productos data publicados y de su calidad
Conclusión: tres escollos a evitar al implantar la malla data
NO > Quedarse estancado en una visión de proyecto en lugar de una visión de producto
DO > Defina los productos data prioritarios según los diferentes usos;
NO > Ampliar el nuevo modelo demasiado rápido
DO > Pruebe el modelo con un modelo operativo bien definido;
NO > Desplegar un ecosistema técnico demasiado complejo
DO > Mantenga la pila tecnológica pequeña para tener tantos jugadores como sea posible.
