


NIEUWS / AI TECHNOLOGIE
25 november 2020
In dit artikel leggen Artefact's Senior Data Scientists Kasra Mansouri en Camille Le Gonidec uit hoe ze een data wetenschappelijk product konden maken met beperkte data en hoge bedrijfsbeperkingen. Ontdek hoe ze productvoorraden in hypermarkten konden terugdringen met behulp van Time Series modellering.
Probleemstelling
We hebben allemaal wel eens die zondagochtendfrustratie gevoeld wanneer we onze favoriete ontbijtgranen of frisdrank niet in het schap van onze plaatselijke winkel konden vinden. Inderdaad, schapvoorraden zijn een groot pijnpunt voor winkels: het is niet alleen een gemiste verkoopkans, maar ook een daling van de klanttevredenheid, die eerder geneigd zal zijn om van winkel te veranderen.
Er zijn twee fenomenen die er voornamelijk voor zorgen dat een schap zonder voorraad komt te zitten:
- De winkel heeft het product niet, d.w.z. zelfs het magazijn is leeg. Dit kan worden veroorzaakt door een onderschatte vraag van de klant of door logistieke problemen.
- De winkel heeft het product op voorraad, maar het schap is leeg. De schappen worden meestal elke ochtend gevuld, maar er is geen werknemer die als specifieke taak heeft om overdag voor de voorraad te zorgen. Het signaleren van een tekort door langs het schap te lopen kan voor kleine winkels vol te houden zijn, maar wordt een probleem voor hypermarkten gezien hun omvang. Sommige schappen blijven leeg (terwijl het voorraadniveau positief is) totdat een werknemer het ziet of totdat de volgende ochtend de schappen worden aangevuld.
Dit tweede type van stock-outs gaan we hier aanpakken, omdat het ons doel was om de medewerkers van een hypermarkt te helpen om de stock-outs in de schappen gedurende de dag op te sporen, zodat ze deze konden corrigeren en het product opnieuw konden verkopen. We hebben veel tijd in het veld doorgebracht om de pijnpunten van onze gebruikers te begrijpen en de beste oplossing te ontwerpen om deze te beantwoorden.
We ontdekten dat de beste optie voor operationele teams zou zijn om dagelijks rond 14:00 uur een waarschuwing te ontvangen (real-time is niet nodig), met een lijst van artikelen die niet op voorraad zijn en die ze moeten corrigeren.
Maar Hoe kunnen we voorraadtekorten in schappen herkennen zonder visuele aanwijzing?? Het installeren van camera's of visuele sensoren zou inderdaad te duur zijn en we kunnen ons personeel niet vragen om elke dag de status van de schappen te “gaan controleren” om data te verzamelen. Onze grootste uitdaging ligt in het feit dat er geen historische data beschikbaar op plank stock-outs (de enige informatie die we hebben is het globale voorraadniveau aan het einde van de dag), daarom kunnen we alleen vertrouwen op een beperkte set kenmerken: Verkoop in realtime, artikelkenmerken en winkelkenmerken.
Voorgestelde benaderingen
Zoals hierboven uitgelegd, was de grootste uitdaging de afwezigheid van gelabelde data voor schapvoorraden, waardoor we de oorspronkelijke ML-benadering die we in gedachten hadden niet konden toepassen. Daarom hebben we een alternatieve aanpak overwogen om ons detectiemodel op te bouwen.
Tijdreeksvoorspelling van verkoop per uur
Onze eerste alternatieve aanpak bestond uit onregelmatigheden in de verkoop (ongewoon lage verkoop) detecteren door per uur de verkoop van producten voorspellen en deze vervolgens vergelijken met de werkelijke verkoop.
Het idee hierachter is om de reguliere verkoophoeveelheid die we van een product verwachten te schatten/voorspellen als er geen “afwijkingen” in de winkel zijn, deze vervolgens te vergelijken met de werkelijke verkoop en een waarschuwing te geven als het verschil “groot” is. Door ons model elke dag om 14.00 uur toe te passen, zouden we dus de verkoop van elk product tot 14.00 uur voorspellen en vervolgens afwijkingen detecteren door de werkelijke verkoop van elk product met onze schattingen te vergelijken.
Als uitgangspunt hebben we een eenvoudige Bewegend gemiddelde model. Voor elk uur maakt het model zijn voorspellingen door een gemiddelde te nemen van de verkoop van het product op hetzelfde uur gedurende de afgelopen 30 dagen. Vervolgens vergelijken we deze waarde met de werkelijke verkoop van het product tijdens dat uur. Als de volgende ongelijkheid wordt geverifieerd, geven we een waarschuwing als het product niet op voorraad is.
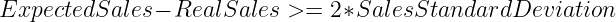
Deze benadering is gebaseerd op de aanname dat de verkoop per uur van de producten een Normale verdeling en is bedoeld om producten buiten het 95% van het betrouwbaarheidsinterval te waarschuwen.
En dat is helemaal niet het geval! In feite hebben we heel weinig tijdreekssignalen als we kijken naar de verkoop per uur in een winkel, en dat komt gewoon omdat de meeste producten gedurende meerdere uren van de dag geen verkoop hebben, zodat het model een waarde zou voorspellen die dicht bij 0 ligt (door het gemiddelde te nemen van de waarden uit het verleden) voor het gegeven uur. Daarom is het modelleren van de verkoop per uur duidelijk niet de juiste manier.
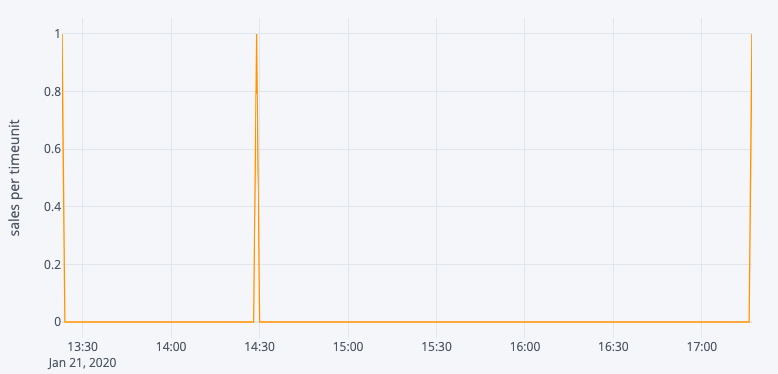
We hebben geprobeerd om onze aanpak enigszins aan te passen door te voorspellen dagelijkse verkoop hoeveelheid tot 14.00 uur, maar we zouden nog steeds veel producten hebben waarvoor we niet genoeg signaal hadden, we noemen ze «producten met een lage rotatie». Deze aanpak zou waarschijnlijk hebben gewerkt voor producten met een hoge rotatie, zoals Coca-Cola frisdrank, waterflessen, enz. maar onze oplossing moest werken voor alle producten in een hypermarkt, daarom hebben we deze aanpak geleidelijk aan afgeschaft.
Detectie van afwijkingen met behulp van Poisson-verdeling
Onze tweede benadering was om te proberen de verkoopfrequentie modelleren (en niet de hoeveelheid), d.w.z. de verstreken tijd tussen 2 opeenvolgende verkopen van één product.
We voerden statistische tests uit op de verkoop van sommige producten data en realiseerden ons dat de tijd tussen hun twee opeenvolgende verkopen een exponentiële verdeling volgt, wat intuïtief logisch is omdat een exponentiële verdeling gewoonlijk wordt gebruikt om de tijd tussen verschillende gebeurtenissen te modelleren.
Het logische gevolg hiervan is dat wij kan de «verkoopsnelheid» van een product modelleren met een Poisson-verdeling. Met verkoopsnelheid bedoelen we het aantal keren dat een product tijdens een uur door de kassa gaat, ongeacht de hoeveelheid die verkocht is.
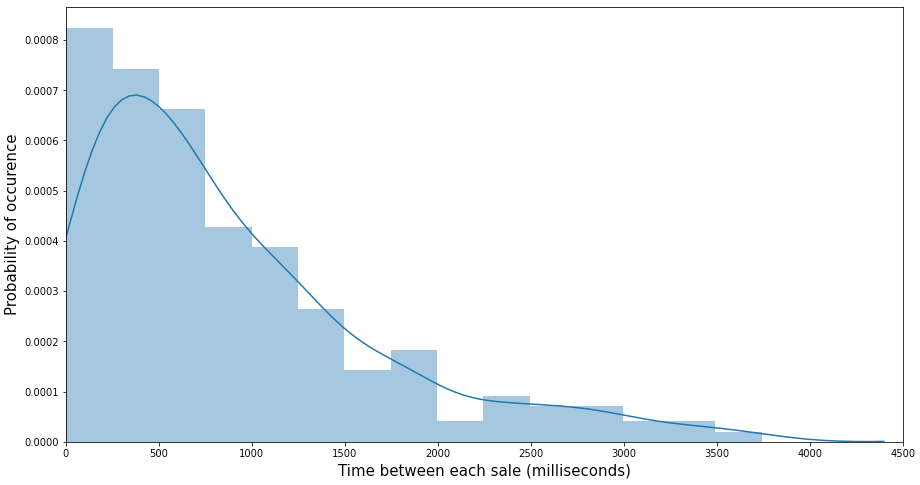
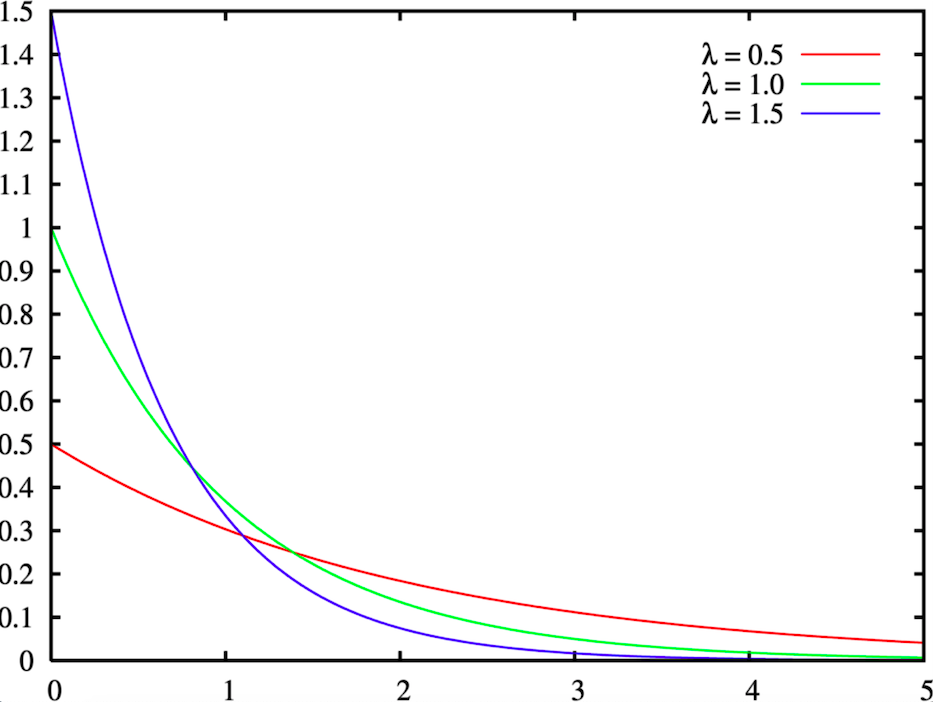
Daarom is onze tweede alternatieve benadering het schatten van de reguliere verkoop van elk product, wat de lambda parameter van de Poisson verdeling, en vergelijk dat vervolgens met de werkelijke dagelijkse verkoop tot 14.00 uur.
Dit is een proces in 2 stappen:
Het berekenen van de lambda: De lambda is het gemiddelde van de Poisson-verdeling. Om het te schatten, moeten we dus het gemiddelde van onze afgelopen data punten berekenen, d.w.z. het gemiddelde aantal checkouts per uur dat het product in het verleden heeft gehad. We hebben een historische diepte van 50 dagen genomen voor onze berekening om informatie uit het nabije verleden te bewaren. Verder berekenen we de lambda voor elke weekdag afzonderlijk, omdat er een sterke wekelijkse seizoensgebondenheid is in de productverkoop in een hypermarkt.
Concreet verzamelen we de verkoopcijfers data van een product van de afgelopen 50 dagen, berekenen we de verkoopcijfers op elke dag en berekenen we vervolgens de gemiddelde verkoopcijfers voor elke weekdag, dus onze berekening levert 7 lambda getallen, één voor elke weekdag. Deze berekening wordt elke week uitgevoerd.
Anomaliedetectie: Elke dag om 14.00 uur zoeken we de laatste keer dat het product verkocht is. Vervolgens berekenen we de kans (Poisson waarschijnlijkheidsmassafunctie) dat er geen verkoop is tussen de laatste verkoop en 14.00 uur, gegeven de lambda parameter. Als de waarschijnlijkheid lager is dan 1%, dan gaan we ervan uit dat het product een ongewoon lage verkoop heeft.
Stel u bijvoorbeeld een Coca-Cola frisdrank voor die regelmatig om de 20 minuten wordt verkocht, en daarom een lambda=3, en dat vandaag de laatste verkoop om 11 uur 's ochtends was. We berekenen de kansmassafunctie van Poisson op 0 verkopen gedurende 3 uur, wetende dat het product regelmatig 3 keer per uur verkocht wordt.
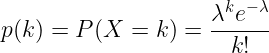
Resultaten
We voerden voorafgaande tests uit op ons Poisson-model door te proberen te meten hoe goed het de verkoop om 14.00 uur kon schatten. Het model kon het aantal productuitgiftes schatten met een nauwkeurigheid van 67%. Dit resultaat bevestigde onze intuïtie dat een Poisson-model het juiste hulpmiddel zou kunnen zijn om producttekorten nauwkeurig op te sporen. Daarom besloten we ons model in de praktijk te testen.
We gingen om de twee dagen naar twee winkels om de nauwkeurigheid van de waarschuwingen van ons model te testen en te evalueren voor 3000 producten die de winkels als topprioriteit hadden aangemerkt. Een waarschuwing werd als nauwkeurig beschouwd als het schap leeg was of minder dan 10% van zijn gemiddelde capaciteit had op hetzelfde uur als wanneer de waarschuwing werd verzonden. Deze evaluatiefase duurde 2,5 maand en resulteerde in een gemeten nauwkeurigheidspercentage van 58% (d.w.z. 58% van de voorraadwaarschuwingen van ons model waren nauwkeurig).
Hoewel de precisie van de 58% misschien niet glanst, moet u begrijpen dat deze oplossing zeer eenvoudig te implementeren (wat u alleen nodig hebt is toegang tot historische verkoop data en bijna real-time verkoop data in winkels) en kan gemakkelijk geschaald kan worden naar alle winkels om de risico's van schapuitval te beperken.
U kunt deze oplossing implementeren voor elke winkel in minder dan een week en ontvang direct 58-60% precisie! Houd er rekening mee dat een willekeurig classificatiemodel zou bijna een 5% precisie hebben aangezien er over het algemeen ongeveer 5% aan producten niet op voorraad zijn in de schappen.
Deze oplossing kan ook deel uitmaken van een groter product dat allerlei waarschuwingen met een feedbacklus. De waarschuwingen die stock-outs zijn, zullen ertoe leiden dat het winkelpersoneel actie onderneemt en de schappen bijvult, en de waarschuwingen die dat niet zijn, kunnen gebruikt worden voor verdere analyse om te begrijpen waarom het product een ongewoon laag verkoopvolume had. U kunt ook denken aan het bouwen van een Machine Learning-model dat waarschuwingen classificeert als schapvoorraden of anders, aangezien we beginnen met het verzamelen van gelabelde data.

