


ACTUALITÉS / TECHNOLOGIE DE L'AI
25 novembre 2020
Dans cet article, Kasra Mansouri et Camille Le Gonidec, scientifiques principaux de Artefact, expliquent comment créer un produit scientifique data avec des contraintes commerciales élevées et un nombre limité de data. Découvrez comment ils ont pu réduire les ruptures de stock dans les hypermarchés grâce à la modélisation des séries temporelles.
Énoncé du problème
Nous avons tous ressenti cette frustration du dimanche matin lorsque nous ne trouvons pas nos céréales ou notre soda préférés dans les rayons de notre magasin local. En effet, les ruptures de stock dans les rayons sont une source de douleur majeure pour les magasins de détail : ce n'est pas seulement une opportunité de vente perdue, mais aussi une baisse de la satisfaction des clients, qui seront plus enclins à changer de magasin.
Deux phénomènes sont principalement à l'origine de la rupture de stock d'un rayon :
- Le magasin ne dispose pas du produit en question, c'est-à-dire que même l'entrepôt du magasin est vide de ce produit. Cela peut être dû à une sous-estimation de la demande du client ou à des problèmes logistiques.
- Le magasin a le produit en stock mais l'étagère est vide. Les rayons sont généralement remplis tous les matins, mais aucun employé n'a pour tâche spécifique de s'occuper du stock pendant la journée. Repérer une rupture de stock en passant devant l'étagère peut être viable pour les petits magasins, mais devient un problème pour les hypermarchés compte tenu de leur taille. Certains rayons restent vides (alors que le niveau des stocks est positif) jusqu'à ce qu'un employé les repère ou jusqu'à la mise en rayon du lendemain matin.
Nous allons aborder ici ce deuxième type de ruptures de stock puisque notre objectif était d'aider les employés d'un hypermarché à repérer les ruptures de stock en rayon au cours de la journée afin qu'ils puissent les corriger et recommencer à vendre le produit. Nous avons passé beaucoup de temps sur le terrain pour comprendre les problèmes de nos utilisateurs et concevoir la meilleure solution pour y répondre.
Nous avons découvert que la meilleure option pour les équipes opérationnelles serait de recevoir une alerte quotidienne vers 14 heures (pas besoin de temps réel), avec une liste d'articles en rupture de stock qu'elles devraient aller corriger.
Mais Comment repérer les ruptures de stock sans indice visuel ?? En effet, l'installation de caméras ou de capteurs visuels serait trop coûteuse et nous ne pouvons pas demander à notre personnel d'aller “vérifier” l'état des étagères tous les jours pour collecter data. Notre principale difficulté réside dans le fait qu'il y a pas d'historique data disponible en rayon ruptures de stock (la seule information dont nous disposons est le niveau global des stocks à la fin de la journée), nous ne pouvons donc nous appuyer que sur un ensemble restreint de caractéristiques : les ventes en temps réel, les attributs des articles et les caractéristiques du magasin.
Approches proposées
Comme expliqué ci-dessus, la principale difficulté à laquelle nous avons été confrontés était l'absence de data étiqueté pour les ruptures de stock en rayon, ce qui nous a empêchés d'adopter l'approche ML initiale que nous avions à l'esprit. Nous avons donc envisagé une autre approche pour construire notre modèle de détection.
Prédiction des séries temporelles des ventes horaires
Notre première approche alternative consistait à détecter les anomalies de vente (ventes anormalement basses) en prévoir les ventes horaires de produits et les comparer aux ventes réelles.
L'idée sous-jacente est d'estimer/prédire la quantité de ventes régulières que nous attendons d'un produit lorsqu'il n'y a pas d“”anomalies“ dans le magasin, puis de les comparer à ses ventes réelles et d'émettre une alerte si la différence est ”énorme". Ainsi, en appliquant notre modèle tous les jours à 14 heures, nous pourrions prédire les ventes de chaque produit jusqu'à 14 heures, puis détecter les anomalies en comparant les ventes réelles de chaque produit à nos estimations.
Comme point de départ, nous avons développé un Modèle de moyenne mobile. Pour chaque heure, le modèle établit ses prévisions en prenant la moyenne des ventes du produit à la même heure au cours des 30 derniers jours. Nous comparons ensuite cette valeur aux ventes réelles du produit pendant cette heure. Si l'inégalité suivante est vérifiée, nous lançons une alerte de rupture de stock.
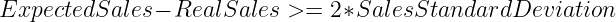
Cette approche est basée sur l'hypothèse que les ventes horaires des produits suivent une courbe d'évolution. Distribution normale et vise à alerter sur les produits situés en dehors du 95% de l'intervalle de confiance.
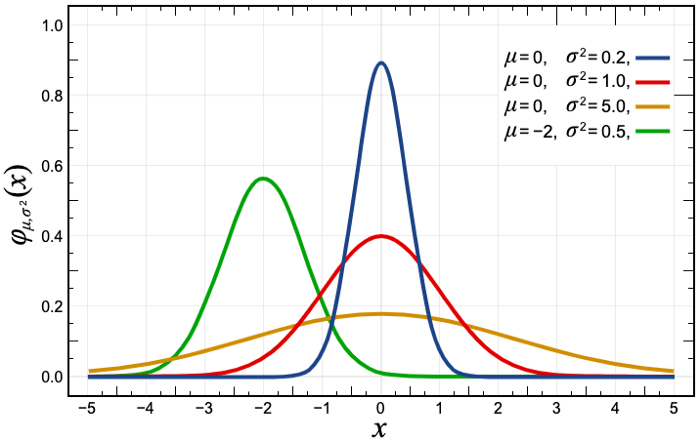
Et ce n'est pas du tout le cas ! En fait, nous avons très peu de signaux de séries temporelles si nous examinons les ventes horaires dans un magasin, et ce simplement parce que la majorité des produits ont des ventes nulles pendant plusieurs heures au cours de la journée, de sorte que le modèle prévoirait une valeur proche de 0 (en prenant la moyenne des valeurs passées) pour l'heure donnée. Par conséquent, la modélisation des ventes horaires n'est clairement pas la bonne solution.
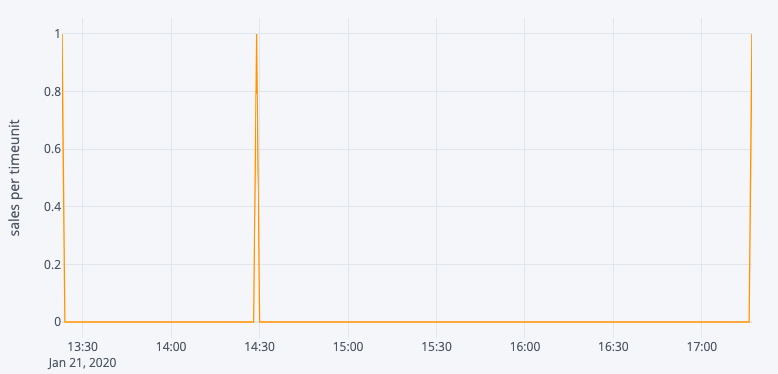
Nous avons essayé de modifier légèrement notre approche en prédisant ventes quotidiennes quantité Cette approche aurait probablement fonctionné pour les produits à forte rotation comme les sodas Coca-Cola, les bouteilles d'eau, etc. Cette approche aurait probablement fonctionné pour les produits à forte rotation comme les sodas Coca-Cola, les bouteilles d'eau, etc. mais notre solution devait fonctionner pour tous les produits d'un hypermarché, c'est pourquoi nous avons progressivement abandonné cette approche.
Détection d'anomalies à l'aide de la distribution de Poisson
Notre deuxième approche a consisté à essayer modéliser la fréquence des ventes (et non la quantité), c'est-à-dire le temps écoulé entre 2 ventes consécutives d'un même produit.
Nous avons effectué des tests statistiques sur les ventes de certains produits data et nous avons réalisé que le temps écoulé entre leurs deux ventes consécutives suit une distribution exponentielle, ce qui est intuitivement logique puisqu'une distribution exponentielle est généralement utilisée pour modéliser le temps écoulé entre les différentes occurrences d'un événement.
La conséquence logique est que nous peut modéliser le «taux de vente» d'un produit par une distribution de Poisson. Par taux de vente, nous entendons le nombre de passages en caisse d'un produit au cours d'une heure, indépendamment de la quantité vendue.
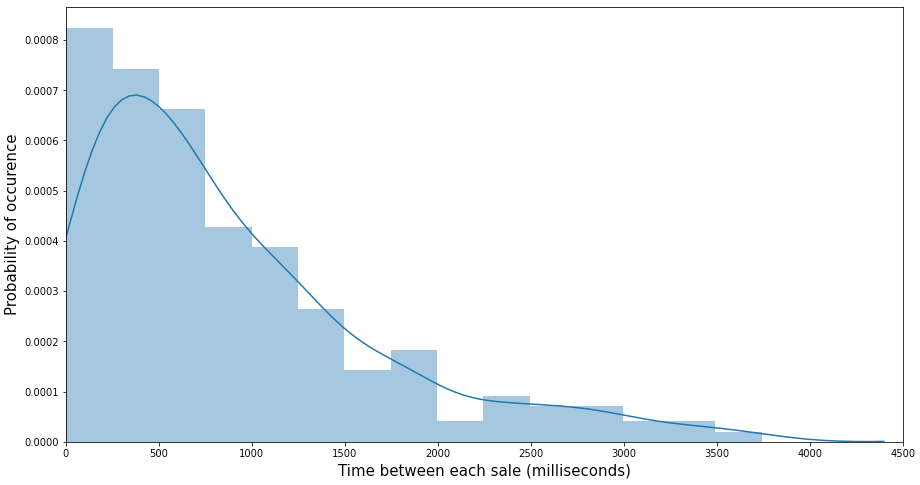
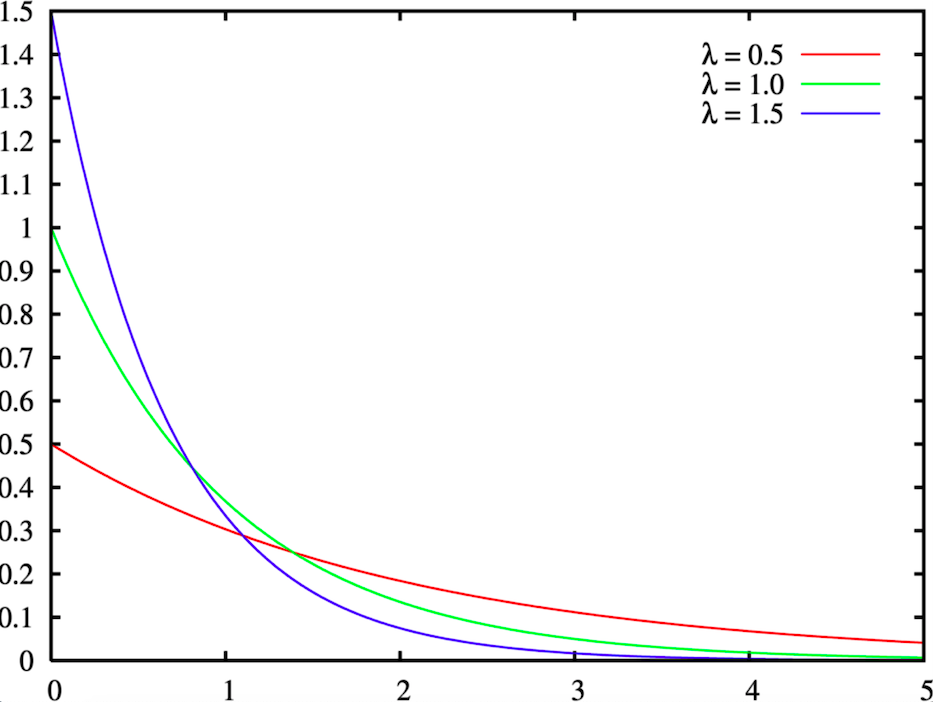
Par conséquent, notre deuxième approche alternative consiste à estimer le taux de vente régulier de chaque produit, qui est le taux de vente régulier de chaque produit, qui est le taux de vente régulier de chaque produit. lambda paramètre de la distribution de Poisson, puis comparez ce résultat à ses ventes quotidiennes réelles jusqu'à 14 heures.
Il s'agit d'une procédure en deux étapes :
Calcul de la lambda: Au sein du lambda est la moyenne de la distribution de Poisson. Ainsi, pour l'estimer, nous devons calculer la moyenne de nos points data passés, c'est-à-dire le nombre moyen de passages en caisse par heure que le produit a eu dans le passé. Nous avons pris une profondeur historique de 50 jours pour notre calcul afin de conserver les informations du passé proche. En outre, nous calculons la lambda pour chaque jour de la semaine séparément, car il existe une forte saisonnalité hebdomadaire dans les ventes de produits dans un hypermarché.
Concrètement, nous rassemblons les ventes data d'un produit au cours des 50 derniers jours, nous calculons son taux de vente pour chaque jour et nous calculons ensuite le taux de vente moyen pour chaque jour de la semaine ; notre calcul donne donc 7 lambda un pour chaque jour de la semaine. Ce calcul est effectué chaque semaine.
Détection des anomalies : Chaque jour à 14 heures, nous recherchons la dernière vente du produit. Nous calculons ensuite la probabilité (fonction de masse de probabilité de Poisson) de n'avoir aucune vente entre la dernière vente et 14 heures, compte tenu des données suivantes lambda paramètre. Si la probabilité est inférieure à 1%, nous considérons que le produit a un taux de vente anormalement bas.
Imaginons par exemple un soda Coca-Cola qui se vend régulièrement toutes les 20 minutes, et qui a donc une durée de vie de lambda=Nous calculons la fonction de masse de probabilité de Poisson d'avoir 0 vente pendant 3 heures sachant que le produit est vendu régulièrement 3 fois par heure.
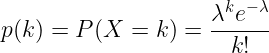
Résultats
Nous avons effectué des tests préliminaires sur notre modèle de Poisson en essayant de mesurer sa capacité à estimer les ventes à 14 heures. Le modèle a été capable d'estimer le nombre de caisses de produits avec une précision de 67%. Ce résultat a confirmé notre intuition selon laquelle un modèle de Poisson pourrait être l'outil adéquat pour détecter avec précision les pénuries de produits. Nous avons donc décidé de tester notre modèle sur le terrain.
Nous nous sommes rendus dans deux magasins tous les deux jours pour tester et évaluer la précision des alertes de notre modèle sur 3000 produits que les magasins ont identifiés comme prioritaires. Une alerte était considérée comme précise si le rayon était vide ou avait moins de 10% de sa capacité moyenne à l'heure même de l'envoi de l'alerte. Cette phase d'évaluation a duré 2,5 mois et s'est traduite par une mesure de taux de précision de 58% (c'est-à-dire que 58% des alertes de rupture de stock de notre modèle étaient exactes).
Même si la précision du 58% n'est pas très brillante, il faut comprendre que cette solution est très simple à mettre en œuvre (il vous suffit d'avoir accès à l'historique des ventes data et aux ventes data en temps quasi réel dans les magasins) et peut s'adapter facilement à tous les magasins pour réduire les risques de rupture de stock.
Vous pouvez mettre en œuvre cette solution pour chaque magasin dans moins d'une semaine et obtenez directement la précision 58-60% ! Gardez à l'esprit qu'un un modèle de classification aléatoire aurait une précision de près de 5% car en général, il y a environ 5% de produits en rupture de stock dans les rayons.
De plus, cette solution pourrait faire partie d'un un produit plus grand qui augmente toutes sortes d'alertes avec une boucle de rétroaction. Les alertes qui correspondent à des ruptures de stock amèneront les employés du magasin à prendre des mesures et à réapprovisionner les rayons, tandis que les alertes qui ne correspondent pas à des ruptures de stock pourront être utilisées pour une analyse plus approfondie afin de comprendre pourquoi le produit a eu un volume de ventes anormalement faible. On pourrait également envisager de construire un modèle d'apprentissage automatique qui classerait les alertes comme des ruptures de stock ou autres, puisque nous commencerons à collecter des données étiquetées data.

