

Bekijk de replay van de workshop (in het Frans) | Om Engelse subtiles in te schakelen, klikt u op het pictogram "CC" en vervolgens op "Settings" (Instellingen). Kies daarna de optie "Subtiles" en vervolgens "Auto-translate" naar Engels of de taal van uw keuze.
Op 27 september op de Big Data & AI Paris 2022 Conferentie, Justine Nerce, Data Consulting Partner bij Artefact en Killian Gaumont, Data Consulting Manager bij Artefact, samen met Amine Mokhtari, Data Analytics Specialist bij Google Cloud, voerden een Data Mesh Workshop. Data mesh is een van de heetste onderwerpen in de data industrie van vandaag. Maar wat is het? Wat zijn de zakelijke voordelen? En vooral, hoe kunnen bedrijven het succesvol inzetten in hun organisaties?
Data mesh is een nieuw organisatorisch en technologisch model voor gedecentraliseerd data beheer. Het is een gedistribueerde architectuurbenadering voor het beheer van analytisch data, die gebruikers in staat stelt om eenvoudig toegang te krijgen tot data en het te bevragen waar het zich bevindt, zonder het eerst te transporteren naar een data-meer of -magazijn. Data mesh is gebaseerd op vier kernprincipes:
De workshop was verdeeld in drie delen:
- Zakelijke waarde: Waarom een product/mesh benadering? Hoe dient het de bedrijfsdoelstellingen van het bedrijf?
- Implementatie-aanpak: Hoe bereik je succes? Welke stappen moeten er worden genomen en welk organisatiemodel moet er worden gebruikt?
- Technologiestapel: Waarom kiezen voor Google als technologische oplossing?
Om de discussie over Zakelijke waarde te beginnen, legde Justine Nerce uit: “Een van de beste redenen om voor een product/mesh aanpak te kiezen is dat het twee vicieuze cirkels elimineert. De eerste is ‘het wiel opnieuw uitvinden’ telkens als er een nieuw gebruik voor data ontstaat: er wordt een nieuw team gevormd dat zijn eigen data-pijplijn creëert om aan zijn specifieke behoeften te voldoen. Het resultaat? Nul deelbaarheid, nul herbruikbaarheid voor de gekozen technologieën. Het tweede is ‘het bouwen van een monoliet’ wanneer een nieuw gebruik voor data terecht komt in de backlog van een centraal data team, en vervolgens wordt overgedragen aan niet-data gespecialiseerde teams die massaal data verzamelen, generieke transformatie en use case ontwikkeling uitvoeren, met het risico dat er niet wordt ingespeeld op gebruikersbehoeften.”
Maar met een productbenadering wordt de vicieuze cirkel een positieve. Als er een nieuw gebruik voor data ontstaat, zoekt data mesh, in plaats van iets nieuws te bouwen, naar wat al bestaat en hergebruikt kan worden. Het identificeert domeinen die al belast zijn met het afhandelen van bepaalde onderwerpen en zoekt naar bestaande data producten die het creëren en ontwikkelen van nieuwe behoeften kunnen versnellen, hetzij zoals ze zijn of in iteratieve processen om nieuwe, aangepaste producten te creëren. En al deze producten kunnen worden gepubliceerd in de bedrijfscatalogus.
Hoe data producten bedrijfswaarde creëren
Data-producten bestaan al lang in bedrijven, maar in data-gaas zijn de toepassingen en kwalificaties van data wezenlijk anders, legt Killian Gaumont uit:
“Het huidige data product is een combinatie van data beschikbaar gesteld aan het bedrijf voor zakelijk gebruik en specifieke functies die het gebruik en de herbruikbaarheid van data vergemakkelijken”.
Om in data mesh opgenomen te worden, moet een data product:
- Geleid door een team van toegewijde eigenaren;
- Gericht op eindgebruikers en op grote schaal toegepast;
- Van kwaliteit gedurende de hele levenscyclus;
- Herbruikbaar als zodanig of voor het bouwen van andere producten;
- Toegankelijk voor alle gebruikers;
- Gestandaardiseerd zodat iedereen dezelfde taal spreekt.
Bij Artefact worden data-producten onderverdeeld in drie verschillende productfamilies. “Er zijn ruwe producten zoals databases die gebruikt worden voor bedrijfsprocessen - die desondanks data-producten zijn”, verzekert Killian. “Vervolgens zijn er data-producten die verrijkt zijn met aangepaste algoritmen of productaanbevelingen, zoals Interaction 360°. Bovenaan staan afgewerkte producten die afgestemd zijn op het gebruik, zoals dashboards. Dit zijn producten in de consumentenlijn, ontworpen om waarde te creëren door productontwikkeling te koppelen aan bedrijfsstrategie.”
Inzet van data mesh in de hele onderneming
Artefact’De aanpak van de inzet van data mesh begint klein, door de use cases en pijnpunten van het bedrijf te prioriteren. Alle domeinen en data producten die nodig zijn voor elke geprioriteerde business use case (van ruwe data tot afgewerkte producten) worden dan geïdentificeerd. Een toekomstig team wordt samengesteld om de eerste producten te ontwikkelen en standaarden vast te stellen. Vervolgens kunnen gerelateerde producten die in de toekomst gebouwd moeten worden, geïdentificeerd worden.
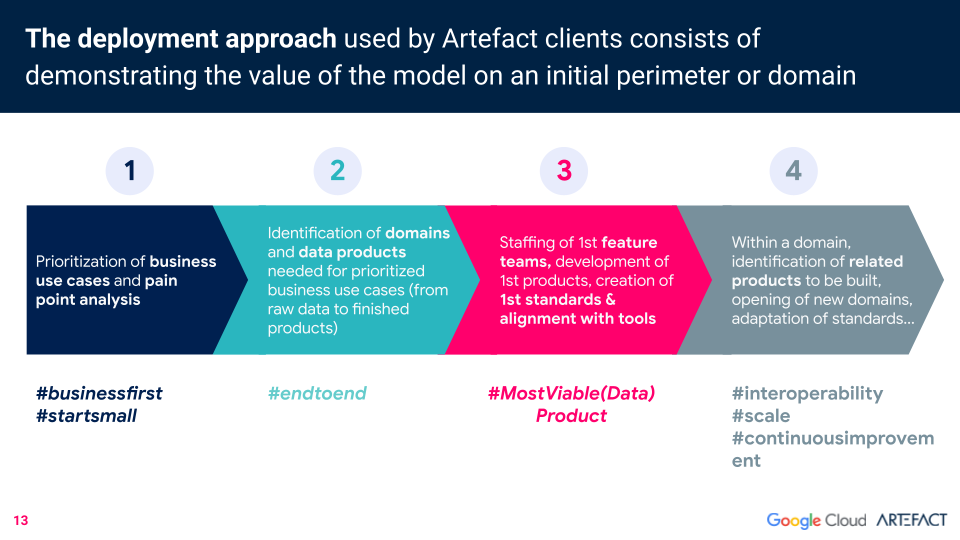
Er zijn drie voorwaarden voor de inzet van data mesh. De eerste: het afbreken van silo's.
“Als we van data mesh een succes willen maken, moeten we toe naar een organisatiemodel dat de silo's tussen IT, data en de business doorbreekt, zodat we platformteams krijgen die bestaan uit domein- en productoverschrijdende teams, over alle entiteiten heen”, zegt Killian. “Dat zal natuurlijk niet van de ene op de andere dag gebeuren. Maar we zijn al begonnen met het afbreken van silo's door business teams te integreren in IT data teams, zodat productteams die data producten ontwikkelen efficiënter kunnen werken.”
De tweede vereiste is de Data Product Owner, die een sleutelrol speelt bij het coördineren van de implementatie van de data mazen. De data producteigenaar heeft drie missies: het ontwerpen, bouwen en promoten van data producten. De eerste twee missies spreken voor zich; de derde is net zo belangrijk, omdat de kracht van een data product ligt in het feit dat het wordt overgenomen en gebruikt door de business. “De data producteigenaar is er verantwoordelijk voor dat het data product gedocumenteerd is, begrijpelijk en toegankelijk voor gebruikers, en afgestemd op de behoeften van de business. De criteria voor zijn succes zijn zijn KPI's: gebruik, technische prestaties, data-kwaliteit”, voegt Killian toe.
De laatste voorwaarde is dat het bedrijf zijn data domeinen duidelijk en continu kan definiëren en, zodra het model zijn waarde heeft bewezen, kan opschalen.
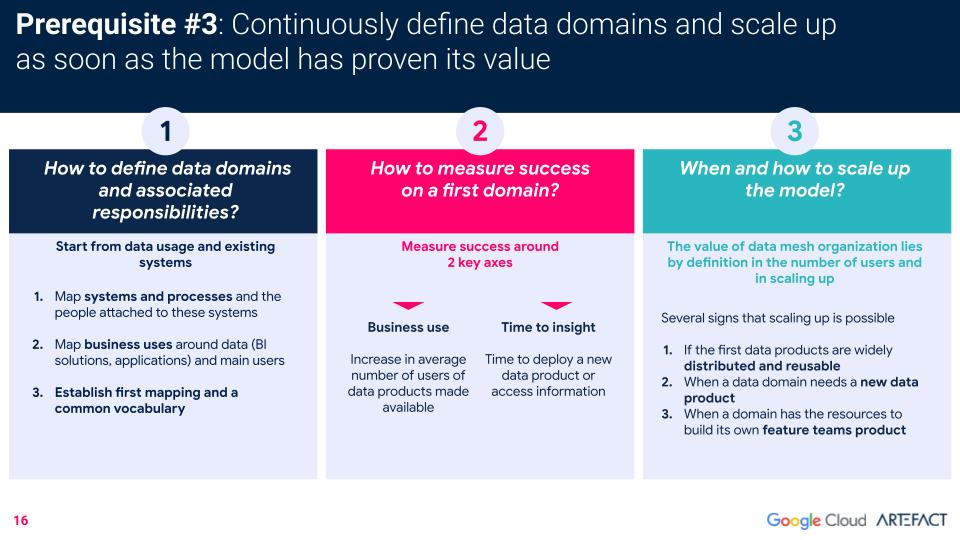
Dit zijn de drie meest gestelde vragen door klanten die data mesh implementeren, samen met Artefact's aanbevelingen voor het succesvol definiëren van domeinen, het meten van succes en het weten wanneer het opportuun is om op te schalen.
De technische stapel: data mesh beheren met Google Cloud
“Het eerste wat data- en IT-teams nodig hebben om data mesh te implementeren, is de mogelijkheid om hun data vindbaar en toegankelijk te maken door het te publiceren in een data-catalogus”, begint Amine Mohktari. “Om dit te bereiken heeft Google een eerste pijler, Big Query, die het creëren van deelbare datasets mogelijk maakt. De tweede pijler, de catalogus zelf, wordt mogelijk gemaakt door Analytics Hub, die links creëert naar alle datasets die door verschillende leden van de organisatie of haar partners zijn gemaakt, zodat abonnees er gemakkelijk toegang toe hebben.”
“Het is belangrijk om te begrijpen dat er alleen links naar data worden gemaakt - nooit kopieën. Dankzij dit systeem kunnen abonnees data gebruiken alsof het van hen is, ook al blijft het op de originele fysieke locatie. Dit geldt zelfs als je data sets hebt opgeslagen in een andere cloud”, verzekert Amine.
Gebruikerservaring is een belangrijk principe van het systeem en wordt weerspiegeld in alle aspecten van data mesh, niet alleen in het faciliteren van data delen en data samenstellen, maar ook door data permanent beschikbaar te houden, ongeacht hoeveel gebruikers actief zijn.
Wat betreft data beveiliging en governance, Google heeft het onder controle met Dataplex, hun intelligente data fabric die helpt gedistribueerde data te verenigen en data beheer en governance over die data te automatiseren om analytics op schaal mogelijk te maken. Samen met een IAM-raamwerk (Identity and Access Management) om een unieke identiteit toe te wijzen aan elke data-consument, “biedt Dataplex bedrijven een set technische pijlers waarmee ze elke implementatie van governance op de eenvoudigst mogelijke manier kunnen uitvoeren”, legt Amine uit.
“Bij Google Cloud is het ons doel om u een serverloze data platform te bieden waarmee uw data teams zich kunnen richten op gebieden zoals processen en zakelijke use cases, waar ze toegevoegde waarde hebben die niemand anders kan produceren.”
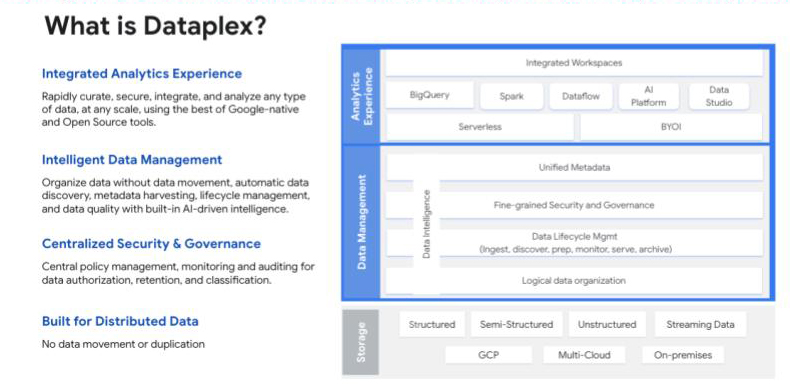
Google's Dataplex geeft gebruikers een 360° beeld van gepubliceerde data producten en hun kwaliteit
Conclusie: drie valkuilen die u moet vermijden bij het implementeren van data mesh
NIET DOEN > Vast blijven zitten in een projectvisie in plaats van een productvisie
DO > Definieer prioriteit data producten volgens verschillend gebruik;
NIET DOEN > Het nieuwe model te snel opschalen
DO > Test het model met een goed gedefinieerd besturingsmodel;
NIET DOEN > Een te complex technisch ecosysteem implementeren
DO > Houd de techniekstapel klein om zoveel mogelijk spelers te hebben.
