

Autor

Una guía paso a paso sobre cómo detectar, delinear y clasificar parcelas agrícolas en imágenes de satélite
Este artículo forma parte de una serie de 2 artículos sobre el procesamiento de imágenes por satélite aplicado a la agricultura. Si está interesado en la recogida y el procesamiento de las imágenes por satélite, consulte este primer artículo por Antoine Aubay.
La segunda parte se centra en cómo aprovechamos estas imágenes de satélite procesadas en un contexto agrícola con el fin de:
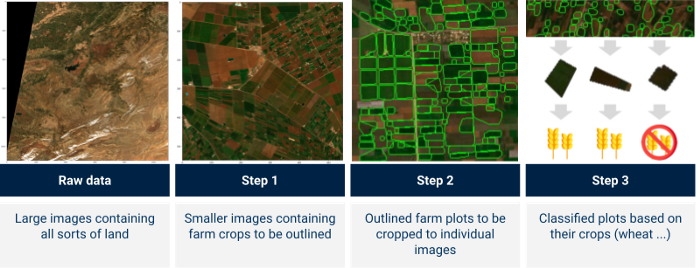
Ilustración del proceso objetivo
La segunda parte se centra en cómo aprovechamos estas imágenes de satélite procesadas en un contexto agrícola con el fin de:
TL;DR:
Este artículo lo hará:
Este artículo asume fundamentos básicos en ciencia data y visión por ordenador.
Motivación empresarial
Una solución capaz de detectar y etiquetar automáticamente los cultivos puede tener una amplia gama de aplicaciones empresariales. El cálculo del número de parcelas, su tamaño medio, la densidad de la vegetación, la superficie total de determinados cultivos y muchos más indicadores podrían servir para diversos fines. Por ejemplo, los organismos públicos podrían utilizar estas métricas para las estadísticas nacionales, mientras que las empresas agrícolas privadas podrían utilizarlas para estimar su mercado potencial con un gran nivel de detalle.
Naturalmente, las imágenes por satélite fueron consideradas e identificadas como una fuente data muy viable por 3 razones específicas:
Paso 1 - Detección de zonas agrícolas en imágenes de satélite
![]()
Imagen en bruto de Sentinel-2: 10 000 x 10 000 píxeles, cada píxel de 10 x 10 metros sobre el terreno (Copernicus Sentinel data 2019)
Tras recuperar y preprocesar las imágenes de Sentinel 2, nuestro primer reto consistió en localizar las parcelas y limitarnos a zonas específicas de interés. Al tener cada imagen una resolución muy alta, no sería realista aplicar todo el procesamiento a imágenes de tamaño completo. En su lugar, el primer paso para resolver nuestro problema fue recortar las imágenes grandes en fragmentos más pequeños e identificar las zonas donde se encontraban las parcelas en estas imágenes más pequeñas:

Nuestro resultado deseado: fragmentos que sólo contienen zonas agrícolas (Copernicus Sentinel data 2019)
Solución 1A: Entrenamiento de un clasificador de píxeles
La primera solución para detectar zonas agrícolas en imágenes de gran tamaño consiste en construir un clasificador de píxeles. Para cada píxel, este modelo de aprendizaje automático predeciría si este píxel pertenece a un bosque, a una ciudad, al agua, a una granja... y, por tanto, a una zona agrícola o no.
![]() Ilustración de la clasificación de píxeles con 3 clases visibles de píxeles (Copernicus Sentinel data 2019)
Ilustración de la clasificación de píxeles con 3 clases visibles de píxeles (Copernicus Sentinel data 2019)
Porque muchos recursos se pueden encontrar para Sentinel-2, pudimos encontrar imágenes etiquetadas con más de 10 clases diferentes de verdad sobre el terreno (bosque, agua, tundra, ...). Sin embargo, si el clima de su zona de estudio es diferente al de la zona en la que entrenó su modelo, es posible que tenga que reevaluar las clases atribuidas a cada píxel.
Por ejemplo, tras entrenar un modelo en países de clima templado y aplicarlo a regiones más áridas del mundo, observamos que lo que el modelo veía como bosques y tundras eran en realidad cultivos agrícolas.
Una vez clasificados los píxeles, puede descartar todas las imágenes que no contengan zonas agrícolas.
Solución 1A pros:
Solución 1A contras:
De todos los métodos disponibles para detectar zonas agrícolas, éste fue el más preciso. Sin embargo, si no tiene acceso a imágenes etiquetadas, hemos identificado dos soluciones alternativas.
Solución 1B: Mapeo de coordenadas geográficas a coordenadas de píxeles
Si se han etiquetado coordenadas sobre su zona de interés, o si las está etiquetando usted mismo, es posible asignar estas coordenadas geográficas (latitud y longitud) a sus imágenes.
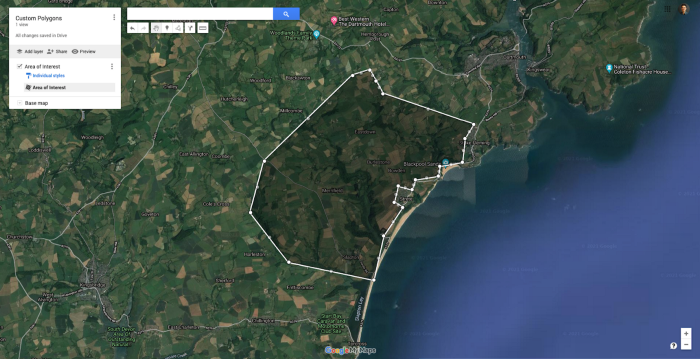
Puede diseñar sus propios polígonos en GoogleMaps, centrándose así en un área específica de su elección mientras dibuja alrededor de obstáculos (agua, ciudades...)
Por ejemplo, si dispone de las coordenadas asociadas a grandes zonas agrícolas, o si dibuja usted mismo grandes polígonos en Google Maps, podrá obtener fácilmente las coordenadas geográficas de las zonas agrícolas. Entonces, todo lo que hay que hacer es mapear esas coordenadas a sus imágenes de satélite y filtrar sus imágenes para que sólo cubran las zonas dentro de sus polígonos.
Solución 1B pros:
Solución 1B contras:
Solución 1C: Utilizar un índice de vegetación
Es posible calcular un índice de vegetación a partir de las bandas de color proporcionadas por las imágenes de satélite. Un índice de vegetación es una fórmula que combina múltiples bandas de color, a menudo muy correlacionadas con la presencia o densidad de vegetación (u otros indicadores como la presencia de agua).
Índices múltiples existen, pero uno de los más utilizados en un contexto agrícola es el NDVI (Índice de vegetación de diferencia normalizada). Este índice se utiliza para estimar la densidad de la vegetación sobre el terreno, lo que podría servir para detectar zonas agrícolas en una imagen de gran tamaño.

Representación visual del NDVI en una zona agrícola y un desierto (Copernicus Sentinel data 2019)
Tras calcular los valores NDVI de cada píxel, puede fijar un umbral para eliminar rápidamente los píxeles sin vegetación. Hemos utilizado el NDVI como ejemplo, pero experimentar con diversos índices podría ayudar a obtener mejores resultados.
Tenga en cuenta que el cálculo de un índice de vegetación puede proporcionarle información útil para enriquecer su análisis, incluso si ya ha aplicado otra forma de detectar las zonas agrícolas.
Solución 1C pros:
Solución 1C cons:
Paso 2 - Detección y delimitación de las parcelas agrícolas
Construcción de un detector de bordes no supervisado
Una vez que haya determinado la ubicación de sus zonas agrícolas, puede empezar a centrarse en delimitar parcelas individuales en estas áreas específicas.
En ausencia de data etiquetados, decidimos optar por un enfoque no supervisado basado en Detección de bordes Canny de OpenCV. La detección de bordes consiste en observar un píxel concreto y compararlo con los que lo rodean. Si el contraste con los píxeles vecinos es alto, entonces el píxel puede considerarse un borde.
 Un ejemplo de detección de bordes en parcelas agrícolas utilizando OpenCV (Copernicus Sentinel data 2019)
Un ejemplo de detección de bordes en parcelas agrícolas utilizando OpenCV (Copernicus Sentinel data 2019)
Una vez identificados todos los píxeles que potencialmente podrían ser bordes verdaderos, podemos empezar a suavizar los bordes e intentar formar polígonos. Como era de esperar, el rendimiento del algoritmo de detección de bordes resulta ser mucho mejor cuando se aplica a parcelas grandes:

Ilustración del proceso completo de trazado de parcelas (Centinela Copérnico data 2019)
Este método nos permitió identificar automáticamente cerca de 7.000 parcelas en nuestra zona de interés. Como utilizamos el método de clasificación de píxeles (véase el paso 1A), pudimos separar las parcelas agrícolas reales de otros polígonos, conservando así sólo los data pertinentes.
![]() Se eliminaron los polígonos formados por una minoría de “píxeles de granja” (Copernicus Sentinel data 2019)
Se eliminaron los polígonos formados por una minoría de “píxeles de granja” (Copernicus Sentinel data 2019)
Optimización del rendimiento del algoritmo de detección de bordes
Para obtener los mejores resultados posibles, puede resultar útil aplicar modificaciones a su imagen, sobre todo jugando con el contraste, la saturación o la nitidez:

Experimentar con el contraste, la saturación o la nitidez puede ayudar a mejorar la eficacia de la detección de bordes (Copernicus Sentinel data 2019)
Otro factor crítico para el éxito es forzar que los polígonos sean convexos. La mayoría de las parcelas siguen formas regulares, por lo que forzar polígonos convexos suele dar resultados mucho mejores.

Forzar las formas convexas se ajusta mucho mejor a la mayoría de las parcelas (Copernicus Sentinel data 2019)
Paso 3 - Clasificación de cada parcela para detectar cultivos específicos
Una vez identificadas todas las parcelas, ya puede recortar cada una de ellas y guardarlas como archivos de imagen individuales. El siguiente paso consiste en entrenar un modelo de clasificación para distinguir cada parcela en función de su cultivo. En otras palabras, tratar de identificar los cultivos de tomates de los cereales, o las patatas.
Construir un conjunto de entrenamiento etiquetado
Dado que no disponíamos de un conjunto data ya etiquetado y que etiquetar manualmente cientos de imágenes nos llevaría demasiado tiempo, buscamos conjuntos data complementarios que contuvieran la información sobre los cultivos de parcelas específicas en un momento y lugar determinados.
Lo ideal sería disponer de imágenes preetiquetadas, pero en nuestro caso sólo contábamos con las coordenadas geográficas y los cultivos de unos cientos de parcelas agrícolas de nuestra zona de interés. Este dataset contenía una lista de parcelas, la latitud y longitud de su centro y el cultivo plantado en ella en una época concreta del año.
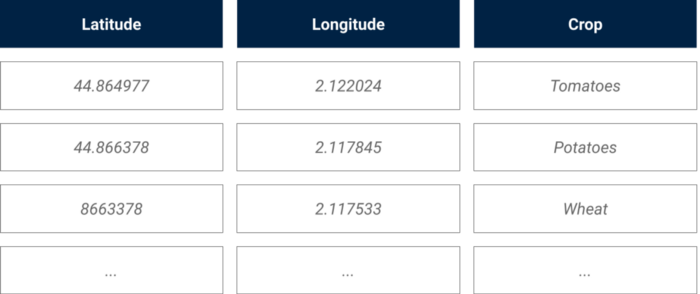
Ilustración de la fuente externa de cultivo data
Para construir nuestro conjunto de entrenamiento, utilizamos nuestro conversor de coordenadas geográficas a coordenadas de píxeles (compartido en Parte 1) para identificar las parcelas específicas para las que teníamos una etiqueta (el cultivo) en nuestro banco de imágenes.
De las 7.000 parcelas identificadas en el paso 2, conseguimos etiquetar unas 500 parcelas gracias a nuestra fuente externa data. Estas 500 parcelas etiquetadas sirvieron para entrenar y evaluar el modelo de clasificación.
Modelización
Optamos por utilizar una red neuronal convolucional utilizando el biblioteca fastai, ya que era una forma eficaz de clasificar nuestras imágenes.
Para encontrar el mejor clasificador posible, experimentamos con la entrada data:

Se entrenaron docenas de modelos en conjuntos de data generados con varias de las técnicas de preparación de data
Tras experimentar con varios modelos de clasificación, alcanzamos una precisión de 78% y una recuperación de 74% al realizar la clasificación binaria en las parcelas más pequeñas (y, por tanto, las más difíciles de clasificar debido al escaso número de píxeles).
Desafíos a tener en cuenta
Cuando se trabaja con parcelas agrícolas, incluso unas pocas semanas pueden suponer una diferencia sustancial. En pocas semanas, los cultivos de trigo pueden pasar de verdes a dorados y a cosechados:
 Cuando se trabaja con parcelas agrícolas, sólo unas pocas semanas pueden suponer una gran diferencia (Copernicus Sentinel data 2019)
Cuando se trabaja con parcelas agrícolas, sólo unas pocas semanas pueden suponer una gran diferencia (Copernicus Sentinel data 2019)
Así pues, hay dos cosas que hay que tener en cuenta para reproducir este proyecto a lo largo del año:
Conclusión
Trabajar con imágenes de satélite abre un abanico infinito de posibilidades. Teniendo en cuenta que cada satélite ofrece características diferentes y que la disponibilidad y el formato de las data complementarias pueden variar en todo el mundo en función de su área de estudio, cada proyecto acabará siendo un caso de uso único.
¡Esperamos que compartir nuestra perspectiva y metodologías le sirva de inspiración en sus propios proyectos! Si tiene ganas de empezar a trabajar en su propio proyecto de imágenes por satélite, no deje de leer “Aprovechamiento de las imágenes de satélite para aplicaciones de aprendizaje automático de visión por ordenador” de Antoine Aubay.
Gracias por leer, no dude en siga el blog técnico de Artefact ¡si desea que le avisemos cuando publiquemos nuestro próximo artículo !
