


NOTICIAS / TECNOLOGÍA AI
25 de noviembre de 2020
En este artículo, las científicas sénior Artefact Kasra Mansouri y Camille Le Gonidec explican cómo crear un producto científico data con limitaciones data y grandes restricciones comerciales. Descubra cómo consiguieron reducir las roturas de stock de productos en los hipermercados gracias a la modelización de series temporales.
Planteamiento del problema
Todos hemos sentido alguna vez esa frustración del domingo por la mañana cuando no encontramos nuestro cereal o refresco favorito en el estante de nuestra tienda local. De hecho, el agotamiento de las existencias en los estantes es un importante punto de dolor para las tiendas minoristas: no sólo supone una oportunidad perdida de ventas, sino también un descenso de la satisfacción del cliente, que será más propenso a cambiar de tienda.
Dos fenómenos provocan principalmente que una estantería se quede sin existencias :
- La tienda no tiene el producto dado, es decir, incluso el almacén de la tienda está vacío del producto. Esto puede deberse a una subestimación de la demanda de los clientes o a problemas logísticos.
- La tienda tiene el producto en stock pero la estantería está vacía. Las estanterías suelen llenarse cada mañana pero no hay ningún empleado cuya tarea específica sea ocuparse de sus existencias durante el día. Detectar una falta de existencias pasando por delante de la estantería puede ser sostenible para las tiendas pequeñas, pero se convierte en un problema para los hipermercados teniendo en cuenta su tamaño. Algunos estantes acaban vacíos (mientras el nivel de inventario es positivo) hasta que un empleado lo detecta o hasta que se hace el siguiente estante por la mañana.
Vamos a abordar aquí este segundo tipo de roturas de stock, ya que nuestro objetivo era ayudar a los empleados de un hipermercado a detectar las roturas de stock en las estanterías durante el día para que pudieran corregirlas y reanudar la venta del producto. Pasamos mucho tiempo sobre el terreno para comprender los puntos débiles de nuestros usuarios y diseñar la mejor solución para darles respuesta.
Descubrimos que la mejor opción para los equipos operativos sería recibir una alerta diaria en torno a las 14:00 horas (sin necesidad de tiempo real), con una lista de artículos fuera de stock que deberían ir a corregir.
Pero ¿cómo podemos detectar la falta de existencias en las estanterías sin ninguna pista visual?? Efectivamente, la instalación de cámaras o sensores visuales sería demasiado costosa y no podemos pedir a nuestro personal que “vaya a comprobar” el estado de las estanterías todos los días para recoger data. Nuestro mayor reto reside en el hecho de que hay no histórico data disponible en stock-outs (la única información que tenemos es el nivel global de existencias al final del día), por lo que sólo podemos basarnos en un conjunto restringido de características: ventas en tiempo real, atributos de los artículos y características de la tienda.
Enfoques propuestos
Como ya se ha explicado, el principal reto al que nos enfrentamos fue la ausencia de data etiquetado para las existencias de los estantes, lo que nos impidió adoptar el enfoque ML inicial que teníamos en mente. Por lo tanto, consideramos un enfoque alternativo para construir nuestro modelo de detección.
Predicción de series temporales de ventas por hora
Nuestro primer enfoque alternativo consistió en detectar anomalías en las ventas (ventas inusualmente bajas) mediante predecir las ventas horarias de productos y compararlas después con las reales.
La idea subyacente es estimar/predecir la cantidad de ventas regulares que esperamos que tenga un producto cuando no hay “anomalías” en la tienda, luego compararlas con sus ventas reales y lanzar una alerta si la diferencia es “enorme”. Así, aplicando nuestro modelo todos los días a las 14.00 horas, predeciríamos las ventas de cada producto hasta las 14.00 horas y luego detectaríamos las anomalías comparando las ventas reales de cada producto con nuestras estimaciones.
Como punto de partida, desarrollamos un sencillo Modelo de media móvil. Para cada hora, el modelo realizaría sus predicciones tomando una media de las ventas del producto en esa misma hora durante los últimos 30 días. A continuación compararíamos este valor con las ventas reales del producto durante esa hora, si se verifica la siguiente desigualdad entonces lanzaríamos una alerta de falta de existencias.
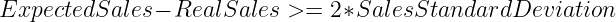
Este enfoque se basa en la suposición de que las ventas horarias de los productos siguen un Distribución normal y pretende alertar sobre los productos que se encuentran fuera del 95% del intervalo de confianza.
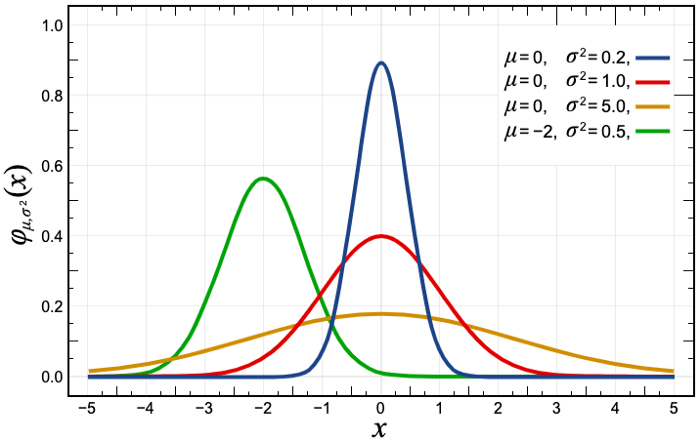
¡Y no es el caso en absoluto! De hecho, tenemos muy poca señal de la serie temporal si nos fijamos en las ventas por horas en una tienda y eso es simplemente porque la mayoría de los productos tienen 0 ventas durante varias horas al día, por lo que el modelo predeciría un valor cercano a 0 (tomando la media de los valores pasados) para la hora dada. Por lo tanto, modelizar las ventas por horas no es claramente el camino correcto.
Intentamos modificar ligeramente nuestro enfoque prediciendo ventas diarias cantidad hasta las 2.p.m pero seguiríamos teniendo muchos productos para los que no teníamos suficiente señal, los llamamos «productos de baja rotación». Este enfoque probablemente habría funcionado con productos de alta rotación como los refrescos de Coca-Cola, las botellas de agua, etc. pero nuestra solución debía funcionar con todos los productos de un hipermercado, por lo que eliminamos gradualmente este enfoque.
Detección de anomalías mediante la distribución de Poisson
Nuestro segundo enfoque fue intentar modelizar la frecuencia de las ventas (y no la cantidad), Es decir, el tiempo transcurrido entre 2 ventas consecutivas de un mismo producto.
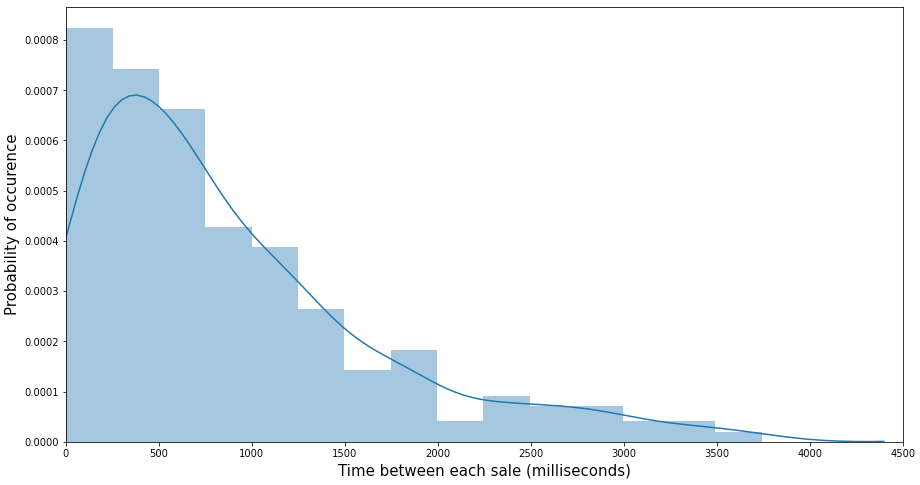
Realizamos pruebas estadísticas sobre las ventas de algunos productos data y nos dimos cuenta de que el tiempo transcurrido entre sus dos ventas consecutivas sigue una distribución exponencial, lo que intuitivamente tiene sentido, ya que una distribución exponencial suele utilizarse para modelizar el tiempo transcurrido entre diferentes sucesos de un acontecimiento.
La consecuencia lógica de esto es que nosotros puede modelizar la «tasa de ventas» de un producto con una distribución de Poisson. Por índice de ventas entendemos el número de veces que un producto pasa por caja durante una hora, independientemente de la cantidad que se haya vendido.
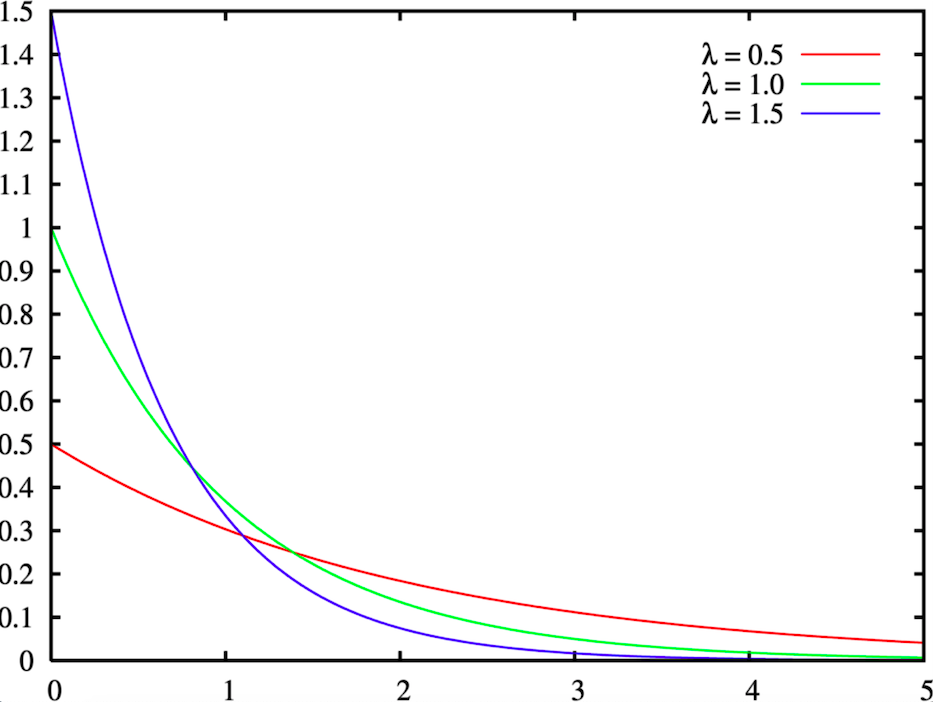
Por lo tanto, nuestro segundo enfoque alternativo consiste en estimar el índice de ventas regulares de cada producto, que es el lambda parámetro de la distribución de Poisson, y luego compararlo con sus ventas diarias reales hasta las 2.p.m.
Se trata de un proceso de dos pasos:
Cálculo del lambda: El lambda es la media de la distribución de Poisson. Por lo tanto, para estimarla, necesitamos calcular la media de nuestros puntos data pasados, es decir, el número medio de salidas por hora que ha tenido el producto en el pasado. Tomamos una profundidad histórica de 50 días para nuestro cálculo con el fin de conservar la información del pasado cercano. Además, calculamos la lambda para cada día de la semana por separado porque existe una fuerte estacionalidad semanal en las ventas de productos en un hipermercado.
Concretamente, reunimos las ventas data de un producto de los últimos 50 días, calculamos su tasa de ventas en cada día y luego calculamos la tasa media de ventas para cada día de la semana, por lo que nuestro cálculo arroja 7 lambda números, uno para cada día de la semana. Este cálculo se realiza cada semana.
Detección de anomalías: Cada día, a las 14.00 horas, buscamos la última vez que se vendió el producto. A continuación, calculamos la probabilidad (función de masa de probabilidad de Poisson) de no tener ninguna venta entre la última venta y las 2.p.m, dada la lambda parámetro. Si la probabilidad es inferior a 1%, consideramos que el producto tiene un índice de ventas inusualmente bajo.
Por ejemplo, imaginemos un refresco de Coca-Cola que se vende regularmente cada 20 minutos, por lo que tiene una lambda=3, y que hoy su última venta fue a las 11 a.m. Calculamos la función de masa de probabilidad de Poisson de tener 0 ventas durante 3 horas sabiendo que el producto se vende regularmente 3 veces por hora.
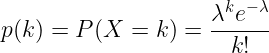
Resultados
Realizamos pruebas preliminares con nuestro modelo de Poisson intentando medir lo bien que podía estimar las ventas a las 2 de la tarde. El modelo fue capaz de estimar el número de salidas de productos con una precisión de 67%. Este resultado confirmó nuestra intuición de que un modelo de Poisson podría ser la herramienta adecuada para detectar con precisión la escasez de productos. Por lo tanto, decidimos probar nuestro modelo sobre el terreno.
Acudimos a dos tiendas cada dos días para probar y evaluar la precisión de las alertas de nuestro modelo sobre 3000 productos que las tiendas identificaron como prioritarios. Una alerta se consideraría precisa si la estantería estaba vacía o tenía menos de 10% de su capacidad media a la misma hora en que se envió la alerta. Esta fase de evaluación duró 2,5 meses y dio como resultado una medida índice de precisión de 58% (es decir, 58% de las alertas de falta de existencias de nuestro modelo fueron precisas).
Aunque la precisión del 58% no sea brillante lo que hay que entender es que esta solución es muy sencillo de aplicar (lo único que necesita es tener acceso a las ventas históricas data y a las ventas casi en tiempo real data en las tiendas) y puede ampliarse fácilmente a todas las tiendas para reducir los riesgos de ruptura de existencias.
Puede aplicar esta solución a cada tienda en menos de una semana ¡y obtenga directamente la precisión 58-60%! Tenga en cuenta que un modelo de clasificación aleatorio tendría casi una precisión de 5% ya que en general hay aproximadamente 5% de productos que se agotan en las estanterías.
Además, esta solución podría formar parte de un producto más grande que eleve todo tipo de alertas con un bucle de retroalimentación. Las alertas que sean de agotamiento de existencias llevarán a los empleados de la tienda a tomar medidas y reponer los estantes, y las que no lo sean podrían utilizarse para un análisis más profundo con el fin de comprender por qué el producto ha tenido un volumen de ventas inusualmente bajo. También se podría pensar en construir un modelo de aprendizaje automático que clasifique las alertas como agotados en las estanterías o no, ya que empezaremos a recopilar data etiquetados.

