

观看研讨会的 replay(法语) | 要打开英语字幕,请单击 "CC "图标,然后单击 "设置"。然后,选择 "字幕 "选项,再选择 "自动翻译 "为英语或您选择的语言。.
9月27日,在2022年巴黎大型Data与人工智能大会上,Artefact的Data咨询合作伙伴Justine Nerce和Artefact的Data咨询经理Killian Gaumont与谷歌云的Data分析专家Amine Mokhtari共同举办了Data网格研讨会。Data 网状技术是当今 data 行业最热门的话题之一。但它是什么?它有哪些商业利益?最重要的是,企业如何在其组织中成功部署?
Data 网是分散式 data 管理的一种新的组织和技术模式。它是一种管理分析性 data 的分布式架构方法,允许用户轻松访问和查询 data 所在地,而无需首先将其传送到 data 湖或仓库。Data 网格基于四个核心原则:
研讨会 分为三个部分:
- 商业价值:为什么要采用产品/网格方法?如何实现公司的业务目标?
- 部署方法:如何取得成功?应采取哪些步骤和组织模式?
- 技术堆栈:为什么选择 Google 作为技术解决方案?
Justine Nerce 在开始讨论商业价值时解释道:“采用产品/网格方法的最佳理由之一是它消除了两个恶性循环。第一个恶性循环是每次出现 data 的新用途时都要'重新发明轮子‘:一个新的团队成立,创建自己的 data 管道,以满足其特定需求。结果是什么?所选技术的可共享性和可重用性为零。第二种情况是'构建一个整体’,即 data 的新用途最终被中央 data 团队积压,然后被移交给非 data 专家团队,由他们进行大规模的 data 收集、通用转换和用例开发,这样做的风险是无法满足用户需求‘。’
但如果采用产品方法,恶性循环就会变成良性循环。当出现 data 的新用途时,data 网格会寻找已经存在并可以重复使用的东西,而不是建立新的东西。它可以识别已经负责处理特定主题的领域,并寻找可以加速创建和开发新需求的现有 data 产品,这些产品可以是现有的,也可以在迭代过程中创建新的定制产品。所有这些产品都可以在公司目录中发布。.
data 产品如何创造商业价值
基里安-高蒙解释说,Data 产品在企业中存在已久,但在 data 网中,data 的用途和资质本质上是不同的:
“今天的 data 产品是供企业使用的 data 与便于使用和重复使用 data 的特定功能的结合”。.
data 产品必须符合以下条件,才能被纳入 data 网格:
- 由一支敬业的业主团队管理;;
- 面向最终用户并被广泛采用;;
- 整个生命周期的质量;;
- 可原样重复使用,也可用于制造其他产品;;
- 所有用户均可访问;;
- 标准化,让每个人都说同一种语言。.
在 Artefact,data 产品分为三个不同的产品系列。“有一些原始产品,如用于业务流程的 databases - 它们仍然是 data 产品”,Killian 保证说。“其次是采用定制算法或产品建议的 data 产品,如 Interaction 360°。最上层是与使用相匹配的成品,如仪表盘。这些都是消费类产品,旨在通过将产品开发与业务战略联系起来来创造价值。”
在企业内部署 data 网格
Artefact’我们的 data 网格部署方法从小处着手,对业务用例和痛点进行优先排序。然后确定每个优先级业务用例所需的所有领域和 data 产品(从原始 data 到成品)。组建未来团队,开发首批产品并制定标准。然后,就可以确定未来要开发的相关产品。.
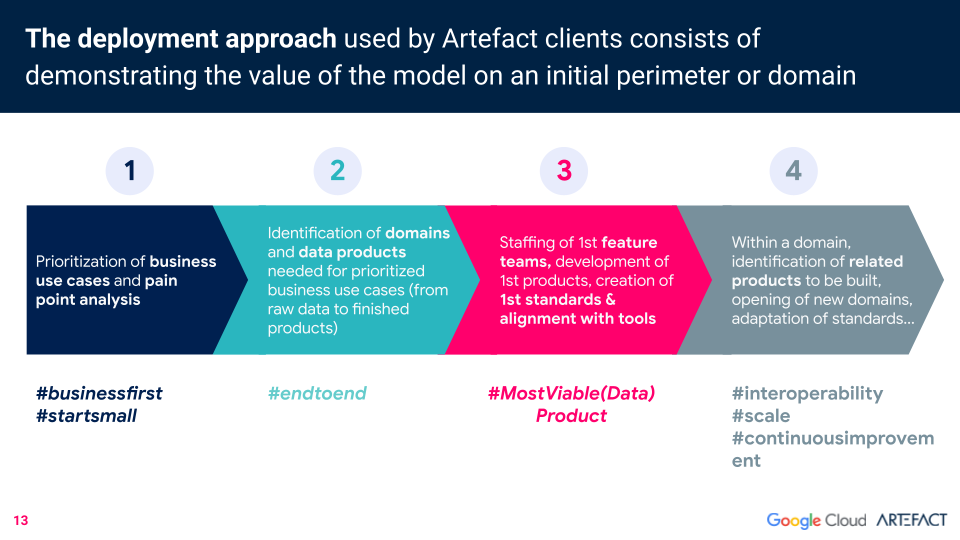
data 网格部署有三个先决条件。第一:打破孤岛。.
“基利安说:”如果 data 网要取得成功,我们就必须建立一种组织模式,打破 IT、data 和业务之间的孤岛,让平台团队由跨领域和跨产品团队组成,跨越所有实体“。”显然,这不会一蹴而就。但我们已经开始打破孤岛,将业务团队整合到 IT data 团队中,这样开发 data 产品的产品团队就能更高效地工作。”
第二个先决条件是 Data 产品负责人,他在协调 data 网格实施方面发挥着关键作用。data 产品负责人有三个使命:设计、构建和推广 data 产品。前两个任务不言自明,第三个任务同样重要,因为 data 产品的优势在于它被企业采纳和使用。“data 产品负责人的职责是确保 data 产品有据可查,用户可以理解和使用,并与业务需求保持一致。他成功的标准是他的关键绩效指标:使用率、技术性能、data 质量”,Killian 补充道。.
最后一个先决条件是,企业能够清晰、持续地定义其 data 领域,并且一旦该模式证明了其价值,就能够扩大其规模。.
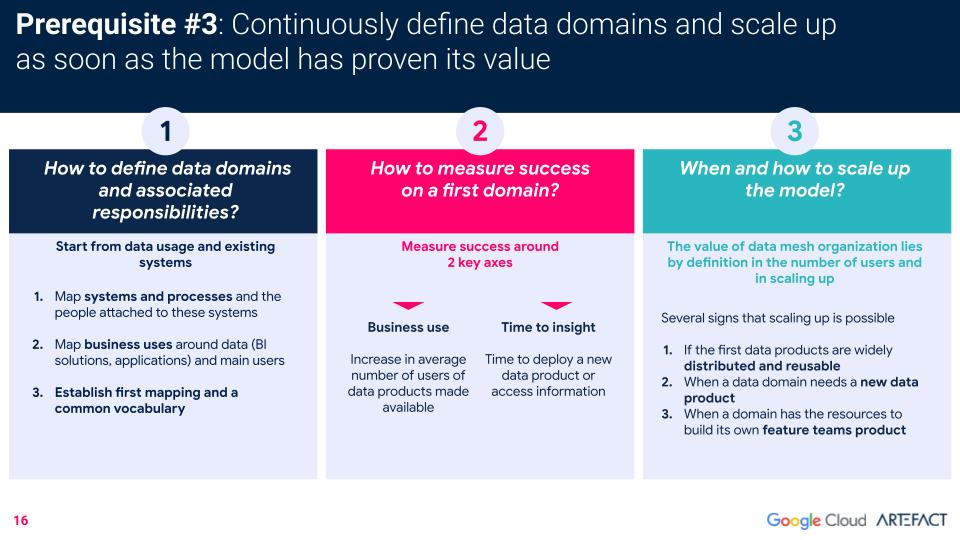
以上是实施 data 网格的客户最常问到的三个问题,以及 Artefact 关于成功定义域、衡量成功以及了解何时适合扩大规模的建议。.
技术堆栈:利用谷歌云管理 data 网格
“Amine Mohktari 说:”data 和 IT 团队要实施 data 网格,首先需要的是能够通过在 data 目录中发布 data 来实现其 data 的可发现性和可访问性。“为了实现这一目标,谷歌拥有第一个支柱--大查询,它可以创建可共享的 data集。第二大支柱,即目录本身,由分析枢纽(Analytics Hub)来实现,该枢纽为组织内不同成员或其合作伙伴创建的所有 datasets 创建链接,以便订阅者可以轻松访问它们”。”
“重要的是要明白,我们只制作 data 的链接,而不是副本。有了这个系统,用户就可以像使用自己的产品一样使用 data,即使它仍在原来的物理位置上。即使您将 data 存储在不同的 cloud 中,情况也是如此。.
用户体验是该系统的主要原则,体现在 data 网格的方方面面,它不仅促进了 data 共享和 data 合成,而且无论有多少用户在使用,data 都能保持永久可用。.
在 data 安全和治理方面,谷歌的智能 data 结构 Dataplex 可以帮助统一分布式 data,并在这些 data 之间自动进行 data 管理和治理,以支持大规模分析。阿明解释说:“Dataplex 与身份和访问管理(IAM)框架一起,为每个 data 消费者分配了唯一的身份,为公司提供了一套技术支柱,使他们能够以最简单的方式实施任何治理。.
“在谷歌云,我们的目标是为您提供无服务器 data platform,让您的 data 团队专注于流程和业务用例等领域,在这些领域,他们拥有别人无法产生的附加值。”
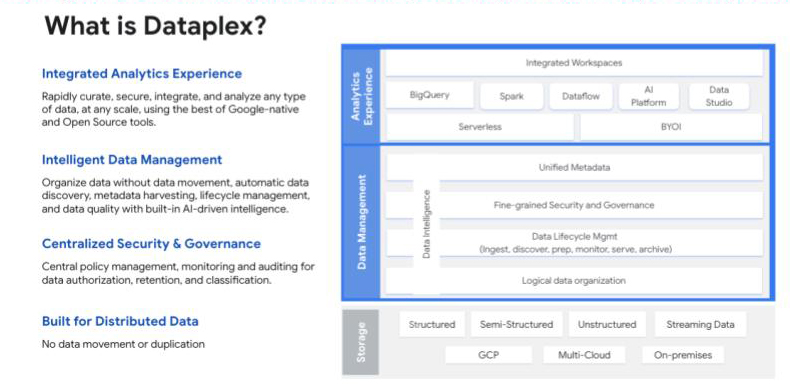
谷歌的 Dataplex 可让用户 360° 全方位了解已发布的 data 产品及其质量
结论:实施 data 网格时应避免的三个陷阱
不要 > 停留在项目愿景上,而不是产品愿景上
DO > 根据不同用途确定 data 产品的优先级;;
不要 > 过快推广新模式
DO > 用定义明确的运行模式测试模型;;
不要 > 部署过于复杂的技术生态系统
DO > 保持较小的技术堆栈,让尽可能多的玩家参与进来。.

