


NACHRICHTEN / KI-TECHNOLOGIE
25. November 2020
In diesem Artikel erläutern die Artefact Senior Data Scientists Kasra Mansouri und Camille Le Gonidec, wie man ein data wissenschaftliches Produkt mit begrenzten data und hohen geschäftlichen Einschränkungen entwickelt. Finden Sie heraus, wie sie mit Hilfe von Zeitreihenmodellen die Produktausfälle in Hypermärkten reduzieren konnten.
Problemstellung
Wir alle kennen die Enttäuschung am Sonntagmorgen, wenn wir unser Lieblingsmüsli oder unsere Lieblingslimonade nicht im Regal unseres örtlichen Geschäfts finden. In der Tat sind Regalfehlbestände ein großer Schmerzpunkt für Einzelhandelsgeschäfte: Sie bedeuten nicht nur eine verlorene Umsatzchance, sondern auch einen Rückgang der Kundenzufriedenheit, die dann eher das Geschäft wechseln.
Es sind vor allem zwei Phänomene, die dazu führen, dass ein Regal nicht mehr lieferbar ist:
- Das Geschäft hat das betreffende Produkt nicht vorrätig, d.h. selbst im Lager des Geschäfts ist das Produkt nicht vorrätig. Dies kann entweder auf eine unterschätzte Kundennachfrage oder auf logistische Probleme zurückzuführen sein.
- Der Laden hat das Produkt auf Lager, aber das Regal ist leer. Die Regale werden in der Regel jeden Morgen aufgefüllt, aber es gibt keinen Angestellten, dessen spezielle Aufgabe es ist, sich tagsüber um den Bestand zu kümmern. Einen Mangel im Vorbeigehen am Regal zu bemerken, kann für kleine Geschäfte tragbar sein, wird aber für Hypermärkte angesichts ihrer Größe zu einem Problem. Einige Regale bleiben leer (auch wenn der Bestand positiv ist), bis ein Angestellter den Mangel entdeckt oder bis zum nächsten Morgen die Regale aufgefüllt werden.
Wir befassen uns hier mit der zweiten Art von Fehlbeständen, denn unser Ziel war es, den Mitarbeitern eines Verbrauchermarktes dabei zu helfen, Fehlbestände in den Regalen zu erkennen, damit sie diese korrigieren und den Verkauf der Produkte wieder aufnehmen können. Wir haben viel Zeit vor Ort verbracht, um die Probleme unserer Benutzer zu verstehen und die beste Lösung für sie zu entwickeln.
Wir haben herausgefunden, dass die beste Option für die operativen Teams darin besteht, täglich gegen 14:00 Uhr eine Benachrichtigung zu erhalten (keine Notwendigkeit für Echtzeit), mit einer Liste von Artikeln, die nicht im Regal stehen und die sie korrigieren sollten.
Aber Wie können wir Regalfehlbestände ohne visuelle Anhaltspunkte erkennen?? Die Installation von Kameras oder visuellen Sensoren wäre in der Tat zu kostspielig, und wir können von unseren Mitarbeitern nicht verlangen, dass sie jeden Tag den Status der Regale “überprüfen”, um data zu sammeln. Unsere größte Herausforderung liegt in der Tatsache, dass es keine historischen data auf Lager verfügbar (die einzige Information, die wir haben, ist der globale Lagerbestand am Ende des Tages), daher können wir uns nur auf eine begrenzte Anzahl von Funktionen verlassen: Echtzeit-Verkäufe, Artikelattribute und Merkmale des Geschäfts.
Vorgeschlagene Ansätze
Wie oben erläutert, bestand die größte Herausforderung darin, dass es keine markierten data für die Regalbestände gab, was uns daran hinderte, den ursprünglich angedachten ML-Ansatz zu verwenden. Daher haben wir einen alternativen Ansatz zur Erstellung unseres Erkennungsmodells in Betracht gezogen.
Zeitreihenvorhersage der stündlichen Verkäufe
Unser erster alternativer Ansatz bestand aus Erkennen von Umsatzanomalien (ungewöhnlich niedrige Umsätze) durch Vorhersage der stündlichen Verkäufe von Produkten und anschließender Vergleich mit den tatsächlichen Verkäufen.
Die Idee dahinter ist, die reguläre Verkaufsmenge, die wir für ein Produkt erwarten, wenn es keine “Anomalien” im Geschäft gibt, zu schätzen/vorhersagen, sie dann mit den tatsächlichen Verkäufen zu vergleichen und einen Alarm auszulösen, wenn der Unterschied “groß” ist. Wenn wir also unser Modell jeden Tag um 14.00 Uhr anwenden, würden wir die Verkäufe jedes Produkts bis 14.00 Uhr vorhersagen und dann Anomalien erkennen, indem wir die tatsächlichen Verkäufe jedes Produkts mit unseren Schätzungen vergleichen.
Als Ausgangspunkt haben wir ein einfaches Modell des gleitenden Durchschnitts. Für jede Stunde würde das Modell seine Vorhersagen treffen, indem es den Durchschnitt der Verkäufe des Produkts in der gleichen Stunde in den letzten 30 Tagen ermittelt. Wir würden dann diesen Wert mit den tatsächlichen Verkäufen des Produkts in dieser Stunde vergleichen. Wenn sich die folgende Ungleichheit bestätigt, würden wir eine Warnung auslösen, dass das Produkt nicht auf Lager ist.
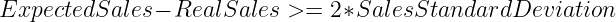
Dieser Ansatz basiert auf der Annahme, dass die stündlichen Verkäufe der Produkte einem Normalverteilung und zielt darauf ab, auf Produkte außerhalb des 95% des Konfidenzintervalls aufmerksam zu machen.
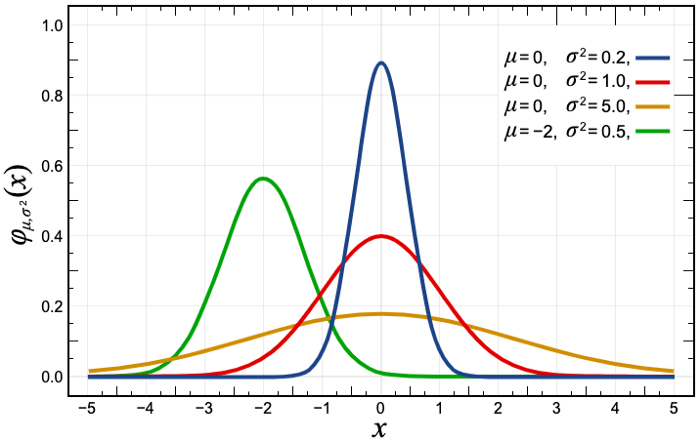
Und das ist ganz und gar nicht der Fall! Wenn wir uns die stündlichen Verkäufe in einem Geschäft ansehen, erhalten wir nur ein sehr geringes Zeitreihensignal. Das liegt ganz einfach daran, dass die meisten Produkte mehrere Stunden am Tag keine Verkäufe aufweisen, so dass das Modell für die jeweilige Stunde einen Wert nahe 0 vorhersagen würde (indem es den Durchschnitt der vergangenen Werte nimmt). Daher ist die Modellierung der stündlichen Verkäufe eindeutig nicht der richtige Weg.
Wir haben versucht, unseren Ansatz leicht zu modifizieren, indem wir vorhersagen Tagesumsatz Menge bis 14.00 Uhr, aber wir hätten immer noch viele Produkte, für die wir nicht genug Signal haben, wir nennen sie «Produkte mit niedriger Rotation». Dieser Ansatz hätte wahrscheinlich bei Produkten mit hoher Rotation wie Coca-Cola Limonaden, Wasserflaschen usw. funktioniert, aber unsere Lösung musste bei allen Produkten in einem Verbrauchermarkt funktionieren, deshalb haben wir diesen Ansatz eingestellt.
Erkennung von Anomalien mit Hilfe der Poisson-Verteilung
Unser zweiter Ansatz war, zu versuchen Modellierung der Häufigkeit der Verkäufe (und nicht der Menge), d.h. die verstrichene Zeit zwischen 2 aufeinanderfolgenden Verkäufen eines einzelnen Produkts.
Wir haben statistische Tests zu den Verkäufen einiger Produkte data durchgeführt und festgestellt, dass die Zeit zwischen zwei aufeinanderfolgenden Verkäufen einer Exponentialverteilung folgt, was intuitiv Sinn macht, da eine Exponentialverteilung normalerweise zur Modellierung der Zeit zwischen verschiedenen Ereignissen verwendet wird.
Die logische Konsequenz daraus ist, dass wir kann die «Verkaufsrate» eines Produkts mit einer Poisson-Verteilung modellieren. Unter Verkaufsrate verstehen wir die Anzahl der Durchläufe eines Produkts an der Kasse während einer Stunde, unabhängig von der verkauften Menge.
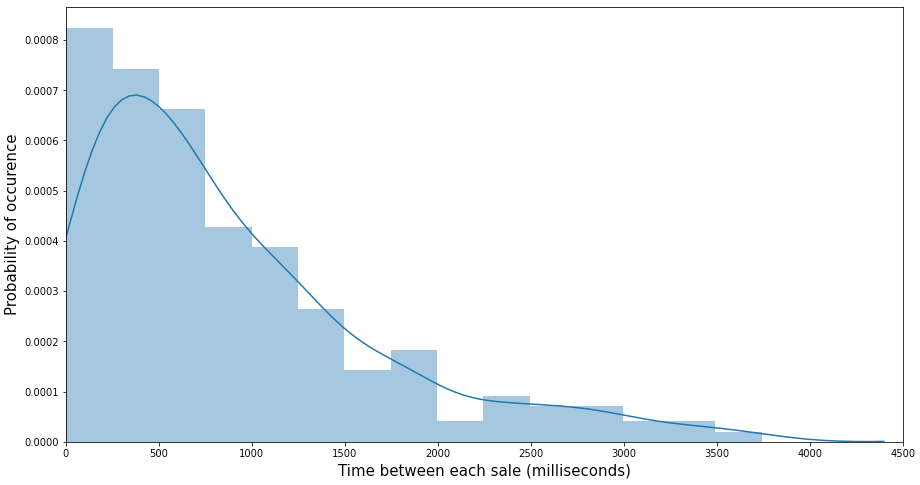
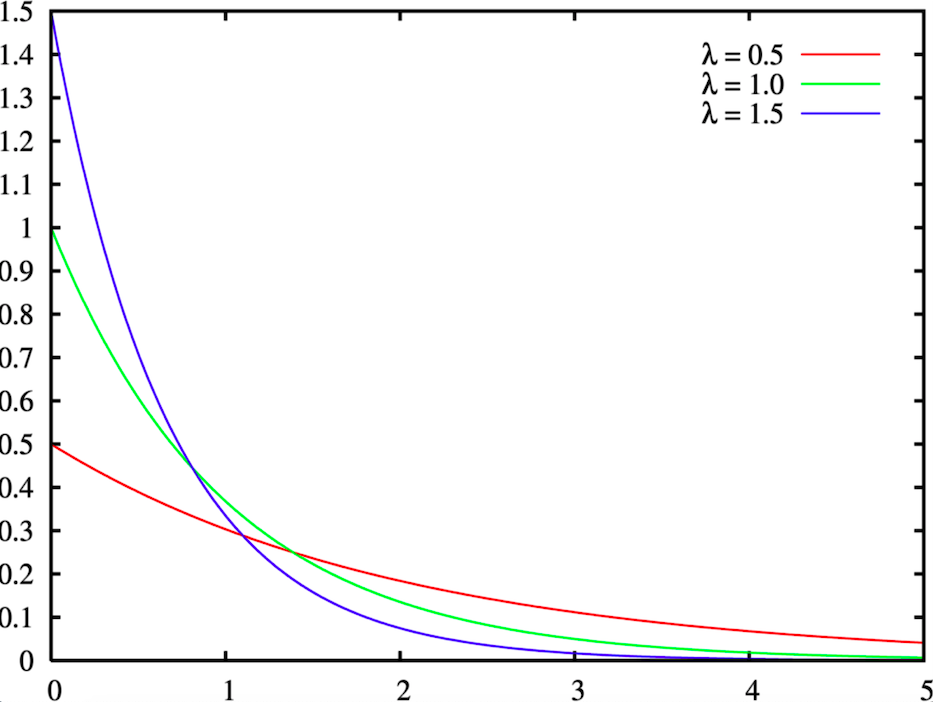
Daher besteht unser zweiter alternativer Ansatz darin, die reguläre Verkaufsrate für jedes Produkt zu schätzen, d.h. die lambda Parameter der Poisson-Verteilung, und vergleichen Sie dies dann mit den realen täglichen Verkäufen bis 14.00 Uhr.
Dies ist ein 2-stufiger Prozess:
Berechnen Sie die lambda: Die lambda ist der Mittelwert der Poisson-Verteilung. Um ihn zu schätzen, müssen wir also den Mittelwert unserer vergangenen data-Punkte berechnen, d.h. die durchschnittliche Anzahl der Kassen pro Stunde, die das Produkt in der Vergangenheit hatte. Wir haben für unsere Berechnung eine historische Tiefe von 50 Tagen gewählt, um Informationen aus der nahen Vergangenheit zu erhalten. Außerdem berechnen wir die lambda für jeden Wochentag separat, da es eine starke wöchentliche Saisonalität bei den Produktverkäufen in einem Verbrauchermarkt gibt.
Konkret sammeln wir die Verkäufe data eines Produkts aus den letzten 50 Tagen, berechnen seine Verkaufsrate an jedem Tag und berechnen dann die durchschnittliche Verkaufsrate für jeden Wochentag, daher ergibt unsere Berechnung 7 lambda Zahlen, eine für jeden Wochentag. Diese Berechnung wird jede Woche durchgeführt.
Erkennung von Anomalien: Jeden Tag um 14.00 Uhr suchen wir nach dem letzten Verkauf des Produkts. Dann berechnen wir die Wahrscheinlichkeit (Poisson-Wahrscheinlichkeitsmassenfunktion), dass zwischen dem letzten Verkauf und 14 Uhr keine Verkäufe stattgefunden haben, wenn die lambda Parameter. Wenn die Wahrscheinlichkeit unter 1% liegt, dann gehen wir davon aus, dass das Produkt eine ungewöhnlich niedrige Verkaufsrate hat.
Stellen wir uns zum Beispiel eine Coca-Cola Limonade vor, die regelmäßig alle 20 Minuten verkauft wird und daher einen lambda=3, und dass der letzte Verkauf heute um 11 Uhr stattfand. Wir berechnen die Poissonsche Wahrscheinlichkeitsfunktion für 0 Verkäufe in 3 Stunden, da wir wissen, dass das Produkt regelmäßig 3 Mal pro Stunde verkauft wird.
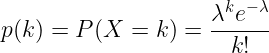
Ergebnisse
Wir haben erste Tests mit unserem Poisson-Modell durchgeführt, um zu ermitteln, wie gut es die Verkäufe um 14 Uhr schätzen kann. Das Modell war in der Lage, die Anzahl der Produktkäufe mit einer Genauigkeit von 67%. Dieses Ergebnis bestätigte unsere Intuition, dass ein Poisson-Modell das richtige Werkzeug sein könnte, um Produktknappheit genau zu erkennen. Deshalb haben wir beschlossen, unser Modell in der Praxis zu testen.
Wir waren alle zwei Tage in zwei Geschäften, um die Genauigkeit der Warnungen unseres Modells bei 3000 Produkten zu testen und zu bewerten, die von den Geschäften als besonders wichtig eingestuft wurden. Eine Warnung würde als genau gelten, wenn das Regal zur gleichen Stunde, in der die Warnung gesendet wurde, leer war oder weniger als 10% seiner durchschnittlichen Kapazität hatte. Diese Evaluierungsphase dauerte 2,5 Monate und führte zu einer gemessenen Präzisionsrate von 58% (d.h. 58% der Stockout-Warnungen unseres Modells waren korrekt).
Auch wenn die Präzision des 58% nicht gerade glänzt, sollten Sie wissen, dass diese Lösung sehr einfach zu implementieren (Sie benötigen lediglich Zugriff auf die historischen Verkäufe data und die Verkäufe data in den Geschäften fast in Echtzeit) und können leicht auf alle Filialen skaliert werden um das Risiko von Regalfehlbeständen zu reduzieren.
Sie können diese Lösung für jedes Geschäft in weniger als eine Woche und erhalten Sie direkt 58-60% Präzision! Denken Sie daran, dass ein ein zufälliges Klassifizierungsmodell hätte eine Genauigkeit von fast 5% da in der Regel etwa 5% der Produkte in den Regalen vergriffen sind.
Außerdem könnte diese Lösung Teil eines größeres Produkt, das die alle Arten von Alarmen mit einer Feedback-Schleife. Die Warnungen, bei denen es sich um Fehlbestände handelt, werden dazu führen, dass die Mitarbeiter des Ladens Maßnahmen ergreifen und die Regale wieder auffüllen. Die Warnungen, bei denen es sich nicht um Fehlbestände handelt, könnten für weitere Analysen verwendet werden, um zu verstehen, warum das Produkt einen ungewöhnlich niedrigen Umsatz hatte. Man könnte auch darüber nachdenken, ein Modell für maschinelles Lernen zu entwickeln, das die Warnungen als Fehlbestände im Regal klassifiziert oder nicht, da wir damit beginnen werden, gekennzeichnete data zu sammeln.

