

Auteur

Een stap-voor-stap handleiding voor het detecteren, omlijnen en classificeren van landbouwpercelen op satellietbeelden
Dit artikel maakt deel uit van een serie van 2 artikelen over de verwerking van satellietbeelden toegepast op de landbouw. Als u geïnteresseerd bent in het verzamelen en verwerken van satellietbeelden, raadpleeg dan dit eerste artikel door Antoine Aubay.
Deel 2 richt zich op hoe we deze verwerkte satellietbeelden in een landbouwcontext hebben gebruikt om:
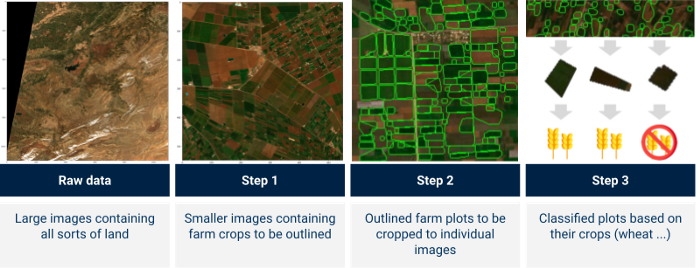
Illustratie van het doelproces
Deel 2 richt zich op hoe we deze verwerkte satellietbeelden in een landbouwcontext hebben gebruikt om:
TL;DR:
Dit artikel zal:
Dit artikel gaat uit van basiskennis van data wetenschap en computervisie.
Zakelijke motivatie
Een oplossing die gewassen automatisch kan detecteren en labelen kan een groot aantal zakelijke toepassingen hebben. Het berekenen van het aantal percelen, hun gemiddelde grootte, de dichtheid van de vegetatie, de totale oppervlakte van specifieke gewassen en nog veel meer indicatoren kan verschillende doelen dienen. Overheidsorganisaties zouden deze statistieken bijvoorbeeld kunnen gebruiken voor nationale statistieken, terwijl particuliere landbouwbedrijven ze zouden kunnen gebruiken om hun potentiële markt zeer gedetailleerd in te schatten.
Natuurlijk werden satellietbeelden overwogen en geïdentificeerd als een zeer levensvatbare data bron om 3 specifieke redenen:
Stap 1 - Landbouwgebieden detecteren op satellietbeelden
![]()
Sentinel-2 onbewerkt beeld: 10 000 x 10 000 pixels, elke pixel 10 x 10 meter op de grond (Copernicus Sentinel data 2019)
Na het ophalen en voorbewerken van Sentinel 2-beelden was onze eerste uitdaging om de plots te lokaliseren en ons te beperken tot specifieke interessegebieden. Omdat elk beeld een zeer hoge resolutie heeft, zou het niet realistisch zijn om de hele verwerking toe te passen op beelden op ware grootte. In plaats daarvan was de eerste stap om ons probleem op te lossen het bijsnijden van grote beelden in kleinere fragmenten, en het identificeren van de gebieden waar de plots zich op deze kleinere beelden bevonden:

Onze gewenste uitvoer: fragmenten met alleen landbouwgebieden (Copernicus Sentinel data 2019)
Oplossing 1A: Een pixelklassificator trainen
De eerste oplossing voor het detecteren van landbouwzones op grote afbeeldingen is het bouwen van een pixelclassificator. Voor elke pixel zou dit machine-learningmodel voorspellen of deze pixel tot een bos, een stad, water, een boerderij ... en dus tot een landbouwzone behoort of niet.
![]() Illustratie van pixelclassificatie met 3 zichtbare klassen van pixels (Copernicus Sentinel data 2019)
Illustratie van pixelclassificatie met 3 zichtbare klassen van pixels (Copernicus Sentinel data 2019)
Omdat veel middelen kan worden gevonden voor Sentinel-2, waren we in staat om gelabelde beelden te vinden met meer dan 10 verschillende grondwaarheidsklassen (bos, water, toendra, ...). Als het klimaat in uw studiegebied echter verschilt van het gebied waarop u uw model hebt getraind, moet u misschien de klassen die aan elke pixel zijn toegewezen opnieuw evalueren.
Nadat we bijvoorbeeld een model hadden getraind op landen met een gematigd klimaat, en het hadden toegepast op meer droge gebieden in de wereld, ontdekten we dat wat het model zag als bossen en toendra's in feite landbouwgewassen waren.
Zodra uw pixels geclassificeerd zijn, kunt u alle afbeeldingen die geen landbouwgebieden bevatten, verwijderen.
Oplossing 1A voors:
Oplossing 1A nadelen:
Van alle beschikbare methoden om landbouwzones te detecteren, was deze het meest nauwkeurig. Als u echter geen toegang hebt tot gelabelde afbeeldingen, hebben we twee alternatieve oplossingen geïdentificeerd.
Oplossing 1B: Geocoördinaten in kaart brengen naar pixelcoördinaten
Als er coördinaten over uw interessegebied gelabeld zijn, of als u zelf coördinaten labelt, is het mogelijk om deze geocoördinaten (lengte- en breedtegraad) op uw afbeeldingen in te brengen.
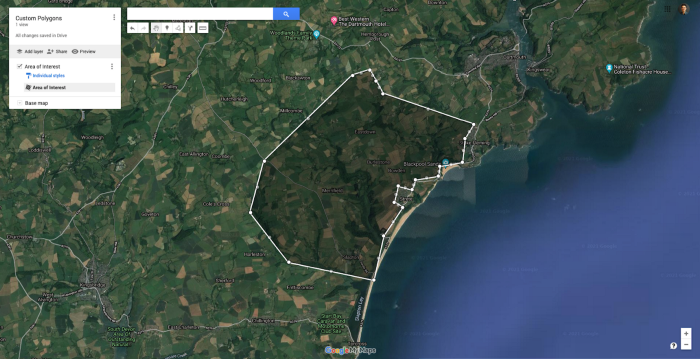
U kunt uw eigen polygonen ontwerpen op GoogleMaps, zodat u zich kunt concentreren op een specifiek gebied naar keuze terwijl u om obstakels heen tekent (water, steden ...).
Als u bijvoorbeeld de coördinaten van grote landbouwgebieden hebt, of als u zelf grote polygonen op Google Maps tekent, kunt u gemakkelijk geocoördinaten van landbouwgebieden verkrijgen. Vervolgens hoeft u alleen nog maar die coördinaten in kaart te brengen op uw satellietbeelden en uw beelden zo te filteren dat ze alleen de zones binnen uw polygonen bestrijken.
Oplossing 1B voors:
Oplossing 1B nadelen:
Oplossing 1C: Een vegetatie-index gebruiken
Het is mogelijk om een vegetatie-index te berekenen uit de kleurbanden die door de satellietbeelden worden geleverd. Een vegetatie-index is een formule die meerdere kleurbanden combineert, vaak sterk gecorreleerd met de aanwezigheid of dichtheid van vegetatie (of andere indicatoren zoals de aanwezigheid van water).
Meerdere indexen bestaan, maar een van de meest gebruikte in een landbouwcontext is de NDVI (Normalized Difference Vegetation Index). Deze index wordt gebruikt om de dichtheid van de vegetatie op de grond te schatten, wat kan dienen om landbouwgebieden op een groot beeld te detecteren.

Visuele weergave van de NDVI op een landbouwgebied en een woestijn (Copernicus Sentinel data 2019)
Na het berekenen van NDVI-waarden voor elke pixel, kunt u een drempel instellen om snel pixels zonder vegetatie te elimineren. Wij hebben NDVI als voorbeeld gebruikt, maar experimenteren met verschillende indices kan helpen om betere resultaten te bereiken.
Merk op dat het berekenen van een vegetatie-index u nuttige informatie kan opleveren om uw analyse te verrijken, zelfs als u al een andere manier hebt geïmplementeerd om landbouwgebieden te detecteren.
Oplossing 1C profs:
Oplossing 1C tegens:
Stap 2 - Landbouwpercelen opsporen en afbakenen
Een ongesuperviseerde randdetector bouwen
Zodra u de locatie van uw landbouwzones hebt bepaald, kunt u beginnen met het afbakenen van individuele percelen op deze specifieke gebieden.
Bij gebrek aan gelabelde data besloten we te kiezen voor een benadering zonder toezicht op basis van OpenCV's Canny Randdetectie. Randdetectie bestaat uit het bekijken van een specifieke pixel en deze te vergelijken met de pixels eromheen. Als het contrast met naburige pixels hoog is, dan kan de pixel als een rand worden beschouwd.
 Een voorbeeld van randdetectie op landbouwpercelen met OpenCV (Copernicus Sentinel data 2019)
Een voorbeeld van randdetectie op landbouwpercelen met OpenCV (Copernicus Sentinel data 2019)
Zodra alle pixels zijn geïdentificeerd die mogelijk echte randen zijn, kunnen we beginnen met het afvlakken van de randen en proberen polygonen te vormen. Zoals verwacht blijken de prestaties van het algoritme voor randdetectie veel beter te zijn wanneer het wordt toegepast op grote plots:

Illustratie van het volledige proces van het schetsen van plots (Copernicus Sentinel data 2019)
Met deze methode konden we automatisch bijna 7000 percelen in ons interessegebied identificeren. Omdat we de pixelclassificatiemethode gebruikten (zie stap 1A), konden we echte landbouwpercelen scheiden van andere polygonen en zo alleen de relevante data behouden.
![]() Polygonen bestaande uit een minderheid van “boerderijpixels” werden geëlimineerd (Copernicus Sentinel data 2019)
Polygonen bestaande uit een minderheid van “boerderijpixels” werden geëlimineerd (Copernicus Sentinel data 2019)
Optimalisatie van de prestaties van het algoritme voor randdetectie
Voor de best mogelijke resultaten kan het nuttig zijn om uw afbeelding aan te passen, met name door te spelen met contrast, verzadiging of scherpte:

Experimenteren met contrast, verzadiging of scherpte kan helpen om de efficiëntie van de randdetectie te verbeteren (Copernicus Sentinel data 2019)
Een andere kritische succesfactor is het forceren van convexe veelhoeken. De meeste plots volgen regelmatige vormen, dus convexe veelhoeken forceren levert meestal veel betere resultaten op.

Het forceren van convexe vormen past veel beter bij de meeste plots (Copernicus Sentinel data 2019)
Stap 3 - Elk perceel classificeren om specifieke gewassen op te sporen
Zodra alle percelen geïdentificeerd zijn, kunt u ze nu allemaal bijsnijden en als afzonderlijke afbeeldingsbestanden opslaan. De volgende stap is het trainen van een classificatiemodel om elk perceel te onderscheiden op basis van het gewas. Met andere woorden, proberen om tomaten te onderscheiden van granen of aardappelen.
Een gelabelde trainingsset bouwen
Omdat we geen reeds gelabelde dataset beschikbaar hadden, en omdat het handmatig labelen van honderden afbeeldingen te tijdrovend zou zijn, zochten we naar complementaire datasets die de informatie over gewassen bevatten voor specifieke percelen op een bepaalde tijd en plaats.
Het ideale scenario zou zijn om vooraf gelabelde beelden te hebben, maar in ons geval hadden we alleen de geocoördinaten en gewassen van een paar honderd landbouwpercelen in ons interessegebied. Deze dataset bevatte een lijst met percelen, de lengte- en breedtegraad van het middelpunt, en het gewas dat er op een bepaalde tijd van het jaar op geplant was.
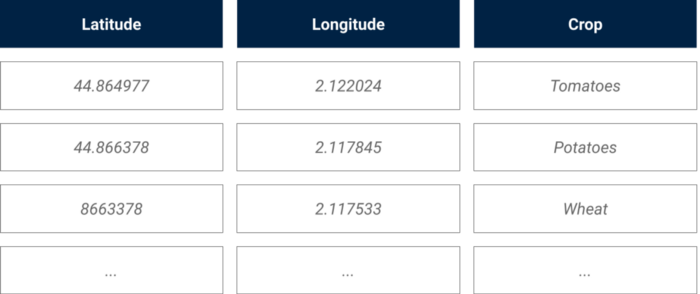
Illustratie van de externe gewas data bron
Om onze trainingsset samen te stellen, gebruikten we onze converter voor geocoördinaten naar pixelcoördinaten (gedeeld in Deel 1) om de specifieke percelen te identificeren waarvoor we een label (het gewas) in onze beeldbank hadden.
Van de 7000 percelen die in stap 2 werden geïdentificeerd, konden we ongeveer 500 percelen labelen dankzij onze externe data bron. Deze 500 gelabelde percelen dienden om het classificatiemodel te trainen en te evalueren.
Modelisering
We hebben ervoor gekozen om een convolutioneel neuraal netwerk te gebruiken met de fastai-bibliotheek, omdat dit een efficiënte manier was om onze afbeeldingen te classificeren.
Om de best mogelijke classificator te vinden, hebben we geëxperimenteerd met de invoer data:

Tientallen modellen werden getraind op datasets die gegenereerd waren met verschillende van data preparatietechnieken
Na het experimenteren met verschillende classificatiemodellen bereikten we een nauwkeurigheid van 78% en een recall van 74% bij het uitvoeren van binaire classificatie op de kleinste plots (en dus de moeilijkste om te classificeren vanwege het lage aantal pixels).
Uitdagingen om in gedachten te houden
Wanneer u met landbouwpercelen werkt, kunnen zelfs een paar weken een aanzienlijk verschil maken. Binnen een paar weken kan een tarweoogst van groen naar goud naar geoogst gaan:
 Bij het werken met landbouwpercelen kunnen slechts enkele weken een groot verschil maken (Copernicus Sentinel data 2019)
Bij het werken met landbouwpercelen kunnen slechts enkele weken een groot verschil maken (Copernicus Sentinel data 2019)
Er zijn dus twee dingen die u in gedachten moet houden om dit project het hele jaar door te kunnen herhalen:
Conclusie
Werken met satellietbeelden opent een eindeloze reeks mogelijkheden. Als u bedenkt hoe elke satelliet andere functies biedt, en hoe de beschikbaarheid en het formaat van aanvullende data over de hele wereld kan variëren, afhankelijk van uw studiegebied, zal elk afzonderlijk project eindigen als een unieke use case.
We hopen dat het delen van onze visie en methodologieën u zal inspireren bij uw eigen projecten! Als u enthousiast bent om aan uw eigen satellietproject te beginnen, lees dan zeker “Satellietbeelden gebruiken voor computer vision-toepassingen met machinaal leren” door Antoine Aubay.
Bedankt voor het lezen, aarzel niet om volg de Artefact tech blog als u op de hoogte wilt worden gebracht wanneer ons volgende artikel verschijnt!
