

作者


商品分类优化是零售业的一个关键流程,它包括 策划理想的产品组合 以满足消费者的需求,同时考虑到物流方面的诸多限制。零售商需要确保在正确的时间提供正确数量的正确产品。通过利用 data 和消费者洞察力,零售商可以根据客户偏好、季节性趋势和销售模式,就哪些商品需要备货、如何管理库存以及哪些商品需要优先供应做出明智的决策。.
对于零售企业来说,优化商品种类对于在以下两方面取得平衡至关重要 品种 和 效率. .提供的选择太少可能会赶走顾客,而提供的选择太多又会导致混乱、库存过剩和利润率降低。优化产品种类有助于企业提高客户满意度,既能确保畅销产品的供应,又能淘汰占用宝贵货架空间的性能不佳产品。.
选择建模 选择建模是一种有效的分类优化方法,因为它提供了一个 data-driven 框架来了解客户偏好并预测他们将如何在不同产品之间做出选择。通过分析价格敏感度、产品特点和品牌忠诚度等各种因素,选择建模可以帮助零售商确定哪些产品最有可能满足顾客需求。.
最终,选择建模使零售商能够提供正确的产品组合,为特定客户群量身定制商品种类,还能优化货架空间,提高盈利能力,甚至为商品定价。.
如果您从未听说过选择建模,您可以阅读 我们的文章 通过实例介绍了关键概念。在本文中,我们将主要关注如何利用离散选择模型来优化各种产品。我们将提供基于 选择-学习 库,旨在帮助 data 科学家解决此类使用案例。.
提供的代码使用了 choice-learn Python 软件包,可在笔记本中找到 这里.
设置:安装 Python 和 Choice-Learn
在本文中,我们将提供代码片段来配合解释。代码使用 选择-学习 库,它为选择建模和多种应用(如分类优化或价格)提供了高效工具。Choice-Learn 可通过 PyPI 获取,只需使用
dataset : 销售收据
我们将使用 TaFeng 杂货 dataset。您可以从 Kaggle 并在 Python 环境中用 choice-learn 打开它:
print(tafeng_df.head())

dataset 包含 800,000 多笔在一家中国杂货店的个人消费。每次购买都提供了各种详细信息,包括购买的商品(PRODUCT_ID)、销售价格(SALES_PRICE)和顾客的年龄组(AGE_GROUP)。.
我们可以看到,零售商提供的商品种类繁多,其中一些很少出售。为了简化物流,零售商可能会选择减少所提供产品的数量。在这种情况下,我们的目标是找出最佳的销售商品子集。.
为此,我们将重点放在最畅销的商品上,因为它们更有可能被再次购买,并将在打造更高效、更有利可图的商品种类方面发挥至关重要的作用。. 请注意,我们这样做主要是为了简化示例,所有项目都可以保留。.
tafeng_df = tafeng_df.loc[
tafeng_df.PRODUCT_ID.isin(tafeng_df.PRODUCT_ID.value_counts().index[:20])
].reset_index(drop=正确)
tafeng_df = tafeng_df.loc[
tafeng_df.AGE_GROUP.isin([“25-29”, “40-44”, “45-49”, “>65”, “30-34”, “35-39”, “50-54”, “55-59”, “60-64”] )
].reset_index(drop=正确)
我们还可以用每十年一个热点值对年龄类别进行编码:
tafeng_df[“二十年代”] = tafeng_df.apply(羔羊 行: 1 如果 行[“年龄组”] == “25-29” 不然 0, ,轴=1)
tafeng_df[“三十岁”] = tafeng_df.apply(
羔羊 行: 1 如果 行[“年龄组”] 于 ([“30-34”, “35-39”]) 不然 0, ,轴=1
)
tafeng_df[“四十岁”] = tafeng_df.apply(
羔羊 行: 1 如果 行[“年龄组”] 于 ([“40-44”, “45-49”]) 不然 0, ,轴=1
)
tafeng_df[“五十年代”] = tafeng_df.apply(
羔羊 行: 1 如果 行[“年龄组”] 于 ([“50-54”, “55-59”]) 不然 0, ,轴=1
)
tafeng_df[“六十年代及以上”] = tafeng_df.apply(
羔羊 行: 1 如果 行[“年龄组”] 于 ([“60-64”, “>65”]) 不然 0, ,轴=1
)
现在我们的 data 已经准备就绪,我们需要创建一个 ChoiceDataset, 中的 data 处理程序对象。 选择-学习. .这就需要指定描述购买背景的特征:
- 客户特征 (共同特征):年龄类别
- 产品特点 (物品特征):物品价格
选择建模的一个重要方面是,我们需要了解 购买时的所有可用物品, 而不仅仅是所选的一种。这样我们就可以分析不同产品的价格如何影响顾客的决定。由于 dataset 中没有直接提供这些信息,因此我们假设每次购买时,其他商品的价格与上次销售时相同。.
id_to_index =
对于 i, product_id 于 罗列(np.sort(tafeng_df.PRODUCT_ID.unique()):
id_too_index[product_id] = i
# 初始化项目价格
价格 = [[0] 对于 _ 于 范围(宽id_to_index))] (id_to_index)) 对于 k, v 于 id_to_index.items():
价格[v][0] = tafeng_df.loc[tafeng_df.PRODUCT_ID == k].SALES_PRICE.to_numpy()[0] # 创建构成 Choice 的数组Dataset
shared_features = [] items_features = [] 选择 = [] # 每购买一件商品,我们就能节省开支:
# - 客户的年龄代表(单声道
# - 所有已售物品的价格
对于 i,行 于 tafeng_df.iterrows():
item_index = id_to_index[row.PRODUCT_ID]。 prices[item_index][0] = row.SALES_PRICE
shared_features.append(
行[["二十年代", "三十岁", "四十岁", "五十年代", "六十年代及以上"]].to_numpy()
)
items_features.append(prices)
choices.append(item_index)
现在我们已经掌握了所有信息,我们可以 创建 ChoiceDataset:
dataset = ChoiceDataset(
shared_features_by_choice=shared_features、,
shared_features_by_choice_names=[‘二十年代’, ‘三十年代’, ‘四十岁’, ‘五十年代’, ‘六十年代及以上’],
items_features_by_choice=items_features、,
items_features_by_choice_names=[“销售价格”],
选择=选择
)
定义和估计选择模型
我们将建立并估算一个选择模型,预测顾客从所有同类产品中选择特定商品的概率。根据现有的 dataset,我们为一件商品定义了以下效用函数 i 客户考虑 j:
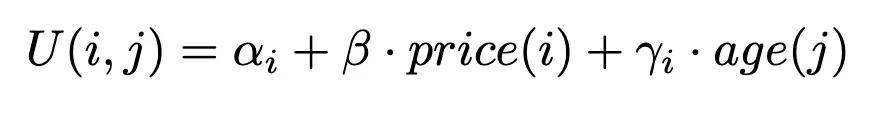
该函数表示顾客从选择特定商品中获得的效用(或满意度),受顾客年龄和商品价格的影响。.
有关我们如何制定效用函数的更多细节,请参阅我们的第一版 邮寄. .需要注意的是,另一种合乎逻辑的模式--但为了简单起见没有提出--可以是对每个 年龄组别的价格敏感性进行估算。.
下面是使用选择学习估算模型的代码:
model.add_coefficients(
coefficient_name=age_category, feature_name=age_category, items_indexes=清单(范围(20))
)
系数名称=“价格”, feature_name=“销售价格”, items_indexes=清单(范围(20))
)
您可以检查模型是否与 dataset 完全吻合:
plt.plot(hist[“train_loss”])
plt.xlabel(“纪元”)
plt.ylabel(“负对数似然法”)
plt.show(
寻找最佳品种
有了购买概率,我们现在就可以估算出一个品种的每位顾客的平均收入了 A 使用公式
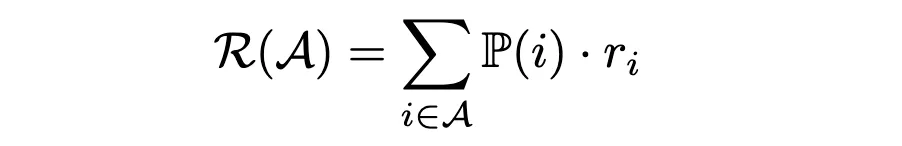
为了找到收益最大的品种,我们可以评估所有可能的组合,然后选择平均收益最高的一种。然而,更有效的方法是使用 线性规划(LP). .在这里,我们将重点介绍如何使用 选择-学习 实施分类优化器。.
重要的是要区分收入最大化和利润率最大化。收入固然重要,但利润率要考虑到每件产品的相关成本。根据您的目标,您可能希望优化利润而不是纯收入。.
要优化产品种类,我们需要提供几个关键输入:
- 我们希望赋予每个年龄组的权重,让我们来看看他们的客户份额吧
- 每个年龄组的每个项目的效用(由我们的选择模型计算得出
- 每个项目的优化值(在本例中为收入)
- 品种的数量(例如 12 件)
下面介绍如何使用 选择-学习:
从 选择_学习.工具箱.分类优化器 舶来品 潜在分类优化器
# 每个项目的价格
future_prices = np.stack([items_features[-1]]*5, ,轴=0)
age_category = np.eye(5).astype("float32")
# 根据价格和每个年龄段计算每个物品的效用
predicted_utilities = model.compute_batch_utility(shared_features_by_choice=age_category、
items_features_by_choice=future_prices、
available_items_by_choice=np.ones((5, 20)),
选择=无
)
age_category_weights = np.数额(共享特征,轴=0) / 宽(shared_features)
opt = LatentClassAssortmentOptimizer(
求解器="或工具", # 要使用的求解器,可以是 "or-tools "或 "gurobi"(如果您有许可证)。
class_weights=age_category_weights、, # 各级重量
class_utilities=np.exp(predicted_utilities)、, # 型实用程序(n_类,n_项)
itemwise_values=future_prices[0][:, 0], # 每个项目的优化值,这里是用于计算营业额的价格
分类尺寸=12) # 我们想要的品种规格
assortment, opt_obj = opt.solve()
运行代码后,您应该会得到类似的结果:
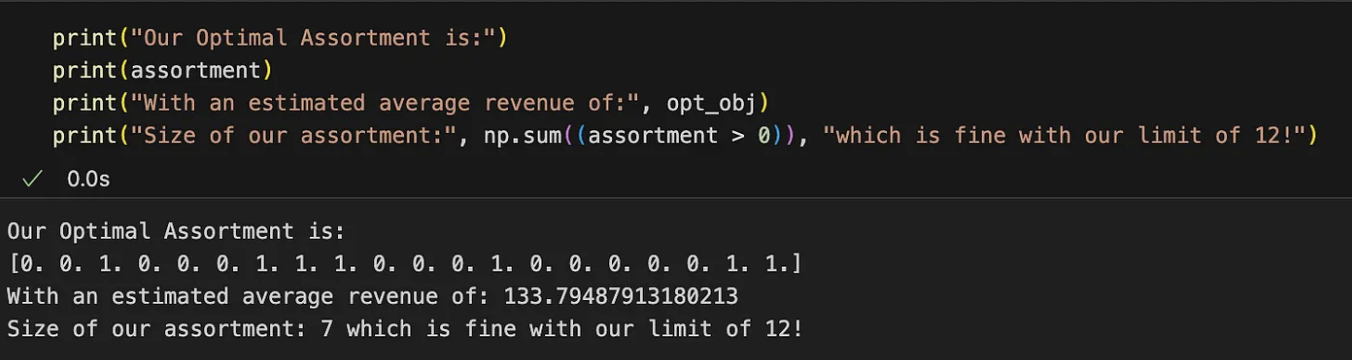
用向量中 1 值的索引表示收入最大化的最佳组合。从理论上讲,这种组合可以为每位顾客带来 134 元的平均收入。您可以探索其他组合,但它们都会降低平均收入。.
另一个目标可能是销售数量最大化。在这种情况下,所有项目的优化项目值都设为 1,从而产生不同的最佳分类。.
当引入额外的限制条件时,这种方法的效率就显而易见了。例如,您可能需要考虑商店货架空间的限制。在这种情况下,你可以优化商品种类,使其总尺寸不超过可用的货架空间。这种额外的约束条件,以及定价策略等其他约束条件,都可以通过以下方法得到验证 这里.
结论
如果您正在进行分类优化或定价工作,选择建模是一个很好的工具,一定要好好研究一下。Choice-Learn 提供了许多很酷的示例。 GitHub. .去看看吧,如果觉得有用,就给它打颗星吧!

