


Auteur

U hebt een basislijn nodig voor uw laatste voorspellingsproject voor tijdreeksen? U wilt het besluitvormingsproces van een voorspellingsmodel uitleggen aan een bedrijf audience? U wilt begrijpen of autoprijzen seizoensgebonden zijn voordat u een nieuwe koopt? Dan hebben wij misschien iets voor u! Dit artikel introduceert Streamlit Prophet, een webapp waarmee data wetenschappers voorspellingsmodellen op een visuele manier kunnen trainen, evalueren en optimaliseren. Prognoses worden gemaakt met Prophet, een snel en gemakkelijk te interpreteren model.
U kunt de app online testen hier maar het is mogelijk dat het niet altijd beschikbaar is, vanwege beperkte gedeelde computerbronnen. Een andere optie is om de python pakket en voer het lokaal uit.
Wat is Streamlit Prophet?
Streamlit Prophet is een Python-pakket waarmee u een app kunt implementeren om voorspellingsmodellen voor tijdreeksen te bouwen visueel en zonder codering. Zodra u een dataset met historische waarden van het te voorspellen signaal hebt geüpload, traint de app in een paar klikken een voorspellend model, samen met verschillende visualisaties om u te helpen de prestaties te evalueren en meer inzicht te krijgen.
Het onderliggende model wordt gebouwd met Profeet, een open source bibliotheek ontwikkeld door Facebook om tijdreeksen data te voorspellen. Het signaal wordt opgesplitst in verschillende componenten zoals trend, seizoensinvloeden en vakantie-effecten. De schatter leert hoe elk van deze blokken afzonderlijk gemodelleerd moet worden en telt vervolgens hun verschillende bijdragen op om een gemakkelijk interpreteerbare voorspelling te produceren. De schatter presteert beter als de reeksen sterke seizoenspatronen hebben en als er verschillende cycli van historische data beschikbaar zijn. U kunt dit bekijken draad of dit artikel als u meer wilt weten over de wiskundige fundamenten van Prophet.
De interface is gemaakt met Beekverlicht, een Python framework voor het bouwen van data wetenschappelijke webapps.
Wat zijn de belangrijkste kenmerken?
Streamlit Prophet is bedoeld om data wetenschappers en bedrijfsanalisten snel op weg te helpen met hun tijdreeksprojecten. Ter illustratie: laten we zeggen dat we de toekomstige verkoop van consumentengoederen in een bepaalde winkel willen voorspellen, op basis van historische data van 2011 tot 2015. Onze data-set ziet eruit als de onderstaande tabel.

Een basismodel met standaardparameters wordt toegepast op de data zodra deze geüpload is. Laten we nu eens kijken hoe we Streamlit Prophet kunnen gebruiken om het te verbeteren en een beter begrip van het fenomeen te krijgen.
Data exploratie
De eerste stap in elk prognoseproject is ervoor zorgen dat de dataset geen geheimen voor u heeft. Prophet biedt van nature een mooie decompositie van het signaal om u te helpen dat doel te bereiken. Er zijn verschillende grafieken beschikbaar in de app om deze waardevolle inzichten in één oogopslag te krijgen.
De volgende grafiek is een goed uitgangspunt, omdat deze een globale weergave geeft van de geüploade tijdreeks en veel nuttige informatie bevat.

De zwarte punten zijn de werkelijke historische verkopen, die meestal tussen 75 en 225 eenheden per dag liggen. Aan het einde van elk jaar rond Kerstmis, wanneer de winkels waarschijnlijk gesloten zijn, zijn er enkele uitschieters met geen verkoop of met lage volumes. De trend wordt weergegeven op een rode lijn om een meer synthetisch beeld van het signaal te krijgen en globale evoluties te visualiseren. Tot slot geeft de blauwe lijn de prognoses weer van een Prophet-model dat automatisch getraind is op uw dataset. Hier kunnen we zien dat het model verwacht dat de verkoop in 2016 zal toenemen, in navolging van de groeiende trend die in 2015 begon.
Deze voorspellingen lijken seizoensgebonden te zijn, maar het is moeilijk om de verschillende periodieke componenten op deze eerste plot te onderscheiden. Laten we een andere visualisatie bekijken om te begrijpen hoe deze seizoenspatronen de modeluitvoer beïnvloeden.

Er zijn twee periodiciteiten gedetecteerd die enkele interessante inzichten geven in de gewoonten van consumenten. De wekelijkse cyclus laat zien dat de meeste mensen winkelen in het weekend, waarin de prognoses met bijna 40 eenheden per dag worden verhoogd. De grafiek suggereert ook dat de verkochte producten een jaarlijkse seizoensgebondenheid hebben, met iets meer verkoop tijdens de zomer dan tijdens de rest van het jaar. Deze periodieke componenten en de globale trend worden dan door de schatter gecombineerd om voorspellingen voor toekomstige dagen te produceren.
Prestatie-evaluatie
Deze plots geven de manier weer waarop data door Prophet gemodelleerd wordt, maar hoe kunnen we er zeker van zijn dat deze weergave betrouwbaar is? Om deze legitieme vraag te beantwoorden, is een deel van de app gewijd aan het evalueren van de kwaliteit van het model. Het geeft de gebruiker snel een basislijn voor de voorspellingsprestaties. Hiervoor wordt de tijdreeks in verschillende delen opgesplitst: het model wordt eerst toegepast op een trainingsset en vervolgens getest op een validatieset. Andere opties zoals kruisvalidatie zijn ook beschikbaar voor geavanceerder gebruik.
Er kunnen verschillende meeteenheden worden gebruikt om de kwaliteit van het model te beoordelen: absolute meeteenheden zoals de RMSE (root mean squared error) zijn nuttig om een idee te krijgen van de grootte van de fouten in termen van het aantal verkopen, maar relatieve meeteenheden zoals de MAPE (mean absolute percentage error) zijn wellicht beter te interpreteren. Het is aan u om de metriek te selecteren die het meest relevant is voor uw gebruikssituatie.
Het is echter onwaarschijnlijk dat de prestaties uniform zijn over alle data punten, daarom is het verkrijgen van een globale indicator niet voldoende. We moeten metrieken op een meer gedetailleerde granulariteit berekenen om een duidelijk inzicht te krijgen in de kwaliteit van het model. Laten we beginnen met een diepgaande analyse op dagniveau, wat in ons geval de laagst mogelijke granulariteit is, aangezien het model één voorspelling per dag doet.

We kunnen een belangrijke variabiliteit waarnemen: er zijn dagen waarop de fout groter is dan 20%, terwijl sommige andere voorspellingen bijna perfect accuraat zijn. Met deze informatie in uw achterhoofd kunt u het waarschijnlijk niet laten om u af te vragen of er patronen zijn in de manier waarop het model fouten maakt. Zijn er bepaalde dagen waarop we kunnen verwachten dat het slecht presteert? Gelukkig biedt de app een aantal handige grafieken waarmee we onze nieuwsgierigheid kunnen bevredigen.
Foutdiagnose
Het gedeelte over foutdiagnose is waarschijnlijk het nuttigst, omdat u hiermee de gebieden kunt aanwijzen waar de prognoses kunnen worden verbeterd en dus nauwkeuriger de belangrijkste uitdagingen kunt identificeren waarmee u te maken krijgt bij het bouwen van een betrouwbaar prognosemodel.
Er zijn verschillende visualisaties beschikbaar om dat onderzoek uit te voeren. Ze zijn interactief, zodat u zich gemakkelijk op bepaalde gebieden kunt richten. In de onderstaande scatterplot wordt bijvoorbeeld elke prognose voor de validatieset weergegeven met één punt, en door met de muis over de punten te gaan die ver van de rode lijn afliggen, kunnen we begrijpen voor welk soort data punten de prognoses ver van de waarheid afliggen.

Als u in ons voorbeeld met de muis over het gebied rechtsboven beweegt, ziet u dat de punten die het verst van de rode lijn af liggen zaterdag en zondag zijn, wat suggereert dat het model doordeweeks beter presteert. Laten we de prestatiecijfers samenvoegen per dag van de week om deze intuïtie te valideren.

In het weekend zijn de fouten inderdaad gemiddeld groter dan tijdens de rest van de week, wat informatie is om in gedachten te houden wanneer u het model probeert te optimaliseren. Prestaties kunnen ook in de loop van de tijd veranderen, daarom is het mogelijk om andere aggregatieniveaus te selecteren die in de app beschikbaar zijn om dit te controleren. We kunnen bijvoorbeeld de statistieken op een wekelijkse of maandelijkse granulariteit berekenen, of over een specifieke tijdsperiode waarin we vermoeden dat het model anders presteert dan normaal.
Modeloptimalisatie
Zodra we de belangrijkste zwakke punten van het model hebben ontdekt, zijn er verschillende opties beschikbaar om het te verbeteren: in de zijbalk van de app kunt u de standaardconfiguratie bewerken en uw eigen specificaties invoeren. Alle prestatiecijfers en visualisaties worden bijgewerkt telkens wanneer u de instellingen wijzigt, zodat u snel feedback krijgt.
De eerste manier om betere prestaties te bereiken is door wat aangepaste voorbewerking toe te passen op uw dataset. Er zijn verschillende alternatieven mogelijk om de eerder geïdentificeerde uitdagingen te omzeilen. Met een opschoningssectie kunnen we bijvoorbeeld de uitschieters die rond Kerstmis zijn waargenomen en die het model zouden kunnen verwarren, verwijderen. We kunnen ook bepaalde dagen uitfilteren en zo gemakkelijk verschillende modellen trainen voor de week en de weekenden, aangezien deze geassocieerd lijken te zijn met verschillend koopgedrag. Er zijn ook enkele andere opties voor filteren en resamplen beschikbaar, voor het geval deze relevant zijn voor het probleem in kwestie.
Prophet hyperparameters kunnen ook worden afgestemd om het model beter te laten passen bij de data. Deze parameters beïnvloeden hoe de schatter leert om de trend en seizoensgebondenheid van historische verkopen weer te geven, en het relatieve gewicht van deze componenten in de globale voorspelling. Maakt u zich geen zorgen als u niet bekend bent met Prophet-modellen: sommige tooltips leggen de intuïtie achter elke parameter uit en begeleiden u bij het afstemmen. In het modelleringsgedeelte kunt u het model ook voeden met externe informatie, zoals vakantiedagen of variabelen die gerelateerd zijn aan het te voorspellen signaal (zoals de verkoopprijs van de producten). Deze regressoren zullen de prestaties waarschijnlijk verbeteren, omdat ze het model extra kennis geven over een fenomeen dat van invloed is op de verkoop.
Interpreteerbaarheid van prognoses
Een nauwkeurig voorspellingsmodel hebben is leuk, maar de belangrijkste factoren die bijdragen aan de voorspellingen kunnen verklaren is nog beter. Het laatste deel van de app is bedoeld om ons te helpen begrijpen hoe het model dat we zojuist gebouwd hebben beslissingen neemt. Er zijn verschillende manieren om deze vraag aan te pakken: we kunnen ofwel naar een enkele component kijken en zien hoe zijn bijdrage aan de totale voorspellingen in de loop van de tijd evolueert, of we kunnen een enkele voorspelling nemen en deze ontbinden in de som van de bijdragen van verschillende componenten.
Laten we beginnen met de eerste optie. De verschillende componenten die de prognoses beïnvloeden zijn de trend, seizoensgebonden factoren en externe regressoren. We hebben de invloed van wekelijkse en jaarlijkse seizoensinvloeden al gezien, dus laten we ons richten op de externe regressoren die we hebben opgenomen in het gedeelte over modeloptimalisatie: feestdagen en de verkoopprijs van de producten.

De invloed van sommige feestdagen is heel belangrijk: de Dag van de Arbeid bijvoorbeeld verhoogt de prognoses met 50 verkopen per jaar aan het begin van september, en de dalingen met Kerstmis laten zien dat het model rekening heeft gehouden met het feit dat winkels op die dag sluiten. De prijs is jaar na jaar gestegen en daarom is de invloed ervan op de verkoop van positief naar negatief verschoven.
Het kan ook nuttig zijn om uit te leggen hoe het model een specifieke voorspelling heeft gedaan, vooral wanneer een bepaalde gebeurtenis de voorspelling beïnvloedt. De volgende watervalgrafiek toont deze decompositie voor de voorspelling op 31 oktober 2012.

In dit voorbeeld voorspelde het model uiteindelijk 96 verkopen, wat de som is van de bijdragen van vijf verschillende componenten:
Dit soort decompositie is niet alleen handig voor het delen van inzichten met medewerkers, maar kan analisten ook helpen begrijpen waarom hun model niet presteert zoals verwacht. Indien nodig zijn er verschillende parameters beschikbaar in de zijbalk van de app om het relatieve gewicht van de verschillende componenten te verhogen of te verlagen.
Hoe begint u?
Het uitvoeren van de app op uw eigen computer is vrij eenvoudig. De enige vereiste is dat Python geïnstalleerd is. Voor Windows-gebruikers zijn wat meer vereisten nodig (zie archief voor meer details). Daarna kunt u de onderstaande instructies volgen om aan de slag te gaan.
Installatie
Wij raden aan om een nieuwe virtuele omgeving aan te maken om problemen met afhankelijkheden of incompatibiliteit met uw huidige omgeving te voorkomen. Zodra uw nieuwe omgeving geactiveerd is, kunt u het pakket met het volgende commando installeren. De installatie kan enkele minuten (5-10) duren.
Ren
Nu het pakket geïnstalleerd is, kunt u met één commando de app vanaf uw terminal starten en in uw standaard webbrowser openen.
En u bent klaar om Prophet-modellen te bouwen! Om te beginnen met modelleren, moet u eerst uw dataset uploaden als een csv-bestand met het volgende formaat.
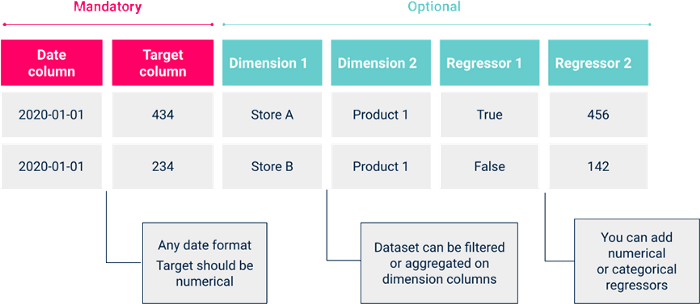
Vervolgens kunt u uw specificaties opgeven in de zijbalk om de voorbewerkingstaken uit te voeren die aan uw behoeften voldoen en de hyperparameters van het model af te stemmen. Zodra u tevreden bent met de resultaten, slaat u uw experiment op om alle visualisaties te bewaren en het later gemakkelijk te kunnen reproduceren.
Inzet in de cloud
Als u de app gemakkelijk toegankelijk wilt maken voor meerdere medewerkers zonder dat zij Python hoeven te downloaden en het pakket hoeven te installeren, kunt u de app op de cloud implementeren. Het eerste wat u moet doen is de git repository klonen. Vervolgens kunt u met een Docker-commando de applicatie gemakkelijk containeriseren en een image maken dat gebruikt kan worden om de app op het cloud platform van uw keuze te implementeren. Deze artikel legt in detail uit hoe u dit kunt doen op Google Cloud Platform.
Bedankt voor het lezen, ik hoor graag uw feedback. Voel u vrij om contact met ons op te nemen als u wilt bijdragen aan de ontwikkeling van het pakket of als u ideeën voor verbetering hebt. In de tussentijd kunt u de projectopslagplaats om een korte demo te bekijken en Artefact tech blog voor meer informatie over onze data wetenschapsprojecten.
