


新闻 / 人工智能技术
2020 年 11 月 25 日
在本文中,Artefact 的高级 Data 科学家 Kasra Mansouri 和 Camille Le Gonidec 介绍了如何在有限的 data 和较高的业务限制条件下创建 data 科学产品。了解他们如何利用时间序列建模减少大卖场的产品缺货。.
问题陈述
我们都曾在周日早晨感到沮丧,因为在当地商店的货架上找不到自己喜欢的麦片或苏打水。事实上,货架缺货是零售商店的一大痛点:这不仅会丧失销售机会,还会降低顾客满意度,使他们更有可能更换商店。.
导致货架缺货的主要现象有两种:.....:
- 商店没有指定的产品,即甚至连商店仓库都没有该产品。造成这种情况的原因可能是低估了客户需求,也可能是物流问题。.
- 店里有存货,但货架是空的。货架通常每天早上都会被填满,但没有员工专门负责白天的存货管理。通过货架发现缺货对于小商店来说是可以持续的,但对于大型超市来说,考虑到其规模,这就成了一个问题。有些货架最终是空的(库存水平是正的),直到员工发现或第二天早上上架。.
我们在这里要解决的是第二种缺货情况,因为我们的目标是帮助大型超市的员工在白天发现货架上的缺货情况,以便及时纠正并重新开始销售产品。我们在现场花费了大量时间来了解用户的痛点,并设计出最佳解决方案来解决这些问题。.
我们发现,对于操作团队来说,最好的选择是每天下午 2:00 左右收到提醒(无需实时提醒),并附有他们应该去纠正的过时文章清单。.
但是 如何在没有任何视觉线索的情况下发现货架缺货?事实上,安装摄像头或视觉传感器的成本太高,而且我们也不能要求我们的员工每天都去 “检查 ”货架的状态,以收取 data 的费用。我们面临的主要挑战在于 货架上无历史 data 库存 (我们所掌握的唯一信息是一天结束时的全球库存水平),因此我们只能依靠一套有限的功能: 实时销售额、商品属性和商店特征.
建议的方法
如上所述,我们面临的主要挑战是没有用于货架缺货的标记 data,这使我们无法采用最初设想的 ML 方法。因此,我们考虑采用另一种方法来建立检测模型。.
每小时销售额的时间序列预测
我们的第一种替代方法包括 通过以下方法检测销售异常(异常低的销售额 预测产品的每小时销售量,然后与实际销售量进行比较.
这背后的想法是,在商店没有 “异常 ”的情况下,估计/预测我们预期的产品正常销售量,然后将其与实际销售量进行比较,如果差异 “巨大”,则发出警报。因此,通过每天下午 2 点应用我们的模型,我们可以预测每个产品在下午 2 点之前的销售量,然后通过比较每个产品的实际销售量和我们的估计值来检测异常情况。.
作为起点,我们开发了一个简单的 移动平均模型. .对于每个小时,该模型将通过计算过去 30 天内同一小时的产品平均销售额来进行预测。然后,我们会将这一数值与该小时内该产品的实际销售额进行比较,如果验证了以下不等式,我们就会发出缺货警报。.
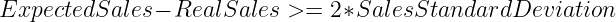
这种方法基于这样一个假设,即产品的每小时销售额遵循 正态分布 并旨在对置信区间 95% 以外的产品提高警惕。.
但事实并非如此!事实上,如果我们观察一家商店每小时的销售情况,就会发现时间序列信号非常小,这只是因为大多数产品在一天中的几个小时内都没有销售,因此模型会预测特定小时内接近于 0 的值(取过去值的平均值)。因此,建立每小时销售额模型显然不是正确的方法。.
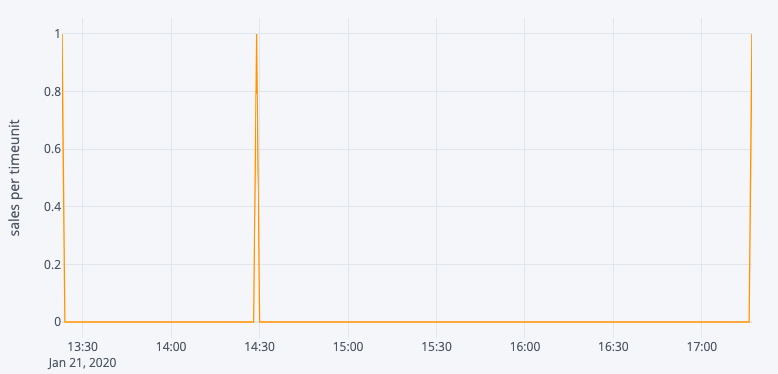
我们试图略微修改我们的方法,预测 日销售额 数量 但仍有许多产品没有足够的信号,我们称之为 «低轮换产品»。这种方法可能适用于可口可乐汽水、水瓶等高轮换率产品,但我们的解决方案需要适用于大卖场的所有产品,因此我们逐步淘汰了这种方法。.
利用泊松分布进行异常检测
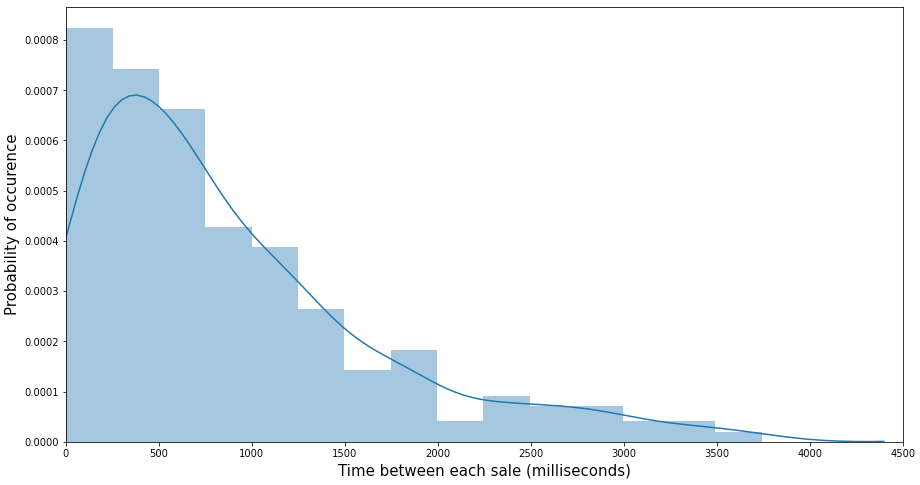
我们的第二种方法是尝试 模拟销售频率(而不是数量), 即单一产品连续两次销售之间的间隔时间。.
我们对某些产品的销售额 data 进行了统计检验,发现其连续两次销售之间的时间呈指数分布,这直观上是合理的,因为指数分布通常用于模拟事件不同发生之间的时间间隔。.
其逻辑结果是 我们 可以用泊松分布来模拟产品的 «销售率»。. 我们所说的销售率是指在一小时内,无论销售数量多少,产品通过收银台的次数。.
因此,我们的第二种替代方法是估算每种产品的正常销售率,即 羔羊 泊松分布的参数,然后将其与下午 2 点之前的实际日销售额进行比较。.
这是一个分两步走的过程:
计算 羔羊: "(《世界人权宣言》) 羔羊 是泊松分布的均值。因此,要估算它,我们需要计算过去 data 点的平均值,即该产品过去每小时的平均结账次数。我们以 50 天为历史深度进行计算,以保留近期的信息。此外,我们还计算了 羔羊 因为大卖场的产品销售每周都有很强的季节性,所以每个工作日都要分别计算。.
具体来说,我们收集某产品过去 50 天的销售额 data,计算出其每天的销售率,然后计算出每个工作日的平均销售率,因此我们的计算结果为 7. 羔羊 数字,每个工作日一个。每周进行一次计算。.
异常检测 每天下午 2 点,我们都要查找该产品的最后一次销售时间。然后,我们计算从最后一次销售到下午 2 点之间没有销售的概率(泊松概率质量函数),给定的概率为 羔羊 参数。如果概率低于 1%,我们就认为该产品的销售率异常低。.
例如,让我们想象一下,可口可乐汽水每 20 分钟就会售出一瓶,因此它的 羔羊=已知该产品每小时固定售出 3 次,我们计算泊松概率质量函数,即 3 小时内销售量为 0 的概率质量函数。.
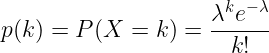
成果
我们对泊松模型进行了初步测试,试图衡量该模型对下午 2 点销售额的估算能力。该模型对产品结账数量的估算准确率为 67%. .这一结果证实了我们的直觉,即泊松模型可能是准确检测产品短缺的正确工具。因此,我们决定实地测试我们的模型。.
我们每两天去两家商店,测试和评估我们的模型对商店确定为最优先的 3000 种产品发出警报的准确性。如果在发出警报的同一小时,货架是空的或平均容量少于 10%,警报就被认为是准确的。这一评估阶段持续了 2.5 个月,结果如下 精确率为 58%(即 58% 的模型缺货警报是准确的).
虽然 58% 的精度可能并不高,但要知道,这种解决方案是 非常简单 (您只需要访问历史销售 data 和几乎实时的商店销售 data),并可以 易于扩展到所有商店 以减少货架缺货风险。.
您可以在 不到一周 并直接获得 58-60% 的精度!请注意 随机分类模型的精确度接近 5% 因为一般来说,货架上缺货的产品大约有 5%。.
此外,该解决方案还可以成为 更大的产品,提高 各种带有反馈回路的警报. .缺货警报将促使商店员工采取行动,重新补充货架,而非缺货警报则可用于进一步分析,以了解产品销售量异常低的原因。我们还可以考虑建立一个机器学习模型,将警报分类为货架缺货或其他,因为我们将开始收集 data 标签。.


