

Auteur

Auteur


Deze gids zal u helpen erachter te komen of Prophet geschikt is voor uw prognoseproject, door u een kritisch oordeel te geven op basis van een echte projectlens. We hebben het getest op 3 hoofddimensies: feature engineering en modellering, interpreteerbaarheid en onderhoud.
We hebben Prophet getest in een echt project, op 3 hoofdaspecten: feature engineering, interpreteerbaarheid en gebruik in productie en onderhoud, en dit zijn onze conclusies:
Feature engineering en modellering:
Interpretabiliteit:
Stabiliteit van de resultaten / Onderhoud:
Inleiding
Onlangs, een artikel wees erop dat Facebook Profeet slecht presteerde op sommige randgevallen. Dit pakket is zelfs zo populair dat het wordt beschouwd als HET hulpmiddel voor elke prognose use case. Dit leidde tot een debat binnen de gemeenschap en zelfs de maker reageerde.
Er is veel literatuur over het maken van een enkelvoudige voorspelling met Prophet. Maar er is een gebrek aan empirische feedback over hoe het zich gedraagt in de productie, wanneer u dagelijks voorspellingen moet doen. Wij hebben deze tool 6 maanden lang getest en bewezen op een echt bedrijfsproject. Hier volgen een aantal vaststellingen.
We hebben Prophet gebruikt om voorspellingen te doen over binnenkomende gesprekken in callcenters voor een van de grootste telecombedrijven in Europa, om de kwaliteit van de klantenservice te optimaliseren.
We hebben de GLADS kader om onze data aanpak op te stellen:
Een belangrijke beperking was de behoefte aan interpreteerbaarheid van resultaten. Onze voorspellingen worden namelijk gebruikt door menselijke planners wiens doel het is om een SLA (X% aan oproepen moet worden beantwoord in een bepaalde periode) te handhaven en tegelijkertijd de kosten te minimaliseren. Hun werk bestaat uit 3 missies:
Hoofd oproepchauffeurs verschillen afhankelijk van SKU's. Commerciële assistentiedrivers zijn bijvoorbeeld:
Onze tijdreeksen zijn sterk seizoensgebonden en volgen economische cycli. Ze zijn niet stationair. In dit geval is Prophet een geschikte keuze. We hebben ervoor gekozen om het te testen, evenals andere ML-algoritmen vaak gebruikt voor deze taak.
Feature-engineering en modellering
Prophet heeft vele onmiskenbare voordelen die bijzonder nuttig zijn voor een zakelijk prognoseproject, en die zijn populariteit volledig rechtvaardigen.
Eén daarvan is de gebruiksgemak. Slechts een paar regels code en bijna geen feature engineering nodig zijn om een goede basislijn te hebben. Lees voor meer informatie over hoe het werkt en hoe u het kunt gebruiken deze Twitter-draad van de maker, evenals deze uitstekende blogpost (met code).
Tijdskenmerken, zoals trend en seizoensgebondenheid worden op een natuurlijke manier aangemaakt - zonder de voortschrijdende gemiddelden, vertragingen en andere lastige kenmerken die nodig zijn voor boomgebaseerde modellen op basis van machine learning (ML).
Het kan echter een heel gedoe zijn om af te stellen als meerdere gebeurtenissen het signaal verstoren.
Trend
Een groot voordeel ten opzichte van autoregressieve modellen (bijv. ARIMA) is dat Prophet vereist geen stationaire tijdreeksen: een trendcomponent wordt direct gegenereerd.
Om deze redenen heeft Profeet werkt vrij goed voor voorspellingen op middellange termijn (we hebben het geprobeerd bij M+5 horizon), ook al is het betrouwbaarheidsinterval vrij groot.
Trend kan correct worden geschat zonder externe data (zoals het aantal klanten). Dit is vrij krachtig, want als u binnenkomende gesprekken voorspelt, weet u niet hoeveel klanten u over 5 maanden zult hebben, dus u kunt deze functie niet gebruiken.
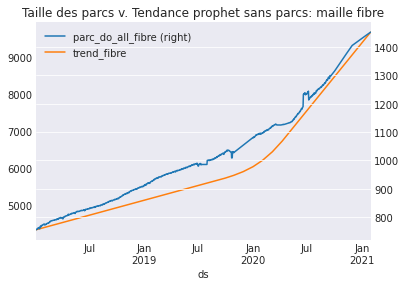
Deze grafiek toont bijvoorbeeld het aantal Fiber-Optic Internet (FIO)-klanten in de loop van de tijd (een groeimarkt voor ons telecombedrijf), vergeleken met de trendcomponent die Prophet heeft geleerd over gespreksvolumes. Er is een sterke correlatie (Pearson coeff.: 0,988) tussen het belvolume en het aantal klanten. Dus het model leert de trend goed, en alleen van de tijdreeks zelf.
Wij hebben een aantal tips en trucs geïdentificeerd om van de trend een echt voordeel te maken voor uw prognoses op basis van prognoses.
Trend: Let op uw veranderpunten
Een van de sterke punten van Prophet is ook een zwak punt voor de stabiliteit van de resultaten en de prestaties: De trendcomponent heeft de neiging om het overgrote deel van de voorspelling te verklaren — ongeveer 90% voor onze casestudy. Als de trend dus niet goed wordt geschat, zullen de prestaties dramatisch afnemen en kunt u meer dan 20 MAPE-punten verliezen door in de loop van de tijd te veel of te weinig te voorspellen. U hebt meerdere parameters om Prophet te helpen de trend aan te passen, waaronder de `changepoint_prior_scale` en de `changepoint_range`.
Het vinden van de juiste waarde voor changepoint_prior_scale is essentieel, omdat deze parameter de flexibiliteit van de trend bepaalt. Hoe hoger deze is, hoe flexibeler de trend. Onze strategie is om deze parameter in een raster te zoeken met deze waarden (in een logaritmische schaal): [0.001, 0.01, 0.1, 0.5]. Relatief kleine waarden leiden over het algemeen tot een betere generalisatie.
Trend: Haal het meeste uit de meest recente data
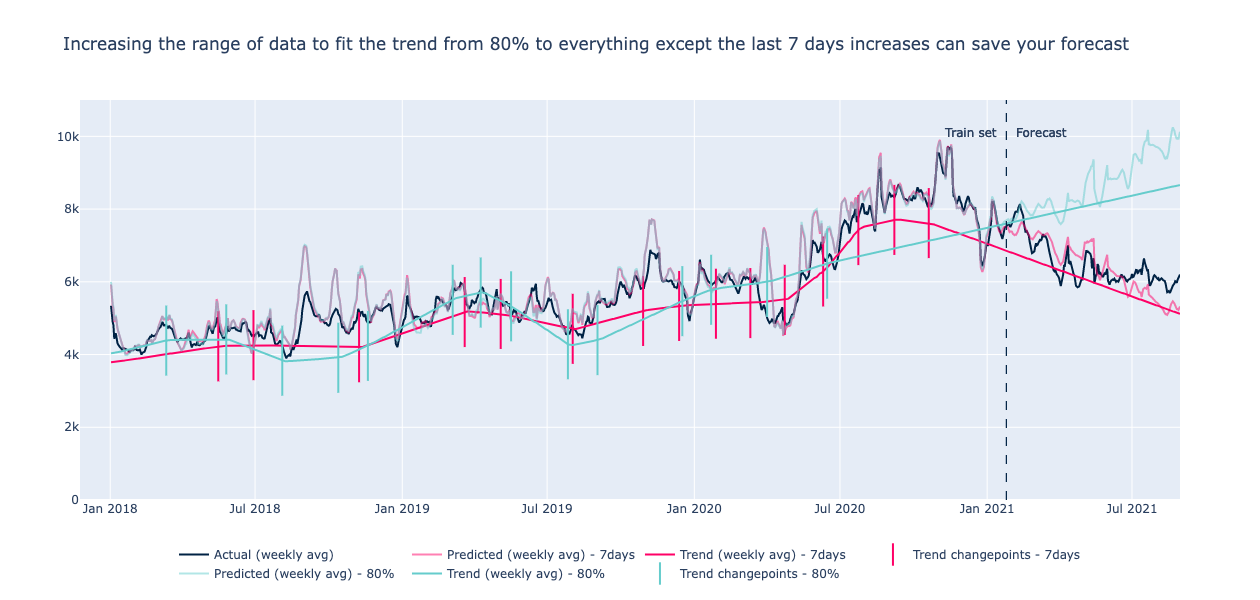
Volgende aandachtspunt: standaard houdt Prophet rekening metalleen de eerste 80% van de geschiedenis naar de trend benaderen door 25 potentiële veranderpunten op te geven. Wij ontdekten dat het verhogen van deze waarde van 80% door het veranderen van de changepoint_range parameter de prestaties verbeterde. Dit houdt namelijk ook rekening met de laatste data, die in ons geval belangrijker zijn om het niveau van de oproepen te verklaren. In deze grafiek kunt u bijvoorbeeld zien dat 2021 data belangrijk is omdat het een dalende trend heeft. We hebben ervoor gekozen om de hele trainingsset in aanmerking te nemen, behalve de laatste 7 dagen, in plaats van 80%.
Trend: Schoon uw uitschieters op
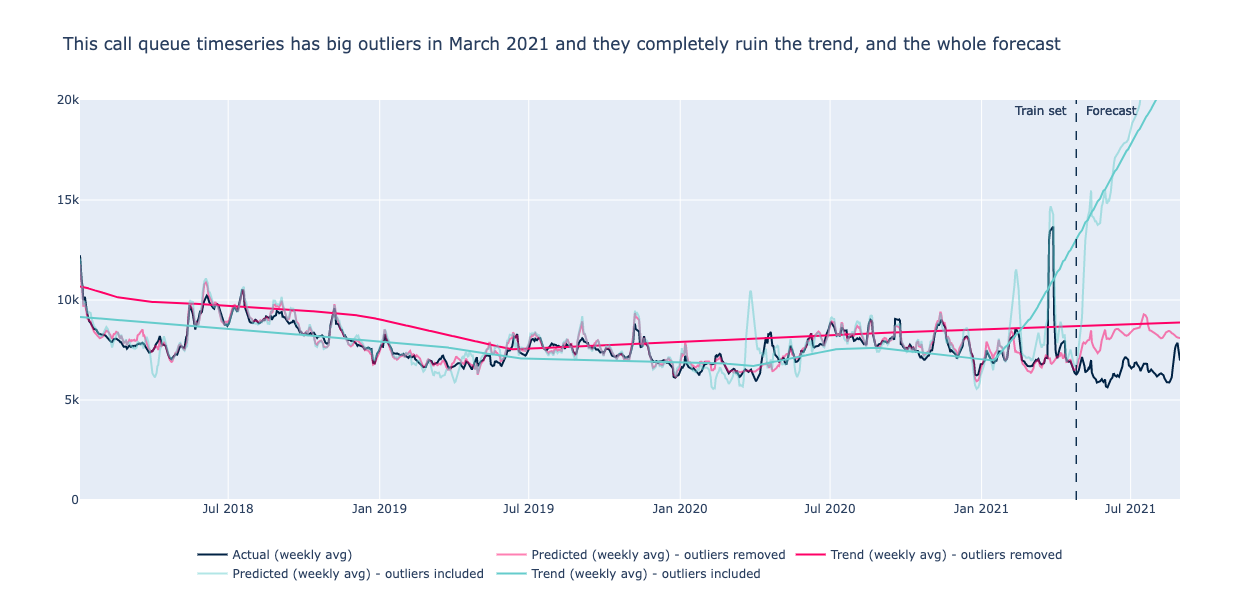
Iets anders om te overwegen is de gevoeligheid voor uitschieters. De officiële documentatie raadt aan om ze te verwijderen: “Prophet kan omgaan met de uitschieters in de geschiedenis, maar alleen door ze aan te passen met trendveranderingen”.
Seizoensgebondenheden
Seizoensgebonden componenten, zoals dagelijks en jaarlijks, worden geschat met Fourier-reeksen. Omdat onze tijdreeksen sterke seizoensgebonden bedrijfscycli hebben, vonden we dat Prophet vrij goed werkt.
Maar toen we wat dieper in de zaken doken, ontdekten we dat modellering van wekelijkse seizoensgebondenheid is beperkt. Onze tijdreeksen hadden erg lage zaterdagen in vergelijking met de rest van de week (en geen waarden op zondag). We hebben veel tijd en moeite besteed aan het verbeteren van onze voorspellingen voor deze specifieke dag van de week.
Uiteindelijk moesten we een omweg gebruiken: het stapelen van twee modellen, waaronder ons Profetenmodel en een statistisch model het berekenen van voorspellingen op basis van het gemiddelde gewicht van de weekdagen over de afgelopen 6 weken. En dit ondanks dat ik geprobeerd heb om alle parameters in de wekelijkse seizoensgebondenheid van Prophet te veranderen.
Onze interpretatie: Bij een seizoensgebonden periode van 7 dagen (6 in ons geval zonder zondagen) is het verhogen van de Fourier-volgorde niet zo nuttig, omdat het interval tussen 0 en 2pi slechts in een paar segmenten (6 of 7) verdeeld is. En een lage Fourier-volgorde betekent dat het is niet geschikt voor extreme waarden en snelle veranderingen in seizoensgebondenheid, zoals zaterdag in het bovenstaande voorbeeld.
Enkele andere trucs om de seizoensgebondenheid te verfijnen:
Gebeurtenissen en extra regressoren
Voor gebeurtenissen en extra-regressoren Prophet kan ook handig zijn.
U kunt extra- toevoegenregressoren, continu of categorisch, door een andere tijdreeks (waarden en data) aan het model te geven met de optie add_regressor methode. Gebeurtenissen worden beheerd als categorische regressoren (de waarde is ofwel 0 - de gebeurtenis vindt niet plaats op die dag of dat uur - of 1 - de gebeurtenis vindt plaats).
Nieuwe gebeurtenissen toevoegen is eenvoudig: u hoeft Prophet alleen maar een dataframe te geven dat de data en namen van gebeurtenissen bevat.
Het werkte heel goed met vakanties, vrije dagen en andere evenementen. En het heeft de neiging om geven betere resultaten dan de op bomen gebaseerde modellen.
Bovendien gebruikt Prophet de Python vakantie pakket zodat u alleen de id van het land (USA of FRA) kunt gebruiken om gerelateerde vakanties als functie toe te voegen.

Zoals bij veel andere voorspellingsalgoritmen voor tijdreeksen, is het vaak moeilijk om te weten of een terugkerende gebeurtenis al is opgenomen in de seizoensgebondenheid van prophet of dat het handmatig gemarkeerd moet worden om het algoritme te helpen. Een eenvoudig voorbeeld is de kerst- en nieuwjaarsperiode: dezelfde periode, ongeveer hetzelfde effect, elk jaar. Een lastige is de Franse voorjaarsvakantie. In Frankrijk zijn er rond april twee weken schoolvakantie met verschuivende data van jaar tot jaar, en verdeeld per geografisch gebied (niet heel Frankrijk gaat op hetzelfde moment op vakantie).
Hoewel de jaarlijkse seizoensgebondenheid in deze periode laag is, is het effect van een “voorjaarsvakantie”-gebeurtenis positief op de voorspellingen van gespreksvolumes. En het model presteert beter met deze gebeurtenis. Dus het effect van deze gebeurtenis is niet consistent met andere vakanties en met de seizoensgebondenheid die we waarnemen, maar er is een effect op de modeltraining en voorspellingen dat de prestaties verbetert... Moeten we het toevoegen of niet?
We zagen soortgelijke problemen met diverse feestdagen die zich elk jaar verplaatsen, en soms moesten we Prophet met een statistisch model stapelen om de effecten van vakanties beter te laten passen. We kunnen echter geen consistente oplossing bieden.
Featurekruisingen zijn tijdrovend en vaak over-engineered
Aangezien Prophet een ruwweg lineair model in de manier waarop het omgaat met extra functies en gebeurtenissen, is het kruisen van functies niet automatisch. Dit betekent dat Prophet niet kan afleiden dat een combinatie van waarden van verschillende kenmerken zal leiden tot een exponentieel hogere of lagere impact op de voorspelling, terwijl dit iets is wat boomgebaseerde algoritmen en Deep Learning heel goed kunnen afleiden.
Voorbeeld: laten we zeggen dat u een impact hebt op uw tijdreeksen op Werkdag + 1 na een vakantie (HBD+1). Vervolgens voorziet u de Profeet van een gebeurtenis “HBD+1” zal dit effect beter weergeven. Maar hier hangt het effect grotendeels af van het feit of de dag HBD+1 op een maandag, zaterdag enz. is. En het is niet lineair noch vermenigvuldigend. U zult dus alle functies moeten toevoegen “HBD+1_maandag”, “HBD+1_dinsdag”,…
Als u functies kruist, groeit hun aantal exponentieel en dat gaat u allebei kosten. tijd om ze te berekenen, een verlies aan interpreteerbaarheid, en waarschijnlijk een daling van de prestatiesals u te veel van deze functies toevoegt.
Interpretabiliteit
Een van de belangrijkste voordelen van de Prophet ten opzichte van andere modellen is de interpreteerbaarheid.
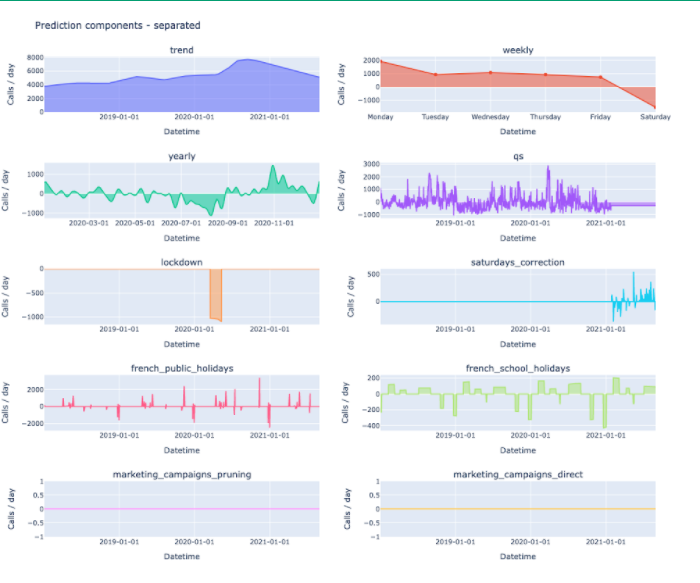
De eigen decompositie van de voorspelling in trend-, seizoens-, gebeurtenissen- en extra-regressorcomponenten is zinvol voor low-tech profielen.
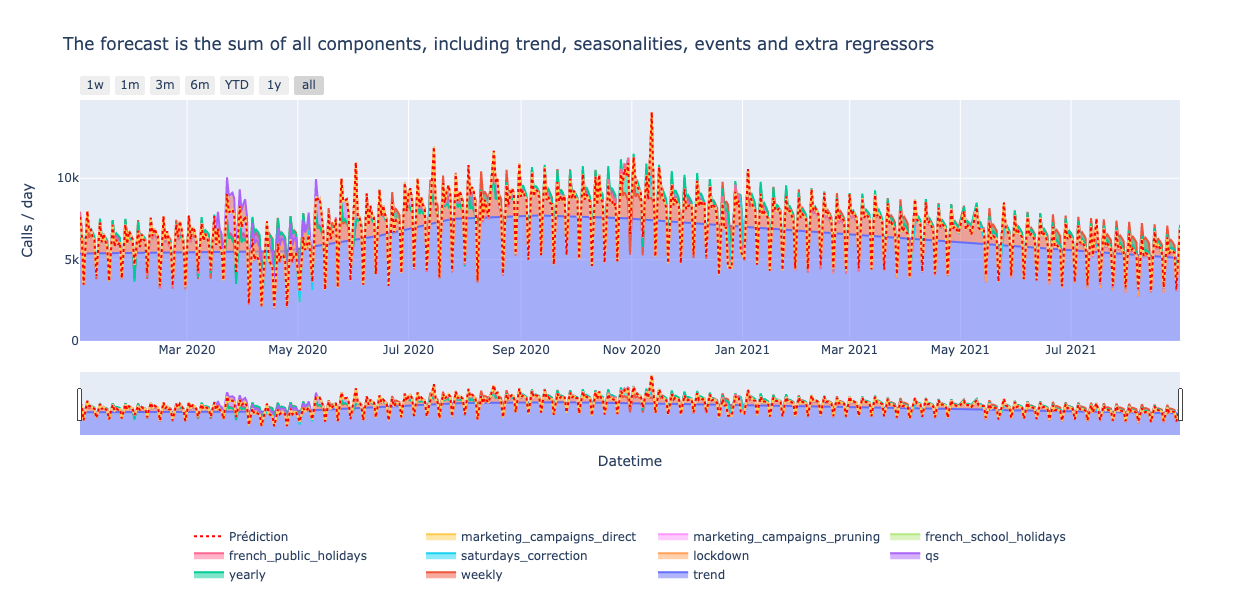
Profeet is een additief model De som van elke component is gelijk aan de voorspelling. Het belang van elke component wordt uitgedrukt rechtstreeks in de doelunit(in tegenstelling tot SHAP-waarden). En het biedt zowel lokale als globale verklaarbaarheid.
Daarom is het echt gemakkelijk om de voorspelling / impact van elke component op de voorspelling uit te zetten. Als u ervoor kiest om over te schakelen op een multiplicatieve modus, waarbij elke component wordt uitgedrukt als een percentage van de trend, dan zult u iets meer werk moeten doen, maar het blijft heel gemakkelijk om te plotten.
Helaas zijn al deze componenten slechts ongeveer 10% van de voorspelling, de resterende 90% wordt voorspeld in de trend... die bijna onverklaarbaar is. Het is uw taak om te proberen de trend te verklaren met behulp van externe regressoren die u niet kunt gebruiken als kenmerken voor Prophet, zoals de groei van het klantenbestand, contactpercentages en veranderingen in klantgedrag voor onze casestudy. Hiervoor hebt u de werkelijke waarden nodig die aan elk van deze kenmerken zijn gekoppeld: het is dus alleen mogelijk om uw trend te analyseren als u terugkijkt naar de voorspellingen die in het verleden zijn gedaan.
Prestaties en onderhoudbaarheid in productie
Prestaties
Prophet heeft zeer snel goede prestaties, vergeleken met de ontwikkelingstijd. Met andere woorden, het biedt snel een goede basislijn, omdat u geen tijdfuncties hoeft te maken.
Prophet maakt het mogelijk om tijdreeksen te voorspellen met bijna geen feature engineering en een goed prestatieniveau, in recordtijd.
Het traint snel: het duurt minder dan 1 minuut per model, met kruisvalidatie, op een dataset met ~3 jaar data op een macbook Air met M1-chip en 8 Go geheugen.
Als er nieuwe data in productie komt, moet u het model opnieuw aanpassen. Een manier om de training te versnellen is om de fit warm te starten, met behulp van de modelparameters van het eerdere model. U kunt deze functie ook gebruiken om het kruisvalidatieproces te versnellen. Raadpleeg de sectie “Aangepaste modellen bijwerken”.” in de documentatie om verder te gaan.
Prophet heeft minstens twee jaar data nodig om de jaarlijkse seizoensgebondenheid te berekenen, maar wij raden aan om met ten minste 3 jaar ervaring in het verleden data om goede prestaties te leveren.
We behaalden een prestatie van ~15% MAPE na een paar iteraties. Het verfijnen van de resultaten was echter een hele uitdaging en het was moeilijk om dit plafond te bereiken. We moesten enkele aangepaste correcties op de uitvoer ontwikkelen om een ~10% MAPE te bereiken.
In ons project hebben Prophet en XGboost vergelijkbare prestatiecijfers in de M+1- en M+2-horizon. De prestaties in M+3 en M+4 hebben echter de neiging om meer achteruit te gaan bij Prophet in vergelijking met XGboost. Dit komt doordat de trend niet correct werd geschat. Hoewel dit geen invloed heeft op kortetermijnvoorspellingen, worden langetermijnvoorspellingen sterk beïnvloed door de trendrichting, omdat deze in de loop van de tijd blijft toe- of afnemen, wat leidt tot over-/ondervoorspellingen. Het is waarschijnlijk veiliger om voor langetermijnvoorspellingen een andere benadering te gebruiken.
Interessant, soms kan het toevoegen van meer historische data contraproductief zijn en leiden tot een afname van de prognosenauwkeurigheid. Prophet staat niet toe om meer gewicht te geven aan de meest recente waarnemingen, dus meer data kan leiden tot een afname van de prognosenauwkeurigheid.
Hier zou de tip zijn om experimenten uit te voeren met verschillende lengtes van historische data en de lengte te kiezen die de beste resultaten oplevert.
Stabiliteit van de resultaten
Ondanks enkele onmiskenbare voordelen is Prophet geen plug-and-play model. Het vereist enige tijd om het af te stellen om de prestaties te verbeteren. Sommige zwakke punten maken het moeilijk om te vertrouwen op de stabiliteit in de productie.
Om te beoordelen hoe vaak we het model opnieuw zouden moeten trainen, vergeleken we 2 strategieën. We genereerden prognoses voor verschillende maanden en maten de resultaten:
Het model elke maand opnieuw trainen leverde betere resultaten op. Concluderend, ondanks de tijdelijke kruisvalidatie waren de hyperparameters niet stabiel in de loop van de tijd. Voor XGboost hoeft u een dergelijke hertraining niet vaak uit te voeren. Deze resultaten moeten echter met voorzichtigheid worden behandeld, omdat de volumes werden beïnvloed door de COVID-crisis op het moment dat we deze benchmark maakten. Ook hier was onze intuïtie om het resultaat te verklaren dat de trend moeilijk correct in te schatten is.
Schaalbaarheid
Een van de nadelen van dit univariate model is dat u één model per SKU, in vergelijking met boomgebaseerde benaderingen waarbij u hetzelfde model voor veel producten kunt gebruiken.
Meestal leidt dit tot betere prestaties, zoals Pierre-Yves Mousset opmerkte op zijn project. Het hebben van veel modellen kan echter een technische uitdaging zijn en een nachtmerrie om te onderhouden.
Conclusie
Het gebruiksgemak van Prophet maakte het tot een zeer goed basismodel wanneer uw tijdreeks gemakkelijk uiteenvalt in eenvoudige temporele componenten. Als uw signaal echter rumoerig is, kan het een heel gedoe zijn om de prestaties van het model te verfijnen.
Dankzij de ingebouwde uitsplitsing van de prognose in tijdscomponenten zijn de beslissingen van het model gemakkelijk te interpreteren. Toch is het niet nauwkeurig genoeg om te worden gebruikt om de impact van een externe gebeurtenis te meten, omdat u nooit weet of het effect van de gebeurtenis al is meegenomen in de oorspronkelijke tijdcomponenten.
Als uw tijdreeks enkele bedrijfscycli volgt, kunt u snel zeer goede prestaties verkrijgen zonder intensieve feature engineering. De trendcomponent wordt echter niet altijd goed geschat, en dit kan aanzienlijke prestatieafwijkingen veroorzaken. Daarom kan dit model zorgvuldige controle en frequente menselijke tussenkomsten vereisen.
Als u enige verklaarbaarheid wilt bieden en gemakkelijk en snel een fatsoenlijk model wilt bouwen, is Prophet een optie om te overwegen. Als u echter waarde hecht aan stabiliteit en nauwkeurigheid van de voorspelling, overweeg dan het gebruik van een ander soort algoritme, zoals boomgebaseerde modellen, Baan of DeepAR.
